
無料から始める歌モノDTM(第22回)【調声編④歌声その3・ダイナミクス】

はじめに
はじめましての方ははじめまして。ご存知の方はいらっしゃいませ。ノートPCとフリー(無料)ツールで歌モノDTM曲を制作しております、
金田ひとみ
と申します。
【調声編】4回目です。
改めて基礎回を未読の方は、一読をオススメします。かなり長いですが、私の調声の方針になります↓
【調声編】全体の流れです↓
<歌声>:音声、音価・音高、トランジェント・アタック等について
<発音>:子音・母音、フォルマント、ピッチガチャ、ブレス等について
<抑揚>:ビブラート、コブシ、シャクリ、フォール等について
<効果>:エフェクター、ハモ等について
順番はDTMer/ボカロPに馴染みやすいであろう、DAWでの曲制作順に則っています。
以前の記事は最下部の「前の記事」から、またはマガジンとしてもまとめていますのでそちらからご参照ください。
今回は〈歌声〉のトランジェント・アタック等についてです。
と、いきなり人によっては聞いたこともない単語で戸惑うかもしれません。
アタックはまだしもトランジェントがちょっと聞き慣れない単語かと思います。
あと「等」と書いたように他にも出てきます。ディケイ、サスティン、リリースとか。
てか記事タイトルに「ダイナミクス」と書いてるのに内容違うやんみたいな。
それは私が使っているNEUTRINO調声支援ツール(調声ツール)には、トランジェント・アタック等に相当するパラメータだけを直接いじる機能が無いからです。
なのでダイナミクス調整機能と前回のピッチ、タイミング調整機能を駆使してこの謎の用語どもに対応していきます。
ちなみに新しいバージョンの初音ミクだと、事細かに調整できるパラメータがいくつもあります。

