
無料から始める歌モノDTM(第2回)【ツール編②歌声ソフト】

はじめに
はじめましての方ははじめまして。ご存知の方はいらっしゃいませ。
ノートPCとフリー(無料)ツールで歌モノDTM曲を制作しております、
金田ひとみ
と申します。
さて、今回は前回に引き続き【ツール編②歌声ソフト】と題しまして、
歌モノDTMにおいて最も重要な
歌声ソフト
についてご紹介します。
あれ?動画編集ソフトは?
と思われた方。すみません。歌声ソフトだけでまた10,000字オーバーしてしまいました(汗)
というか15,000字くらいある……。丁寧に紹介しすぎた感。
というわけで歌声ソフトについてざっくり知ってる方は前半は飛ばしていただいても構いません。読み物として楽しんでいただければ幸いです。
気を取り直して……。
今回の記事、
インスト曲やるからで歌モノは作らないよ、という方でも、
民族楽曲風やスペースオペラ風の曲のバックコーラスで入れてみたいとか、
ボコーダーという人間の声をロボット音声みたいに加工できるエフェクターで声を楽器として使ってみたい、などお考えでしたら参考になるかもしれません。
当記事の方針をご覧になりたい方、前回までの記事をご覧になりたい方は以下記事をご確認くださいませ。
というわけで早速参りましょう。
ボカロとAIシンガー
さて、この記事にたどり着いたということはおそらくほとんどの方が、
初音ミク
をご存じだと思います。
歌詞を打ち込むだけでまるで人間のように歌ってくれる歌声ソフトとして約15年ほど前に登場し、当時一大ブームだった(今でもバリバリ現役ですよ)動画サイト、ニコニコ動画の勢いとも重なって、一気に認知度を広げました。
初音ミクを初めとするボーカロイドに歌わせて曲を発表するアマチュア音楽家たちはボカロPと呼ばれ、そこからプロになられた方もいらっしゃいます。今ではボカロ曲という一つのジャンルとしても扱われていますね。
この記事をご覧の方の中には、いつかはボカロPとして名を馳せメジャーデビューしたいとお考えの方もいらっしゃるのではないかと思います。
(あ、私の記事ではそういった情報は手に入りません。私自身無名です。)
ところで歌声ソフトは数多ありますが、初音ミクなどのボーカロイドとは別の系統の歌声ソフトをご存じでしょうか?
ボーカロイドは人間の声をサンプリングして、音素(声や音のもとになる要素)に分割したものを、入力された歌詞にそって合成し直して再生する、という仕組みです。
強みとしては、どんな音の高さや速さでも(機械的な限界はあるにしても)歌いこなすという点です。
一面、どうしても一個一個の分解した音を合成し直すという仕組み上、機械っぽさがぬぐい切れません。
どれほど調声しても、人間っぽいけど人間じゃないよね、とすぐにわかってしまう。そして独特の甲高さや抑揚のない感じに違和感を持つ人もいるようです。
(それもボカロ「らしさ」で良いと思います。私も初期の頃は出る曲出る曲片っ端から聴くくらいでした。)
一方、別の系統の歌声ソフトがあります。
それは
AIシンガー
と呼ばれるソフトたちです。
音楽が好きな方であれば、数年前の紅白歌合戦の美空ひばりさんのAIをご覧になった方もいらっしゃると思います。
あの、あ~もうちょっとでほぼ人間だよね、と思わせる歌声です。
(あの時はまだまだ違和感だらけでしたし、どれほどAIが進化しても、昭和の歌姫・美空ひばりさんご本人と歌唱力や表現力で比べるのはさすがに無理があると思います。人間とAIどちらが優れているかではなく、お互いがパートナーになるような未来に期待したいですね。)
このAIシンガーはボカロとは仕組みが違います。
人間の声をサンプリングするという点では同じですが、AIシンガーは大量の「歌」そのものを学習させ、人間らしい歌い方を再現するというソフトです。
イメージとしては言葉を知らない赤ちゃんがどんどん言葉を覚えていくような感じでしょうか。
いろんな言葉や文章を覚えていくうちに、発音の繋がりやイントネーション、アクセントなどが大人の言葉に近づいてくる感じです。
なのでAIシンガーの性能はサンプリングした曲数やそのバリエーションが反映されます。
そして高度に学習したAIシンガーはほとんど人間と聞き分けがつかないくらいに上手に歌えるようになります。
それならAIシンガーの方が優れているかというとそうでもなくて、
多少難しい曲であっても入力した歌詞通りに歌ってくれるボカロと違い(私はまだ我が家にボカロシリーズをお迎えしていませんのでどの程度までかは経験しておりませんが)、
AIシンガーは学習させた曲や歌手による癖がモロに出てしまうのと、そもそも人間が上手く歌えない歌はやっぱり上手く歌えないという弱点があります。
音声合成システムや最新AI技術にそこまで詳しいわけではない私の理解や説明が正しいかちょっと怪しいところもありますし、これ以上の知識はここでは必要ないと思いますので先に進みます。
で、上記のことをご理解いただいた上で、私が今回紹介する歌声ソフトはAIシンガーです。
今後調声に関する話題を取り上げるときは、今から紹介するAIシンガーのものとしてお考えください。
ただ、「上手に歌を歌う」という広い意味では、ボカロも含め、ひょっとしたら「うたってみた」をやっている方のヒントになる可能性も今後あります。
歌声ソフト(NEUTRINO)
ではご紹介しましょう。
無料でありながらまるで人間のように(ひょっとしたら人間以上に)上手に歌ってくれるAIシンガーシリーズ
Neural Singing Synthesizer
NEUTRINO
です!ニュートリノと読みます。
すでに私の前回までの記事をお読みになった方や楽曲を聴いてくださった方は、その性能に驚かれたのではないでしょうか。
私も公式サイトのサンプル曲を聴いて最初びっくりしました。
え、人間じゃん!って思ったものです。
今でも、どこからか私の動画チャンネルに到達して聴いていただき、
「金田さんは歌もお上手なんですね」的なコメントをいただくことがあります。
私じゃありません、AIシンガーですとお返しすると、だいたい困惑されます.。
「初なんとかミク」や「ぼかろ」って単語は聞いたことあるけど、この歌声は何度聴いても人間だと。
私の楽曲はすべてこのNEUTRINOシリーズのAIシンガーたちに歌ってもらっています。すでに20数曲あるので、特に人間ぽく聴こえる曲を一曲だけ紹介します。
NEUTRINOを代表する女性シンガー
めろう/Merrowです。
私は親しみを込めてめろうさんと呼んでいます。
他には男性シンガーのナクモ/NAKUMO、