声質・声色に関するパラメータも充実しています。さすが便利ですね。
トランジェント・アタックといったそのままの名称ではありませんが、基本設定タブのVEL(ベロシティ)・DYN(ダイナミクス)、歌唱スタイルタブのディケイ・アクセント等で同様の効果が得られるのではないかと思います。
私は初音ミクをはじめボカロ系歌声ソフトを導入していないのでどの程度まで調声可能かは分かりませんが、各パラメータがどういった意味や効果を持っていて、NEUTRINO(AIシンガー系)でも応用できる共通点やそれぞれの系統が得意とする相違点もおよそ判別できるんじゃないかと思います。
パッと見ですが。
AIシンガー系、私が利用しているNEUTRINOだと、上掲初音ミクパラメータのBRE(ブレシネス)、Growl(グロウル)などは少々再現が難しいです。
声質・声色まで含めた調声の自由度はボカロ系に軍配が上がるかと。
(単純に有料無料、バージョンの差もあると思います。)
自由度が高いということは同時に、各発音ひとつひとつに対しての細かな調声をすべてやるのは大変かもしれません。ハシリやタメとまでいかないような人間っぽいナチュラルな発音タイミングのズレや、前後の流れよるピッチの揺らぎをどこまで再現できるのか。
一曲中に何百音もある歌詞の音すべてにパラメータを指定していくのは骨が折れそうです。
AI系はそのナチュラルさを自動生成してくれるので手直し程度で済むことが多いですが、そのぶん不得意な曲調や音域で強引に調声しようとするとかなり苦戦します。
両方の系統を使っている方に所感を伺ってみたいですね。
(気が向いたら自分でも導入するかも。気が向いたらね。)
どちら良い悪いというより、好みや表現したい作品の方向性にもよります。
前回の『RPG』(SEKAI NO OWARI)のようにケロケロボイスがピッタリな場合やパートだってありますから。
ただし気をつけておきたいのは、どんなソフトもツールも便利になればなるほど、なぜそうなるのか知ろうとしないまま使い方だけ覚えてしまって、あたかもマスターしたような気になってしまうのが怖いところ。
日本の家電や携帯電話がコモディティ化そしてガラパゴス化してしまったように、がんばって作った作品や覚えた技術がその時代その界隈でしか通用しないレガシィ(遺産)にならないよう意識はしておいたほうがいいかなと思います。
10年も経てば「あーそんなのあったなー」となって「今の若いもんは……」と言い始めてしまうかもしれません。
音楽は今までもそしてこれからも人類の歴史に残り、進化し続けるはずです。
まあ、私自身このnoteで汎世界的・音楽史的な広範囲を扱えるとは思えませんので、気に留めておく程度で良いと思います。
さて、それでは長くなってしまいましたが内容に移っていきましょう。
前回までが曲制作でいうところの「音源選び」と「ノート打ち込み」相当でしたので、今回はその打ち込んだノートに表情付けしていく「ベロシティ」や「アーティキュレーション」の一部に相当します。
音の大きさ
まずはざっくり「音の大きさ」について定義しておきます。
調声をDAWの曲制作に当てはめていくので、歌声の大きさ=ベロシティとして考えたいところですが、これまたピッチやタイミングと同じくやっかい。
ベロシティ
多分どのDAWでもノートを打ち込むとき、トラックごとに何らかの色分けがされていると思います。
初期設定のままという方もいるでしょうし、私のように視覚的にわかりやすいよう色指定をしている方もいらっしゃるでしょう。
私の場合、ベースやドラムなど低音域の楽器は暗めの色で、高音楽器は明るめ、シンバルやブラスなど甲高い音は黄色系なんてふうに分けています。若い女性の声を「黄色い声援」なんて表現したりしますし。
あとボーカルのメロディーラインはシンガーのイメージカラーに合わせたりしてます。
と、私の話は置いておいて、
DAWの初期設定ではノートのベロシティは100になっているかと思います。
ベロシティ
とは、本来「速度」の意味なんですが、DAWの打ち込みにおいては楽器を演奏する強さ、そしておおよそ「音の大きさ」として扱われています。
0〜127の範囲で調整します。
音源にもよりますが、数値が大きいほど音も強く大きくなります。
ベロシティ100は西洋音楽用語でいうところの「フォルテ(強く演奏する)」相当になるかと思います。
それより強いのが「フォルティシモ(とても強く)」、弱いほうで「メゾフォルテ(やや強く)」「メゾピアノ(やや弱く)」「ピアノ(弱く)」「ピアニシモ(とても弱く)」と続きます。
ちなみに楽器のピアノの由来は「弱くも強くも(=ピアノもフォルテも)出せる鍵盤楽器」という名前が省略されて「ピアノ」になってます。携帯電話をケータイと呼ぶみたいな。
私が使っているDAWのCakewalkでは、ベロシティはピアノロール下のMIDIイベントで確認できますし、ノートの色の濃さでもおおよそ判別できます。
MIDIイベントのノートの開始位置に対応する縦棒が、縦に長いほどベロシティも大きい。
ピアノロールではノートの色が明るいほど大きな音。
ちょうどよいツイートほじくり返しました↓
この竹林見るたび、打ち込みの醍醐味を感じる。#DTM pic.twitter.com/pRJ5AKWHlJ
— 金田ひとみ(2) (@Hitomi_Kanada) August 4, 2022
アコギのストローク。
去年の夏くらいの曲なんでだいぶ古いですが、細かいベロシティの変化を設けています。(下段のバー。タケノコor竹林って呼んでます(笑))
自動でギターストロークをやってくれる機能もありますが、結局お気に召さず手打ち修正することも……。
楽器音をすべてベロシティ100で打ち込むということは、いわばピアノの鍵盤やギターの弦を常に強く、しかもまったく同じ強さで演奏するようなものです。
現実的ではありませんし、ナチュラルでもありません。
たしかに歌声もフォルテで強く歌ったり、ピアノで弱く歌ったりとベロシティの概念を適用できそうですが、実は楽器よりさらに複雑に音の大きさが変化しています。
それは一つの発音の話だけではなく、その発音途中にも、また発音の長さや前後の繋がりによっても細かく変化します。
それが前回最後に挙げた画像、そして今回の主題の
ダイナミクス(音の強弱)
に関わってきます。
ダイナミクスとボリューム
用語解説が続きますがご容赦ください。
解説を進めるに当たって、
音の大きさとはそもそも何なのか
ということの確認しておきましょう。DTMをやっていると用語でつまづくことが多いですから。単に周波数の振幅だけを指すのではなくいろんな概念があります。
今回はそのうちの2つ、ダイナミクスとボリュームについて。
(他も音の大きさに関わる用語や概念はたくさんあるんですが、それは<効果>回までお待ちください。私も勉強中。それですらかる~く一つの記事になっちゃいそうだったんで。)
まずは今回の主題のダイナミクス。
単語から連想されるであろう、ダイナミック(動的な、力強く躍動する様子)の複数形名詞です。直訳だと「力学」や「挙動」となります。
音楽用語では、先の「フォルテ=強く」や「ピアノ=弱く」のような
音の強弱の変化のことです。
強弱の幅が広い=ダイナミックレンジ(幅)が適度に広いと躍動的で生き生きとした音に聴こえます。
楽器音源であってもノートを同じベロシティで打ち込むと何とも素人っぽい機械的な音になってしまうのは、音の強弱の差がちゃんと設けられていないからですね。
先の例のギターストロークのように、ピッチ・タイミング・デュレーションだけでなく、弦(ピッチ)ごと・ストロークごと・コードチェンジごとに細かくベロシティを設定することで、よりリアルな音に近づけることができます。
前回、ピッチをノートぴったりに揃えるとケロケロボイスになったり、タイミングを揃えると不自然な発音になったりする例を挙げましたが、ダイナミクスについてもあまりに揃え過ぎると機械的に聴こえます。
調声においてはこのダイナミクスを調整することで、よりナチュラルな歌声を再現していきます。
AIシンガーはそれを自動でやってくれます。シンガーと曲が合っていればホント手直し程度で済みます。ただし合わない曲だととことん合わない。
反対にボカロ系がどうしても機械音声っぽく聴こえる要因の一つは、ピッチ、タイミング、ダイナミクスすべてのナチュラルな変化を手動で調声するには限界があるからかもしれません。
もう一つがボリューム。
いわゆる音量ですが、もう少し細かい定義が必要です。
楽曲を聴く時にスピーカーやイヤホンのボリュームコントロールで操作しているのは楽曲全体の音量です。すべての音がすべての箇所で大きくなっています。ボーカルのサビ部分だけ大きく、なんてことは普通できません。
DAWで曲制作する時であればトラック毎にボリュームフェーダーがあって、ボーカルだけ大きく、ウワモノ楽器は小さくなどと音量を操作ができます。また、Aメロだけ小さく、サビは大きくなどある程度の時間の長さごとにも操作できます。それを最終的にひとつの楽曲にまとめていきます。
ボリュームフェーダーでの調整とベロシティでの調整は別ものと考えた方が良いです。音源によってはベロシティは単純に音量だけでなく、演奏の仕方のニュアンスごと変わる場合もあるのでそこは使い分けます。
フェードイン/フェードアウトしていくような場合はボリュームフェーダー、ニュアンスとして強く激しく/弱く優しく演奏する場合はベロシティといった感じ。
ダイナミックな曲は、各楽器やボーカルがそれぞれの見せ場で相対的にボリュームが大きくなって前面に登場しますし、激しいパートと静かなパートが飽きさせない良い感じで構成されています。ギターソロや落ちサビなんかですね。
相対的に大きくということなので、必ずしもフェーダーやベロシティで操作しているわけではなく、同時に鳴らす楽器数や音域の違いでそれぞれの見せ場を作ります。実際、私の場合フェーダーは曲の最後のフェードアウト用でマスタートラックでくらいしか使わない場合もあります。
先のダイナミクスとの違いは、ボリュームは切り取ったある瞬間それぞれの音量の大小を指すのに対し、ダイナミクスは時間的な音量の変化の差を示します。
ですので、もしすべてのボリュームが一定で変化が無いと、いくら大声でも小声でもダイナミクスが小さい(変化の差が乏しい)ということになります。
現実には生演奏の楽器音のボリュームを完璧に一定に保つことは不可能です。人間という生き物が演奏していますのでアナログなゆらぎが必ず生じます。
歌声の場合そのゆらぎは、一つ一つの発音においても、さらにはその発音中の数ミリ~数十ミリ秒の内にも細かく変化しています。DAWのフェーダーで調整できるようなものではありません。
歌声のボリューム=ベロシティ、と単純に相当させにくいのは、機械であるDAWのノートは基本的には指定したベロシティで打てば何度でも同じ音で再現できるのに対して、実際の歌声は同じ発音、同じボリュームで発声し始めたとしてもその時その時での細かい時間的変化が多彩だからです。それはランダマイズ(ランダムにする)とは違って、シンガーの個性や前後の発音の流れでも変わってきます。
なので不自然な発声を修正したり、よりナチュラルな発声をさせるにはダイナミクスの表情付け、つまりアーティキュレーションが必要になってきます。
その中でも今回は音量に関するものです。音量に関するアーティキュレーションは「強弱法」という分類ですが、そのまたさらに細かい部分まで突っ込みます。
アーティキュレーションの中でも、ピッチ(音高)をなめらかに繋げるスラーやレガート、ギター打ち込みで言うところのチョーキングやスライドは今回含みません。スタッカート(音を短く切る)やテヌート(音を十分に伸ばす)は少し関係しています。
楽曲全体の中での音量の変化、例えばメロは小さめでサビは大きめで、のような大きなまとまりでの変化はDAWのフェーダーでも操作できますので、調声ツール上では一つ一つの発音と単語~フレーズ程度の短い時間での変化を表情付けしていきます。
そしてその内の、一つの音のダイナミクスを分析する時に便利な概念、それがトランジェントやアタック等です。
T・ADSR
見出しタイトルからすでになんのこっちゃとなりそうな
T・ADSR
というアルファベットを登場させましたが、今回の解説で重要かつ便利な概念ですので、このアルファベットの説明から始めます。
相変わらず用語が続きますがここからが今回のメインです。
普通のDTM入門とかだとエフェクターでの音作りや仕上げのミックスについて勉強し始めた頃にやっと登場する概念です。
調声ってまあ、声の音作りやミックスなんで、この際ついでに触れておきましょう。
ADSR
まずは後半分のADSRについて解説していきます。こちらはDTMをある程度やったことのある方なら見たことあるかもしれない。
元はシンセサイザーの用語のようですが、電子音を扱う関係上DTMでも頻出概念です。
特にコンプレッサーなど、ダイナミクス系と呼ばれるエフェクターを使うときには知っておくと有効ですね。
各アルファベットはダイナミクスに関わる要素の頭文字になっています。
A……Attack(アタック)
D……Decay(ディケイ)
S……Sustain(サスティン)
R……Release(リリース)
です。
前回、ピッチやタイミングを揃えてみたように、今回は歌声のADSRをできるだけぴったり揃えて歌わせてみましょう。
歌詞は引き続き『風待ちダンドリオン』1番Aメロ「遠く眺めた景色は蜃気楼」の部分です。
ピッチとタイミングは自動生成された通りの無調声です。
(手持ちのツールで結構めんどうな処理をほどこしてやっとそれっぽいところまでで、厳密にはぴったりではないですが、ご容赦ください。)
※注意:耳が痛くなるのでボリュームを下げてから聴くことをオススメします!
前回のぴったりピッチやぴったりタイミングとまた違う、急に鳴り始めて急に終わる、歪んで割れたブザーのような声ですね。特に各発音の頭に当たる子音がヒドイ。(ついでにブレスもヒドイ。)
ちなみに波形はこんな感じ↓
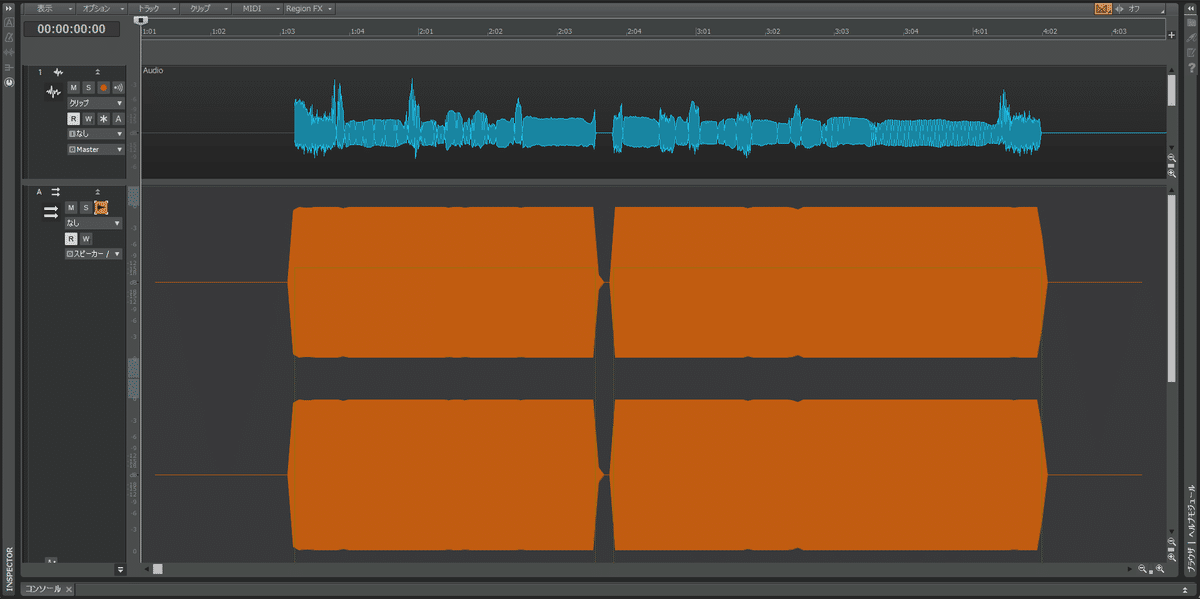
下のオレンジの波形?がエフェクターでさらに揃えたもの。
波形というより太い棒。
水色が1本、オレンジが2本あるのは、モノラル→ステレオの違い
なんでこんなヒドイ音になるかと言うと現実のナチュラルな音というのは、鳴り始めてから実際に音量が最大になって、そのあと減衰などの変化がありながら、音=振動が完全に消えてしまうまでに音量の時間的な変化、つまりダイナミクスがあるからです。
加えてこの例では、元々大きめ音を小さい音に合わせるために強引に揃えているので、歪んで割れた音になっています。
時間的な音量の変化の内、一つの音の
鳴り始めから最大音量になるまでをアタック、
安定した音量に落ち着くまでの減衰をディケイ、
安定的に持続して鳴り続けている間をサスティン、
鳴り終わって完全に消えるまでをリリース、
と分けて考えています。
上掲画像の同じ箇所の原曲の波形はこんな感じ↓
一つ一つの発音の中でも尖っていたりモコモコしていたりほぼ真横だったりと波がありますね。