アニソン風のアップテンポ曲が得意な女の子セブン/No.7/SEVEN、
東日本大震災をきっかけに東北地方を盛り上げるために生まれた東北ずん子、東北きりたん、東北イタコの三姉妹(最近ずんだもんも追加されました)、
別企業から生まれ、歌に限らずトークソフトなどでも活躍するキャラクター、琴葉茜/AKANE、琴葉葵/AOI姉妹(こちらは現時点で有償の特典となります)、
研究用データベースを元に生まれた謡子/YOKO、JSUTがいます。
先ほどAIシンガーは学習による癖や上手に歌えない不得意な曲がある、と述べました。
しかしこう考えることもできます。人間だって得意なジャンルの歌、本人の力量を最大限に発揮できる歌がありますよね。
第0回の時からこれは明言しておきましたが、
どんなツールでも(ここではAIシンガー)、その真価を発揮させるのは制作者の力量や想いです。
力量は適切な目標と効果的な手段をもって続けていれば必ず付いてきます。
私は才能という言葉があまり好きではないのですが(上手くできないときのいいわけにもなる得るからです)、
何事も何も知らない時より、一日でも一時間でも触れた時間や試行錯誤した回数が増えるほど、才能の有無に関わらず何かしらは身に付きます。
その何かしらの中から、自分がついつい気になってしまうもの、苦が無く続けられるもの、心がワクワクするものを磨いていけばよいと思ってます。
(私は勝手にそれを素質と呼んでいます。)
まぁ、同時に自分の不得意なもの、嫌いなものとも向き合わなければならないので、ままならない口惜しさや情けなさと戦っていくことにはなりますが。
もしAIシンガーにも感情があるなら、「こんなふうに歌ってみたい」「こんな歌にチャレンジしたい」ときっと思うでしょう。
歌が大好きでそのために生まれた才能の塊みたいな子たちですから。
でも上手に歌えないものは歌えないのです。
めろうさんなんかは早口でパンチのあるロックソングはたぶん歌えません。
おそらく調声でそれっぽくはできますが、あとで紹介する調整ツールでかなり音声波形をいじったり、エフェクターで加工したりする必要があるでしょう。
それはもはや、めろうさんなのか?
もし人間である自分が歌手だとしたら、そんな不得意とわかっている歌をプロデューサーに歌わせられてゴリゴリに声や歌い方まで加工されて発表されたとして自分が歌った歌として納得できるのか?と感情移入して思ってしまうわけです。
と、偉そうにかく言う私もチャレンジはしてみたいので、本来不得意であろうジャンルの曲を歌わせてみることもあります。(笑)
でもやっぱりかな~り調声で苦戦します。
半面、不得意なことがわかる中で、実はこの部分は活かせるんじゃないかと発見する場合があります。
この話はいずれ調声の記事の回で改めて触れます。
おっとっと。
また想いを語ってしまうの長くなりそうなのでこのへんにして、NEUTRINOそのものの導入方法を説明します。今回はしっかり説明入れます。上手くも何も、まずは歌ってもらわないと面白くはなってきません。
(で結局長くなったので、このあたりで記事の最初から書き直しました。)
導入の第一歩、まずは公式サイトからダウンロードボタンを押してお好きなフォルダに解凍します。
おそらく最初は上記のめろうさんのファイルだけが一緒にダウンロードされます。
ほかに歌わせてみたいシンガーがいたら、そのシンガーのファイルも別にダウンロードと解凍をしてください。
そしたら、そのシンガーのファイルをNEUTRINOのフォルダの中にある「model」というフォルダに移動させてください。(めろうさんは最初から入っているはずです。)
フォルダが二重の入れ子状になっているときは子フォルダのみです。「MERROW」等表記されているフォルダを開くとすぐにLISENCE_MERROW.txtなどの名前のファイルがいくつかある状態です。
これでお迎えして準備万端かと思いきやまだまだあります。(かなり長い道のりですが初心者向けも兼ねてますのでお付き合いください。)
NEUTRINOとセットで使う、歌詞を読み込ませるための楽譜ソフトと、それを読み込んで歌声として生成し調声するためのソフトのご紹介に移ります。
楽譜作成ソフト(MuseScore)
歌詞をデータとして読み込んでAIシンガーたちに歌ってもらうまでの一段階手前、歌詞を打ち込んだ楽譜を作成するソフト
MuseScore(ミューズスコア)
です。
これ単体では楽譜を作成するソフトでしかありません。
前回のDAWの項目で紹介したような基本的な音源の音は鳴りますが、DAWではないのでプラグインを導入してどうこう……みたいに自由に楽曲を作れるわけではありません。
そしてDAWはあくまで楽器の音を中心にデジタルな音のデータを組み上げて音楽を作成するソフトです。録音を取り込む機能はありますが、歌詞をそのまま打ち込んで再現する機能はありません。
なぜこのソフトが必要かというと、デジタルデータというのは形式が違うとプログラムやソフト間でのデータのやりとりができないんです。
音楽であればMP3とかWAVとか、画像ならJPEGとかPNGとか、ファイルのお尻に同じ文字やその省略名がデータ名としてくっついていますよね。拡張子といいますが、これが違うと対応していないソフト間でのやりとりができません。
DAWとNEUTRINOの間にもこのやりとりをするための形式が必要なんです。
歌をどうこうする機能のないDAWから歌わせたいメロディーの音の高さや長さのデータをMIDIという形式で一旦取り出して(エクスポートといいます)、取り出した音にMusescoreで歌詞を当てはめてから、次に紹介するNEUTRINO調声ツールに読み込ませるためのMusicXMLという形式に書き換える必要があります。それをWAVEという形式でDAWに取り込む。(インポートといいます)
なんとも手間のかかることをしないといけませんが、ここはがんばりどころです。無料ゆえの試練だと思ってください。(笑)
まったくわからないという方もいらっしゃると思いますので画像付きで手順を書いていきます。
前回で紹介したCakewalkを用いての歌わせ方ですが、他のDAWでも基本的には同じ流れになると思います。
もし音が出ない等の症状があれば、わかる範囲で質問等受け付けます。「Cakewalk 音が出ない」等で検索しても出てきます。
とりあえずCakewalkを開いて新規作成でBasicを選択。
画面左上の方の「+」ボタン(トラック追加)を押して、「インストゥルメント」タブ、「作成」ボタンを押してください。