ADSRとはその一つの音の音量変化を表したものです。
イメージ図にします。
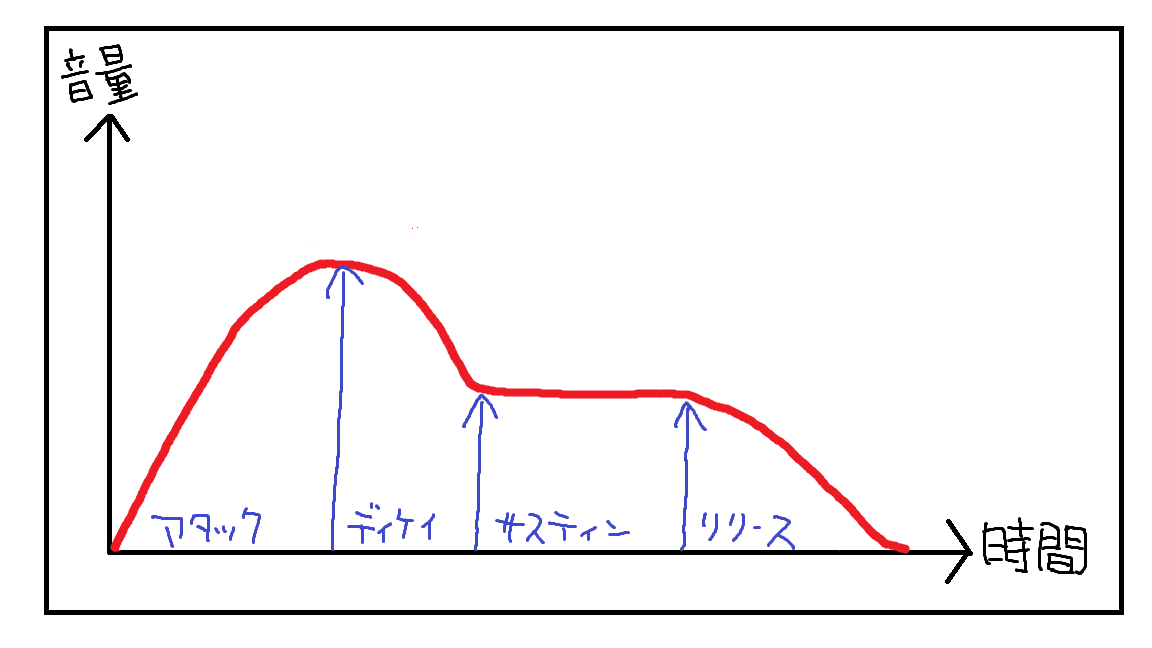
ある音一つを鳴らした時の音量の変化の例。
縦軸が音量、横軸が時間。
現実の音は手前の音声波形のようにこんなになめらかな曲線ではないです。
コンプレッサーの解説でよく見る図です。
この一つの音のダイナミクスの変化の線を
エンベロープ
と呼びます。
直訳で「包み」や「封筒」といった意味で、音楽用語では「包絡線(ほうらくせん)」とも言うらしいですがあまり見たことがありません。エンベロープで通じます。
コンプレッサーは「音の粒を揃える」といった表現がされることがありますが、要は音量の大きい部分=主にアタックを押さえつけ(compress=圧縮)て小さくすることで、サスティンなど他の部分を相対的に大きくしているわけです。
飛び出したアタック部分を粒と見なしてその飛び出し具合を適度に揃えるのがコンプレッサーです。その後全体の音量を上げて、埋もれたサスティンなどを相対的に大きくしたり他の音とのバランスを取ったりします。
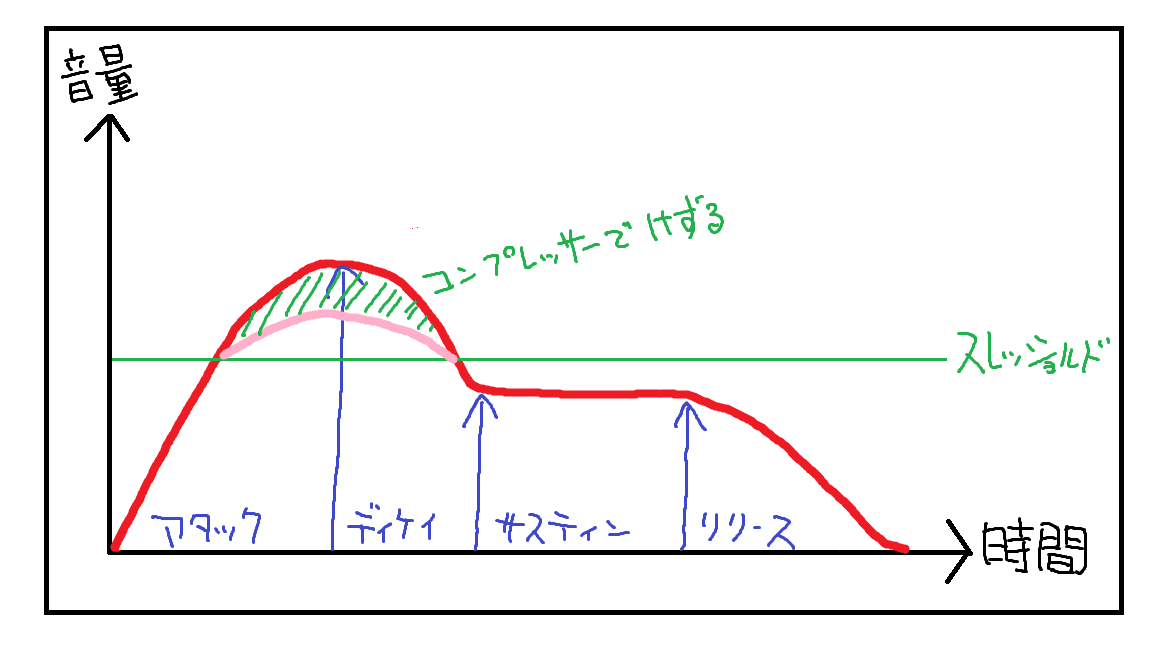