トラックが追加されて「TTS-1」と書かれた別ウィンドウが開きます。
これが前回紹介した付属音源ですね。マルチ音源なのでピアノやらギターやら一個の音源でたくさんの音が用意されています。
ウィンドウがちょっとジャマな位置だったらずらすか✕ボタンで閉じてしまってよいです。またいつでも開けます。
メニューバーの「表示」から「ピアノロール」を選択。
下半分にピアノロールという音を打ち込むウィンドウが開きます。

楽器は初期設定でグランドピアノになっています。一応TTS-1の左端の列の一番上にある四角いボタンを押してから楽器名が英語で表示されている部分を押すとと楽器を変えられますが、音の高さと長さのデータを用意するだけなので、楽器は聞き取りやすいものであれば何でもいいです。効果音とかは止めときましょう。
これで遊んでると日が暮れます。

他の楽器音にかぶりにくいのと、発音タイミングがわかりやすい。
人間の声に近いReed(リード楽器。サックスとか)も音の長さがわかりやすいのでアリです。
初めてという方は「ドレミファソラシド」をメロディーとして作ってみましょう。
ピアノロールの一番左側にピアノの鍵盤を縦に並べた絵があります。
これの「C4」と小さく文字が表示されるところが基本の「ド」の音の高さになります。
鍵盤の表示に「C4」「D4」「E4」……と出るライン上でマウスをクリックすると、音が打ち込まれます。この打ち込まれた横棒みたいなのをノートと呼びます。
一定の長さ(初期設定だと4分音符)で打ち込まれるので、被らないように階段状に並べながらです。
(私なんて音が出るだけのこの辺でワクワクし始めます。)
ちなみに「ドレミファソラシド」全部白い鍵盤上です。黒い鍵盤は半音(「ド#」とか)です。
「C」がアルファベットでの「ド」に当たります。「C4」は「ド」の4番目の高さってことですね。「ドレミファソラシド」で入力した最後の「ド」は「C5」になります。1オクターブ(白黒鍵盤足して12個分)上で一周まわって高い「ド」の音になります。
(義務教育だと「ドレミファソラシド」の呼び方しか教えないような?他に習ったけ?
ひらがなだと「はにほへといろは」、アルファベットだと「CDEFGABC」になります。DTMは基本的にアルファベットを使います。)