サスティンなどの音量を大きくできる。
パラメータのThreshold(スレッショルド)でどのくらいの音量でコンプレッサーが反応するかを指定し、Attack time(アタックタイム)やRelease time(リリースタイム)でその「押えつけ」の始まりと終わりのタイミングを決めます。Ratio(レシオ)がどのくらいの割合で押さえつけるかです。
コンプレッサーの種類や仕組みによってパラメータの名称や調節できる要素や程度は変わります。奥深い。
この詳細は【調声編】最後の<効果>の項目で扱うことになります。
なんでもかんでもコンプレッサーを掛ければ全体的な音量がしっかり聞こえて良い音になるわけではなくて、その音の特徴を踏まえた上で掛けないとチグハグなことになります。
ダイナミクスが無くなってしまったり、不自然な途切れ方をしたり。
先の歌声の例では、スレッショルドをがっつり下げて、最速アタックタイムと最遅リリースタイムで、レシオ限界まで押さえつけています。要はADSR関係なく全部圧縮してる状態。ダイナミクス系のエフェクターの中でも「リミッター」や「ブースター」「マキシマイザー」などと呼ばれる部類の重ね掛けです。
なのでヒドイ歪み具合。
つまりは、いずれ<効果>回でコンプレッサーなどについて触れるにしても、先に歌声のADSRの特徴を知っていないといけないということです。順番大事。
では歌声の特徴を見ていく前に、楽器音でもADSRの傾向は全然違いますので先にいくつか紹介しておきます。
まずわかりやすいのは打楽器。
アタックが早く強く、ディケイ以降は急激に減衰します。
その内シンバルやトライアングル、グロッケンなど金属製の楽器ほど長く鳴り続ける傾向があって、カスタネットやマリンバなど木製楽器や人間の手拍子はサスティン・リリースが短いです。振動の持続の違いです。

アナログな音のどこからどこまでをディケイ、サスティン、リリースとするかは
厳密には定義できません。
弦楽器のうちピアノやギターなど、弦を叩いたり弾いたりする楽器(打弦楽器、撥弦楽器)もアタックが早く強めですが打楽器より減衰はゆっくりでディケイ・サスティン・リリースが長い傾向があります。