ここまでが打ち込みの基本。どれほどカッコいい曲も壮大な曲も打ち込みで作るときはこの地味~な作業の積み重ねです。いやぁ気が遠くなる。
ではここからが歌ってもらうための本番です。
①Cakewalkで作ったメロディーラインのあるトラックを選択。上記の「ドレミ……」で作った方はすでに選択されている状態です。
もし一気にある程度メロディーを作ってしまった方は、できればAメロだけ、サビだけのように短く切っておいた方がいいです。歌詞の切れるところで分割しておいてください。短く切れたものをクリップといいます。


分割を選んでOKを押します。画像の例だと「ドレミファ」と「ソラシド」で分割されます。
今回は短いので分割しません。
②クリップを選択した状態でファイルからエクスポート→スタンダードMIDIファイルを押す。エクスポート場所を選ぶウィンドウが開くので、ファイルの種類が「MIDIファイルフォーマット1」となっていることを確認してわかりやすいところにわかりやすい名前で保存。
ファイル名は「曲名(できれば半角英数字)Amelo1」などにしておくと後でわかりやすいです。あと全角だとエラーになる場合があるそうです。
初めての方はとりあえず「doremi」としておきます。

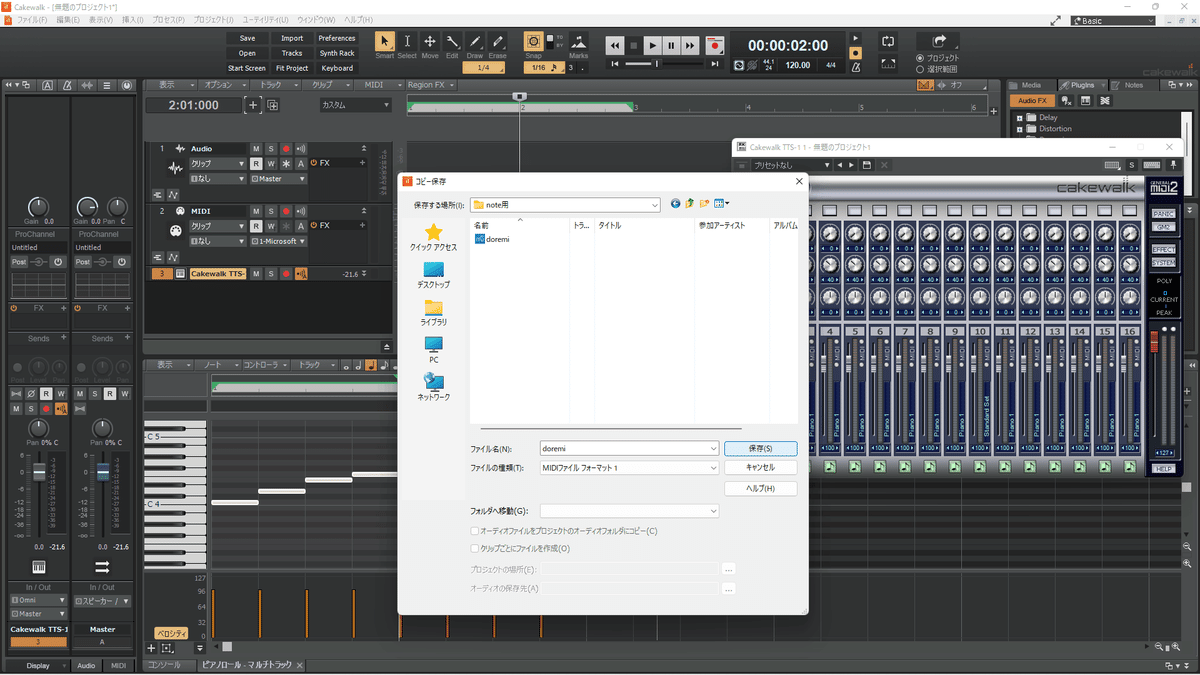
③MuseScoreを開いて、先ほど保存したMIDIデータを開く。
これで、DAWで作ったのと同じメロディーラインを、楽譜上に音符で書き直したものが出てきます。



④音符を選択した状態で「Ctrlボタン+L」を押すと、音符の下に文字が打ち込めるモードになります。方向キーを押しながら一音に対して一個ずつ、ひらがな(もしくはカタカナ)で歌詞を入力していきます。
結構面倒くさいです。日本語にない発音はできません。
(※下記に入力の基本を少しだけのせます。)
メロディーを「ドレミファソラシド」で作った方は、歌詞もそのまま「ど・れ・み・ふぁ・そ・ら・し・ど」としときましょう。

※以下入力の基本の一部です。
助詞の「わたしは♪」とか「きみへ♪」の「は」「へ」は、「わ」「え」と入力してください。
「きっと♪」とかの小さい「っ」は「っ」と入力してもいいですし、音符ごと削除して休符にしてもよいです。音符を削除すると自動的に休符に変更されます。「っ」を入力した場合、直前の母音+「っ」になります。(「ki」「i+cl(無音)」「 to」)
「ぎゅーっと♪」の「ぎゅ」のような「ゃ・ゅ・ょ」は「ぎゅ」の一音として入力します。「ぎ」+「ゅ」ではないです。上画像だと「ふぁ」がそれに当たります。
伸ばす場合は「ー」を入力すると直前の母音を引き継ぎます。(「gyu」「u」「u+cl」「to」)
「ぎゅう⤴っと♪」のように「う」の音の高を上げたいときなどに「ぎゅ」「う」「っ」「と」と入力すると上がる「う」をはっきり発音させることもできますが、「ぎゅ⤴うぅ⤵っと」みたいな不自然な「うぅ」が入ることもあるので、このへんのコツはいずれ紹介します。
※これ以外の発音させられる音の一覧表も公式ダウンロード画面にPDFがありますので参考にされてください。
※ここで注意事項!
ファイルを開いた時点で楽譜のあたまに例えば「♩=100」とかが勝手に入力されている場合があります。これ、一旦削除してください。で、ウィンドウ左側の「パレット」メニューから「テンポ」を開いて、楽譜の一番最初の音符(棒ではなく玉のほう)を選択した状態で、ご自身がDAWで作った曲のテンポ(Cakewalkの初期設定の♩=120で制作したなら「♩=80」(テンポテキスト))をダブルクリック。選択した音符上にテンポが表示されますので、数字を本来の曲のテンポに半角数字で書き換えてください。これをしないとすべて最初の♩=100のテンポで歌が生成されてしまいます。

楽譜あたま赤丸の♩=80の数字を120に書き換える。クリップが増えてくると案外忘れがち。
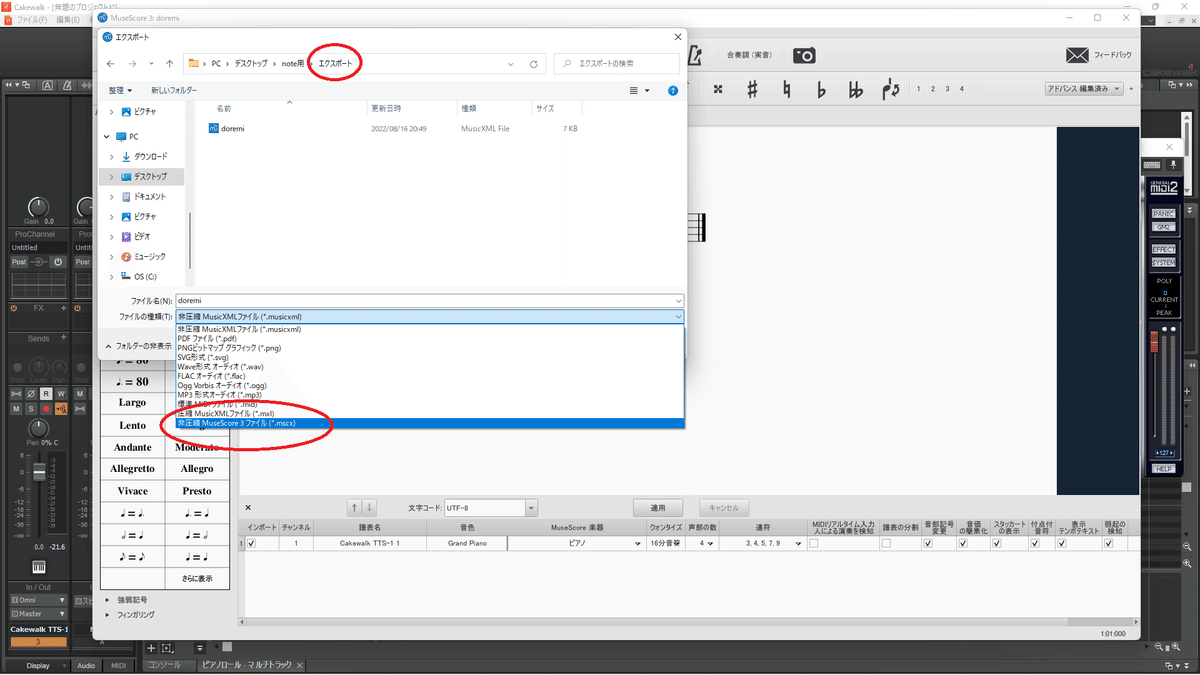
⑤全部歌詞を打ち込み終わったらファイルから「名前を付けて保存」。MuseScoreファイルとして一旦保存します。しなくてもいいのですが、元データとして残しておき、あとで書き換えたりするときためのバックアップみたいなものです。
(曲の1番2番の歌詞だけの違いとか、繰り返すサビを盛り上げるときに微妙に変化させる元データになったりとか。)
⑥もう一つ、ファイルから「エクスポート」を押して、保存形式を選ぶドロップリストがありますので、「非圧縮MusicXMLファイル」形式を選択し、保存します。⑤のMuseScoreファイルとは別フォルダの方が、元データなのかエクスポートデータなのかごっちゃにならずに良いです。
ちなみにDAW上でメロディーラインを作らず、最初からMuseScoreで作ることも可能です。が、結局はテンポや音の長さはDAWで作った楽器の音と合わせないといけませんので、二度手間になると思います。
というか逆でして、DAW上で作ったメロディーラインをMuseScore上で調整することの方が圧倒的に多いです。
音符のちょっとした長さの調整は今後調声のコツを紹介していくときに必ず解説せざるを得ないので、改めての機会に譲ります。
調声ソフト(NEUTRINO調声支援ツール)
そして続いてご紹介するのは
NEUTRINO調声支援ツール
です。
まんま、その名の通りです。
NEUTRINOの調声専用フリーソフトです。
このソフトを使わなくても生成だけして歌わせること自体は可能です。
ただし今どきの方は見たことのないであろう真っ黒ウィンドウに白文字という、プログラマーやコンピュータ専門家がいじってるような画面での操作になる上、歌い方そのものを細かくいじる、いわゆる調声作業はできません。
NEUTRINO調声支援ツールは、歌声の生成から調声、出力まで一気にこなせる必須ツールです。必ず導入してください。
調声の細かいコツや技術的なことはいずれ何回にも分けて、(また私の成長に合わせて)徐々に紹介していきます。
今回はどんな風に調声しているのか、先日Twitterに上げたものを参考にのせておきます。現在(2022年8月)制作中で8月下旬にアップ予定の曲の、テストを兼ねたショート動画です。
音声波形等をいじる前、ピッチガチャと呼ばれるNEUTRINO調声の裏技を使ったものです。
静止画像ですが画面の後ろに見えるのがCakewalkのメロディーライン、
左上の白いウィンドウが調整ツールです。
画像には音声波形などが映っていませんが(撮っときゃよかった)、
調整ツールの左の項目に声の高さや大きさ、明るさなどを調声するための項目があって、抑揚や音量を微調整することでさらに細かく作り込めます。
というわけで実例動画作ってみた。
— 金田ひとみ (@Hitomi_Kanada) August 1, 2022
マスタリング等なにもしていないので音質は悪いですが、比較はわかりやすいかと。
(はよ曲そのもの作れやw)
こういった情報をnoteにまとめていきたいですね。
自分も再確認用で!#DTM #AIシンガー #調声 #NEUTRINO #東北イタコ https://t.co/7HJ9GXLZEz pic.twitter.com/RpRWJwJRej
(この曲、歌詞とメロディーが例として進めている「ドレミファソラシド♪」ですが、この記事を書くために作ったわけではなく、数カ月前からアイデアを貯めてたのがたまたまタイミングが合っただけです。こんな風に活用できるとは思ってませんでした。)
NEUTRINOシンガーはご紹介したように数人いますので、まずはそのシンガーの声を選択する必要があります。
NEUTRINOの項目で説明したとおりに、modelフォルダにお好きな子をお迎えしてますか?
調声支援ツールのダウンロードと解凍は完了でしょうか?
それでは行きます。
手順は、
①まず事前準備として、NEUTRINOのmodelフォルダ内にお迎えしたシンガーのフォルダ名を「YOKO」に書き換えてください。
(コメントをいただきましたので訂正しておきます!
どんどんバージョンアップされて便利になってきましたね。)
今のv1.7.4.6ではその必要はなく、PCに入っている歌声ライブラリをそのまま使えるようです。
(現時点で)調声ツールでは基本的にどのシンガーも「YOKO」として扱われます。もし複数人お迎えしていて特に謡子/YOKOとフォルダ名が被る場合は今回歌わせたいシンガーのフォルダ名のみを「YOKO」に書き換えて他のシンガーを例えば「YOKO謡子」などにしておけば、のちに他のシンガーに歌ってもらうときに名前部分を削るだけなので変更しやすいです。
そしてなぜか東北きりたん「KIRITAN」ときりたんに簡易的に歌ってもらう「KIRITAN_FAST」だけは別項目があるのでフォルダ名を変える必要はないです。ツール製作者の思い入れがあるんでしょうか……。