楽器そのものもある程度大きく、共鳴する空間を設けているのでリリースが残りやすい。
いずれも響いている音のどこからどこまでをディケイ・サスティン・リリースのいずれと見做すか、デジタルなシンセサイザー用の定義をそのままアナログな楽器には適用できませんが、ざっくり「鳴り」「響き」や「共鳴」「残響」みたいなものだと考えられます。
(ピアノだと音を長く響かせるペダルのことを「サスティンペダル」と呼ぶので安定して弦が振動している間を一応サスティンに分類します。叩いたり弾いたりした直後の不安定な弦の揺れをディケイ、安定して持続する弦の揺れをサスティン、弦の振動が止まった後の楽器本体の箱鳴りをリリースと考えることもできます。)
弦楽器でも弦をこする楽器(擦弦楽器)のバイオリンなどストリングス類はサスティンが持続します。こすり続けている間はサスティンです。
こすり方のニュアンスによる音量等の変化で心地よいゆらぎが感じられます。
また少しずつ強く弾いていくといった演奏法も可能です。
(その場合、アタックの定義が難しくなります。普通は最大音量時をアタックと言うので。これまたアナログに適用しにくい。)

ストリングスは弦をこすり続けている間はサスティン。
機械的に空気を送り込むオルガンも、鍵盤を押している間はサスティンが持続します。ピアノと同じ鍵盤楽器にも分類されますが、音の鳴る仕組み上は次で紹介する管楽器と同じです。気鳴型鍵盤楽器と呼ばれます。
鍵盤から指を離せば空気の流れが止まってすぐさま音も止まります。パイプオルガンのように大きな筐体でない限りリリースは短めです。
空気で音を出しているにもかかわらずダイナミクスの変化が無いので「呼吸をしない怪物」と呼ばれてたこともあるみたい。

オルガンとピアノは見た目はよく似ているけれど仕組みが違うので音も違う。
ニュアンスを付けるには追加装置が必要。
機械的にではなく人力で空気を送り込む楽器ほど微妙なニュアンスを表現できるようになります。
アコーディオンなら腕力で、トランペットなどブラス楽器なら吹く息で、ハーモニカは吸う息も使って空気を送り込みます。

ピッチすら変えられる。
歌声も肺から空気を送って声帯を振動させ音を出すという点で考えるとブラス楽器などと似ています。さらに口唇や舌などで音色を変化させるという複雑なことをやってのけています。
トロンボーンやオーボエなんかは音色や音域的にも人間の声に近いと言われますね。
(ちなみに科学的・仕組み的に一番近いのはディジュリドゥ(別名イダキ)というオーストラリア先住民アボリジニの管楽器だそうです。ボゥェ〜みたいな音でいかにも民族楽器↓)
長々と楽器の例を挙げましたが、調声では歌声も楽器音と同じようなものと見なして、このADSRを調整していきます。
ただし人間の声はさらに複雑に変化します。
もし人間の声をベロシティ100で指定することができたとしても、ゆっくり穏やかに歌う人と元気よくハキハキ歌う人ではアタックのタイミングも最大音量も違いますし、それ以降のダイナミクスの変化の仕方も変わってきます。
また同じシンガーであっても各発音ごとの違い、前後の流れ、ピッチやタイミングでも変わってきます。
その変化の特徴が前回のめろうさんとセブンちゃんの比較画像です。
歌声のADSR

下の水色の波線がダイナミクス。
手描きの黒線で大まかになぞってあります。
人間の歌声はただ一つの音の大きさ、今回のたとえに相当するベロシティだけで指定することはできません。一つの発音のエンベロープの中にも全体の流れの中にも、細かなボリュームの変化、ダイナミクスがあります。
上画像では2人ともそれぞれの特徴がありますね。
めろうさん(左側)はどの発音も緩やかな変化、楽器で言えばストリングスなんかが近いでしょうか。「けー」の部分はオルガンのようなほぼ真横の動き。
比較的狭い範囲でボリュームが変化していますので、ダイナミクスレンジも狭め。
アタックが優しく自然なゆらぎで癒されるような歌い方である一方、単調で気だるい感じにもなり得ます。
セブンちゃん(右側)は激しく乱降下。各発音ごとに打楽器や撥弦楽器のようなアタックと、以降の大きな減衰があります。
全体的に見てもボリュームの大きな箇所と小さな箇所の差が激しい。ダイナミクスレンジが広いです。
癖が強く繊細な表現が難しい一方、生き生きとしたパワフルさが持ち味です。
当然得意な曲調が違って、めろうさんならバラードや優しいポップス、セブンちゃんならロックや激しいポップスなんかのほうが合います。
逆の曲調を歌わせようとするとかなり苦戦します。
めろうさんのほうを拡大してみます。

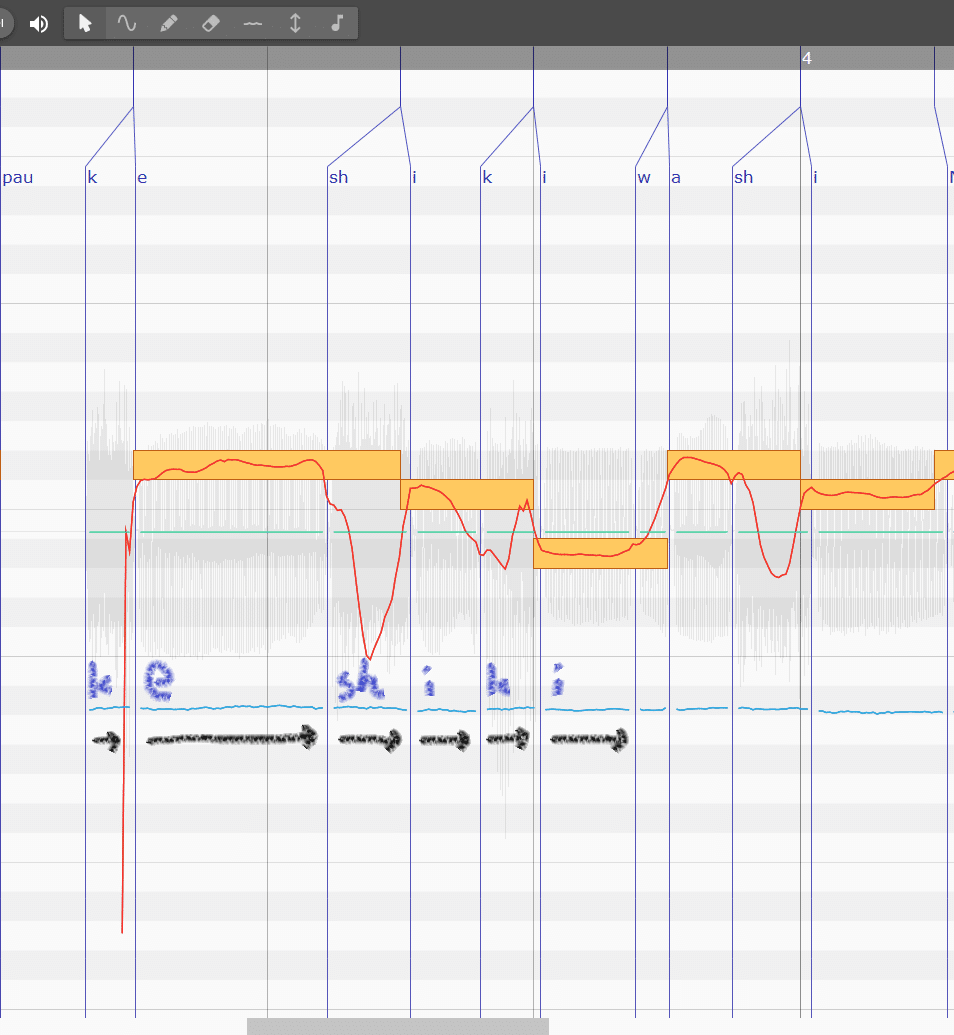
「けしき」の各子音、母音を青文字で示しました。
一つの発音に限って見ると、どの発音も相対的に子音が小さく、母音が大きくなっています。
[k]は小さく短く、[sh]はそれよりやや大きく長く、途中少し谷があります。長さの差は前回見たタイミングの差です。
母音のダイナミクスはめろうさんらしく、ほぼ一定の範囲内で推移しています。極端に大きくなったり小さくなったりしていません。「♪景色は」の「は(わ)」が少し大きい程度。
全体的にどの発音も後半は緩くボリュームが下がる傾向がありますが、同じ母音[i]でも2つ目は、子音の[k]の影響や次に来る「わ」の発音の影響で谷ができています。
リリースに当たる各発音の間隙は大抵一気に落ちます。特に[k]の発音前。
カ行を実際に発声してみるとわかるのですが、舌の先端より後ろから真ん中あたりを上あごにくっつけて、一瞬空気の流れを止めています。そのせいでガクンとボリュームが落ちるんですね。
ちなみに今回の最初に挙げたADSRをできる限り一定にした音量パツパツ歌声、要はダイナミクスを小さくした歌の調声ツール上の波形はこんな感じ↓
水色のダイナミクスをほぼ真横になるよう調声しています。(ちょーめんどくさかった。)
これにさらにコンプレッサーなどを重ね掛けしたのが、例の太いオレンジの棒のような波形です。
ひとつの発音の中でも子音は小さめ、母音は大きめになります。(ブレスはさらに小さいです。)
例の歌声はそらすらできる限りパツパツに揃えているので、なおさらヒドイ音声だったというわけです。
(外国語の場合、母音が無く子音だけの発音だったり、日本語でも語尾「です」「ます」の「す」のように母音が欠落した発音もありますので、<発音>回ではこれらも扱っていきます。)
そしてADSRとは別に考慮しないといけないのが、この子音と母音の違いです。
そこで今回、この違いに相当させる概念がトランジェントです。
T(トランジェント)
大見出しではTとしか書いていませんでしたが、
トランジェント
のことです。
トランジェントとは何かというと、アタックの瞬間に発生するピッチが不明瞭な一種のノイズです。
ドラムスで言えば太鼓の打面にスティックが当たる瞬間のバチッと鳴る音、
ギターで言えば弦にピックが当たる瞬間のペシッと鳴る音なんかです。
実際にチューニングや押弦で指定しているピッチとは別の、その楽器音をその楽器音らしくさせている瞬間的なノイズで、「音の輪郭」とも呼ばれています。
楽器の説明のところで出したADSRの図の左端、アタックの線を描いているので輪郭と呼ばれるようです。

ミックスで上手く使えば、楽器の距離感を出すのに有効です。
トランジェントを目立たせることですぐ近くで鳴っているような感じを出せますし、逆に適度に抑えることで離れた場所で鳴っているようにも調整できます。
ただし強すぎるとナチュラルな音とはかけ離れてバチバチうるさく聴こえたり、弱すぎると不明瞭でぼやけた音になってしまうこともあります。
強すぎるトランジェントはバチバチうるさいと言いましたが、これは最初の音量パツパツ歌声にも言えそうです。
それぞれの発音を構成する子音と母音のセットを一つの音として見た場合、
その子音部分をトランジェントと見なして考えると、歌声も楽器音と同じように取り扱いやすくなります。
(厳密には子音から母音に移行する「過渡部」と呼ばれる部分があります。子音と母音の間で一瞬谷ができている部分です。失語症に繋がるような脳の損傷があると、この部分を無音にした(子音と母音を切り離した)場合、「その発音である」と認識できないこともあるようです。健康な人でもこの過渡部の有無はその発音をその発音たらしめるのに一役買っているとのこと。ほんの数ミリ~数十ミリ秒の音を人間の脳は聴き取ったり、あるいは抜けていても補正する機能があるみたいです。人間すげえ。「子音 トランジェント」で検索すると下記機関の論文等出てきますので気になる方はどうぞ。いちおう科学的正確性保証のため。)
さて、トランジェントは音程が不明瞭と紹介しました。
「ド」の高さで歌うのに、「レ」なのか「ミ」なのかわからないような曖昧なピッチやそれらが合わさったような音で歌っている場合もあるということです。
もう一度めろうさんの「けしき」の画像に登場してもらいましょう。

子音ごと母音ごとでピッチ変化の幅を囲っています。
ピッチ変化の範囲を、子音はオレンジで、母音は紫で囲ってみました。
母音はおおよそピッチの範囲内、つまりノート上に収まっています。「し」の[i]で後半のピッチが緩やかに下がっている程度。人間っぽさやめろうさんらしさの癖の一つだと思われます。
子音はというと、前回からも見てきたようにピッチが激しくズレて変化しています。
実際にはノイズのように、ただズレているだけでなく複数の周波数が同時に鳴っていたりしますが、その子音に含まれる代表的なピッチを表示しているのではないかと思われます。
前回のピッチのズレの正体のひとつは確かに人間のアナログな側面もありますが、子音のトランジェント的な作用によるものでもあるとも言えそうです。
そう考えると子音のピッチは別にズレていたって良い、むしろズレているからこそナチュラルな発声になるということです。それら子音も母音もぴったりノートに合わせてしまうとケロケロボイスになります。
それではここからは、最初に挙げた音量パツパツ歌声にならない程度で、具体的にT・ADSRをいじっていきます。
ダイナミクスを調整してみる
一つ一つの発音のT・ADSRのTトランジェントを子音、ADSRをその発音全体と見なして、各部分のボリュームを調整してみます。
自動生成されたダイナミクスに本来とは違う変化を与えるとどうなるか検証してみましょう。。
アタック~サスティンを削ってみる
まずは母音の変化だけを検証してみるため、子音に当たるトランジェントの音量はそのまま、母音のアタック~サスティンに当たる部分を削ってみます。子音の終わりと母音の始まりの音量差を少なくして、アタックが各発音の後半で上がってくるように調声してみました。