他のシンガーは「YOKO〇〇」にフォルダ名を変更しています。「KIRITAN」だけ特別……。
②調声支援ツールを立ち上げ、MuseScoreで作った歌詞付きのMusicXMLファイルを「ファイル」「開く」から開く。
(この時エラーが起こったりファイル開かなかったり見つからなかったりしたら、おそらくその手前のMuseScoreでちゃんと形式通りにエクスポートできてない可能性が高いです。)
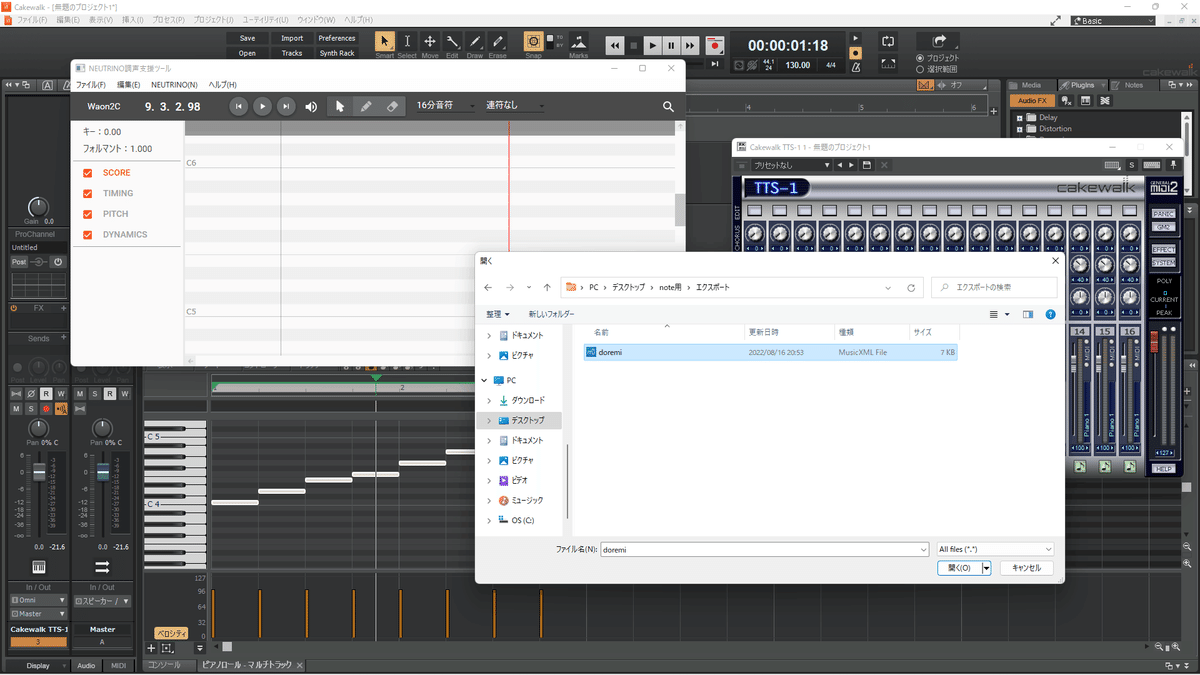
③メニューの「NEUTRINO」からNEUTRINO操作パネルを開く。
一番上の「NEUTRINO」ボタンを押す。