水色のダイナミクスの波線も連動して削られています。
各発音ごとにフワッと声が大きくなるような不思議な歌声です。
発音自体は聴こえるっちゃ聴こえるのですが、ナチュラルな発声ではないですね。
エレクトリックな曲のシンセサイザーやストリングスでフワッと音が大きくなるエフェクトを掛けた時のような変化です。あるいはリバース(反転再生)させたような音。
自作品の『aNueNue』(東北きりたん)のバックで鳴らしているストリングスがそんな感じ↓
(ついでにこの曲のラストサビ付近(4:16~)のバックコーラス「Ole Ua 'Ole aNueNue」はケロケロボイスです。きりたんなのにきりたんじゃないみたいな声。)
楽器音ならエレクトリックな曲調で電子音っぽい雰囲気を出すのには一役買いますが、歌声の各発音ごとにやるのは不自然です。
「♪蜃気楼」の最後の「おー」と伸ばす部分で、あえて飛び道具的に使うくらいでしょうね。
サビに繋がるBメロの最後で盛り上げるためにフェイドインするような場合とか。でもそれならDAWのボリュームフェーダーでも良い気がします。
ディケイ~リリースを削ってみる
今度は逆にアタックは残しつつ、ディケイ~リリースに当たる部分を削ってみます。さっきとは逆です。

ハキハキというほどではないですが、発音が短く切られた感じになりました。ただし切れ方が消え入るようでやっぱり不自然。
セブンちゃんの同じ箇所でのダイナミクス変化と見比べてみると似たような傾向です↓

大まかな傾向は似ていますが、「けしき」の「き」の[i]のようにセブンちゃんであってもほぼ真横に推移している部分があるように、なんでもかんでもディケイ~リリースを削ればハキハキ元気になるというものでもないようです。
削り方も直線的に削ってしまうと不自然で、ADSRのSサスティンに当たる部分はある程度の音量で推移しないと、消え入るような発音になります。
曲のラストのロングトーンでフェードアウトするような場合には使えますが、それならこれもDAWのフェーダーで良いような気がします。
トランジェントを削ってみる
次は母音ではなく子音を削ってみます。
トランジェントに当たる子音部分を元の半分くらいのボリュームになるようにしてみました。

なんというか風をひいたときの鼻声みたいになりました。
子音は主に口腔(口唇、歯、舌)で音色を作っていますが鼻腔に抜ける空気も子音の構成に関わっていて、それを特徴付ける鼻腔音ごと抑えられて相対的に母音が大きく聴こえるために鼻声っぽくなってしまうようです。
医学用語だと閉鼻声というやつに近い。鼻に抜けるはずの空気の流れがさえぎられるため、子音がはっきりしないこもった声になります。
面白いですが使いどころは限られそうですね。ちょっとセクシーにも聴こえるので、ジャズやシャンソン歌手っぽく歌わせられるかもしれません。
トランジェントを大きくしてみる
反対に子音のボリュームを母音のアタック程度にまで上げてみます。
小さな子音だと一度では届かなかったの数段階ダイナミクス調整を掛けて調節しています。

※注意:耳が痛くなるのでボリュームを下げてから聴くことをオススメします!
明らかに耳に付くような痛い音ですね。グェッといった感じの人の声ではないようなひどい音が各発音の頭にあります。大き過ぎる子音は完全にノイズになります。
適度なノイズ感もありつつ、あくまでその発音を特徴づける程度のボリュームでないとダメなようです。
ここまでは一つの発音ごとの変化を見てきました。
それでは単語やフレーズなどある程度の時間の長さで見た場合はどうでしょうか。
めろうさんは差が少なかったので、セブンちゃんと並べて見ます。

各発音の最大音量時つまりアタック時のボリュームを青横線で、そのタイミングを下矢印で示しました。
並べた画像だと小さくて少し見づらいですが、
めろうさんは全体的に見た場合もダイナミクスレンジの幅が狭く、極端に大きくなったり小さくなったりはしない歌い方です。優しい。
見方を変えるとダイナミックさが無いので単語やフレーズをなぞるだけで単調になりがちです。
一方、セブンちゃんは差が大きいです。一つの発音中の変化だけでなく、単語やフレーズなどある程度の長さで見た場合も音量差が激しい。つまり歌い方自体ダイナミック。なので元気いっぱいな感じ。けれどうるさくもある。
すごく細かいアタックタイミングを見ると、
全体的に発音のアタックはめろうさんは遅め、セブンちゃんはかなり早め。擦弦楽器のバイオリンと撥弦楽器のギターのような差があります。
けれど「き」の発音に関してはめろうさんは前半部にアタック、セブンちゃんはほぼ真横ながら後半部にアタック。
セブンちゃんの場合、母音[i]の始まりのピッチもズレてる。(ちょっと音痴。)良くも悪くも「きィ!」っとややキツイ発音になる癖があります。

一つの発音だけでなく、単語やフレーズなどある程度の長さで見た時のダイナミクスレンジの差やアタックタイミングの差が、「優しい/単調な」歌声と「元気な/うるさい」歌声の差になっているようです。
どちらも得意不得意がありますので、基本的には得意なところを活かしてあげたほうが良いと思います。
が、今回の最後は、前回のピッチやタイミング調整との合わせ技を使って、めろうさんにセブンちゃんのような元気良さで歌ってもらえるか試してみましょう。
ピッチ、タイミング、ダイナミクス調整の合せ技
めろうさんとセブンちゃんはNEUTRINOオリジナルシンガーの中でも特に対照的な特徴を持つ2人です。
セブンちゃんの特徴や傾向をめろうさんが真似できれば、時に単調で気だるくなりがちなめろうさんの歌声も元気ハツラツになるかもしれません。
めろうさんにセブンちゃんの真似をしてもらう
そこで、めろうさんにセブンちゃんの歌い方の完コピをやってもらいます。
セブンちゃんの波形と見比べながら……と手動でやっても良いのですが、タイミングに関しては私が使い慣れているいるひと昔前のバージョンのNEUTRINO調声支援ツールでは生成前にしか調声できない仕様上、試聴ができません。
そこで裏技を使います。他のソフトやバージョンで可能かは分かりません(汗)
(NEUTRINO特有の操作ですので、あとはソフトに応じて試行錯誤してください。検索すれば出てきます。)
一旦セブンちゃんで生成した後、シンガーモデルを今度はめろうさんにして「タイミングを保持」チェックボックスをオンで再度生成し直すことで、めろうさんがセブンちゃんとまったく同じタイミングで発音してくれるようになります。
めろうさんにセブンちゃんが乗り移ったみたいな。NEUTRINOユーザー界隈でも、あるシンガーの歌い方のデータを利用して別のシンガーに歌わせることを「憑依」って呼んでるみたいです。
(私は某少年誌のウン十年前のマンガの技名から勝手にオーバーソウルって呼んでます。いや、憑依合体?(笑))
一旦試聴してみましょう。
前半が元のめろうさん、後半がタイミングオーバーソウル?後のめろうさん。

まあ、あんまり違いがわからないですね。
発音タイミングはどのシンガーでも極端には違いがありません。
前回見たように子音の長さには傾向がありますので、サ行がラ行より短くなったりといったことは起こらないです。
次にピッチですが、これは旧バージョン調声ツールだとどうも手動でやるしかない。いろいろ試したけどエンジニアリング的なことは得意じゃないもので。(設定ファイルの書き換え裏技などは自己責任でお願いします。)
画像的にも分かりやすいように、セブンちゃんで生成したときの波形と見比べながら似たようなピッチ波形に調声してみます。

前半は無調声めろうさん、後半タイミング+ピッチ真似。
ちょっとそれっぽい癖が入ってきましたね。
「景色」の「け」の入りの箇所のようにわかりやすくシャクリ癖が出ている部分と、「蜃気楼」の「ろ」の後半のように不自然なフォール部分があります。(上画像の青丸で囲んだところ。)
「景色」の「け」の子音[Sh](上画像の赤丸で囲んだところ)はピッチ波形は1オクターブ分くらい違うのにそこまで違和感を感じません。子音はトランジェントのようなノイズで、かつ音量が小さいためだと思われます。
そして最後、ダイナミクスも似たような波形に調声。

下の方の水色波線がセブンちゃんを真似たもの。青波線が元のめろうさん。
(緑波線が実際に動かしたダイナミクス調整の軌跡。)
画像で見ると、ピッチ調声時に特徴的だった「け」は、ピッチだけでなくダイナミクスも急激な変化があります。(紫のA→DSRがセブンちゃんの傾向。水色のA→DSRがめろうさんの傾向。)
不自然だった「ろ」は、セブンちゃんの場合、後半無音近くまでダイナミクスが落ちています。ほぼ真横に推移しているめろうさんの場合、後半のピッチがズレる部分まではっきり発声を伸ばしているので不自然に残って聴こえていたようです。
それでは、最終的に出来上がった歌を聞いていましょう。
同じく前半が無調声、後半がタイミング+ピッチ+ダイナミクスの完全真似。
手を加えていない無調声の歌よりはハキハキした感じになりましたね。
例の不自然だった「ろ」はセブンちゃんだと母音[o]の後半がほぼ無音なので、短く切るスタッカートっぽい歌い方です。
ただ、めろうさんはもともとの声質が落ち着いたお姉さんっぽい感じがある分、強引に真似した全体的な不自然さがあります。正直言うと、元気というよりはちょっと音痴……。「けしき」の「け」は癖が強すぎます。
結局のところ、それぞれの特徴を把握して真似することはできますが、やはり基本的にはそのシンガーに合った歌い方や曲調を活かして行く方向性のほうがナチュラルかなと思います。活かせる部分を少し参考にする程度が良いですね。
バイオリンをギターのようにジャカジャカ弾いちゃいけない。ピッツィカート奏法のようにアクセントで弦を弾く音を入れる、くらいの参考にしてください。
結び
結構長い記事になりました。お疲れ様でした。
今回で<音声>回は終了です。
<音声>回全体をまとめておきます。
まずは
音源選び=シンガー選び。
ボカロ系、AI系、有料無料と様々なソフトが溢れていますが、まずは好きなシンガーを見つけるところからです。
流行りで選んでも、使い勝手で選んでも、単純な好みで選んでも良いですが、ご自身の表現したい歌モノ曲を歌わせたい/歌ってもらいたいシンガーをパートナーにしてください。
それとあくまで歌声ソフトという前提です。
ピアノ音源でギター演奏はしないように、目的に合わせて音源=シンガーを選ぶのが最初です。
次に、
ノート打ち込み=ピッチとタイミング。
どんなに高性能な音源であってもどんなに声質の良い歌手であっても、ピッチとタイミングがズレていれば音痴です。
パートナーのシンガーはコンピュータです。「その音はちょっと高めのちょっと長めに……」みたいな、なんとなーくの指示では必ずしも上手くは歌ってくれません。
最低限「ドレミ……」や四分音符八分音符といった基礎的なことを知らないと、適切にノートを打ち込むことはできないようなものです。
シャクリやビブラートといった癖付けをする前に、歌声の基本的なピッチやタイミングの傾向を把握しておくことが大事です。
ただし歌声の場合あまりに正確に合わせてしまうと機械的になってしまいます。ナチュラルな発声にはノート通りではないズレがあります。
そして今回の、
トランジェントやアタックなど=ダイナミクス。
楽器音ごとにダイナミクスの特徴があるように、歌声にも特徴があります。
各発音ごとの特徴もありますし、単語やフレーズ程度の長さの中でも大きく変化したりしなかったり。
その変化の傾向が人間っぽいナチュラルさやそのシンガーらしさを特徴づけています。
他のシンガーを分析することでその特徴を真似することはできますが、基本的にはシンガーが元々持っている得意なところを活かしてあげた方が良い、と私は思います。
NEUTRINOは無料ゆえの操作の面倒さや機能の少なさはありますが、そのぶん複数のシンガーを気軽に扱えるので比較がしやすいです。
おそらく私の場合、ジャンルも曲調もシンガーも色んなパターンを試してきたので、自然とその違いや傾向が身に付いてきたのだと思います。
調声のレベルアップを目指すなら、自分が目標とする=コンセプトとする参考曲や歌声をいくつかピックアップしてみて、分析ツールなど活用しながらシンガー、タイミング、ピッチ、ダイナミクスの違いを真似してみてください。
作詞作曲と同じく、まずは何事も真似からですね。
次回予告
次回からは<発音>についてです。
今回まででも子音・母音は度々登場しましたが、<発音>回ではその詳細をさらに詳しく見ていくことになります。
「遠く」を「とく」、「蜃気楼」を「しんきろお」と入力しないとナチュラルにならない、といった話から入ります。
他には語尾の「です」「ます」の「す」の母音脱落や、外国語発音なども取り上げます。
今回までのタイミングやダイナミクスについての前提知識がないと扱えません。
それからNEUTRINOの裏技的な「ゴーストノート調声」と「ピッチガチャ」について。NEUTRINO特有の操作になりますので他の歌声ソフトで可能かはわかりませんが、最終的に似たようなことは可能かと思います。
発音そのものについてある程度理解が無いと、表面的な小手先テクニックの沼に落ちますので、次々回以降になるかと。
あとは正確には「発声」ではないけれど「ブレス」について。
発声は吐く息ですが、ブレスは吸う息で音を出しています。呼吸が無いとやはり機械っぽく感じる場合もあります。
効果的にブレスを入れることでよりナチュラルな調声ができるようになるかと思います。
思ってたより本業が落ち着かなくて遅れがちですが、頑張って続けていきます。(半分コンサルみたいな仕事なもんで、忙しくするために呼ばれたらガチで忙しくなってしまった。月100万赤字が100万黒字くらいに……。)
ではまた次回。
Thank you for reading!