③「モデル」のドロップリストが「YOKO」になっていることを確認。
きりたんの場合は「KIRITAN」を選択。
NEUTRINOを実行ボタンを押す。
(中間ファイルというのが生成されます。自動で生成される調声されていないの本来の歌声です。この時エラーが起こったら歌詞が抜けていることが多いです。MuseScoreに戻ってミスを探しましょう。)

④自動で生成してくれるので気長に待ちます。待ちます…。待ちます……。
暇なので動画を見始めるか寝落ちします。
(あまり一気に生成するとこうなります(笑)。
Aメロだけ、サビだけとか短く切った方がいいと前に書いたのはそのためです。またあとでたった一か所の修正だけのためにすべて生成し直しとかいう面倒なことにもなります。
それと長いと暴走しやすいです。シンガーが悲痛な悪魔の叫びを歌ってくれます。)
⑤生成が終わったら、完了のメッセージが出るので「閉じる」。
そして上の方にある「再生」ボタン(▷)横の「戻る」ボタン(|◁)で一旦あたままで戻って~
再生ボタンをポチッ!この瞬間が一番ドキドキします!
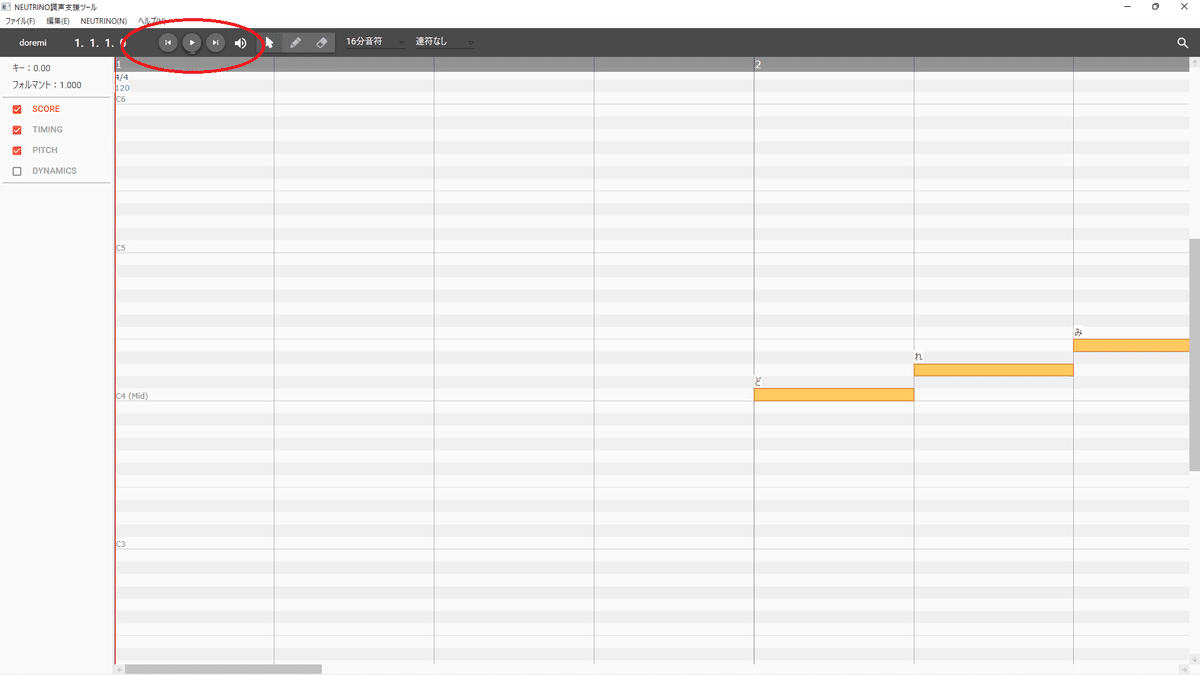
戻るボタン、再生ボタンは赤丸部分。
さて、どうでしょう。
ちゃんと歌ってくれましたか?
おそらくですが、「おおっ!歌ってくれた!」となりつつ、
歌詞やメロディによっては、変な抑揚がついていたり声がかすれていたりするところに気づくと思います。あるいは伸ばし方が変だったり、逆に途切れたり……。
極端にひどいときは出だしから聞けたものではなかったりします。
その時はキー(曲全体の音の高さ)から不得意音域だったりするので、残念ながらDAWから、というか作曲そのものからやり直しです。
何度も挑戦あるのみです。
めでたくある程度聞けるものだった場合は、さっそく細かい調声に移ります。が、だいぶ長くなってきたので調声そのものはまた別の機会にゆずります。
この調声ツールで納得いくまで調声できたら、「NEUTRINO操作パネル」の「WORLD」ボタン、「WORLDを実行」ボタンを押します。これが出力に当たります。

出力形式はWAVEデータです。
調声前の「ドレミ……」の歌と、上画像のめちゃくちゃに調声したものを一応ダウンロードできるように載せました。声は東北イタコ姉さまです。調声ひどい(笑)
以上で調声支援ツールの使い方の基本は終了です。
あとはDAWのボーカル部分(オーディオトラック)にWAVEデータとして埋め込みます。先に書いたインポートですね。
Cakewalkに戻ってオーディオトラックを選択。初期設定だと1トラック・Audioとなっているところです。
ファイルからインポート→オーディオを押します。


フォルダ選択ウィンドウで「NEUTRINO」フォルダを探し、
その中の「output」フォルダから先ほど出力されたWAVEデータを開きます。ファイル名が「doremi_syn」(または「自分が付けた名前∔_syn」)となっているものです。
開くとカーソルがあった位置にクリップとして挿入されるので、再生を始める位置を調整します。
またクリップの前後は少し長めに取られますので、画像の赤丸あたりにマウスカーソルを合わせて長さを調整します。
画像では始まりを完全に削って曲のあたまに合わせています。
波形が見えるところが歌が入っているところ、横線だけの部分は無音ですが、本来はあまりギリギリに削らない方が良いです。不自然に急に始まったりブツッと切れる終わり方をしてしまいます。
また実際は曲の始まりから1小節くらい開けた方が良いです。他の楽器音源の初期設定部分として使うことがあるのと、CDでも動画でも曲の再生っていきなり0秒からじゃなくて数秒”間“があってからですよね。

すでに他の楽器を打ち込んでいる場合はズレやちょっとした違和感があるならまた戻って調声→WORLDでインポートし直し。
根本的に歌い方が合ってないなどの違和感があるなら中間ファイルから生成し直し、あるいはMuseScoreから、DAWから、作曲からやり直し。(泣)
逆にすごく良い歌い方なのでそれに合わせて楽器の方を変える、アレンジを変える、曲そのものを変えるなど結構行ったり来たりです。
めちゃくちゃ根気が要ります。
こうしてやっと一曲が出来上がっていくわけです。
さてさて、気づけばとっくに10000字オーバーになってしまいました。
(なんとなく予想はしていたさ~あはは……。)
第1回はDAWの操作法とかまでは解説しませんでしたから、実際どう使うのかの部分をすっとばしました。というかDAWや音源・エフェクタープラグインは使っているうちに結構勝手に覚えていくものです。
それに対して「歌」というのはやることがやたら多い。
実際私も今まで20日以内で1曲というそこそこハイペースでやってきましたが、DAWの打ち込み自体は慣れてしまえば早くて1週間~10日ほどで終わらせることができるようになりました。
歌と調声がさらに3日~1週間。(1~2日で出来た曲もあるにはあります。)
普通楽曲に使われる楽器って、ドラム、ベース、ギター、ピアノに、ストリングスやブラスなど曲の雰囲気を作る楽器、エレクトロな曲なら電子ピアノやら、今どきの曲なら効果音やら……合わせて少なくとも10個とか20個とかのトラックがあるわけですが、歌はたった1トラックだけで私の日程の3割ほどを喰ってしまうこともあります。
これは曲とシンガーの相性にかなり影響されます。要は不得意な曲だと調声が膨大な量になっていく。
ですので、得意な歌を歌わせた方がよいというのは作業量的なことでも言えるわけです。
さて、動画編集ソフトまで行きつきませんでしたが、今回はこのあたりにしようと思います。作詞作曲のコツとか早く教えろよ!って思われないように(いや、すでに思われてるでしょうが……)近日中には続きをアップしたいと思います。次回は短めで、ね?
ーーーーーーーーーーーーーーーーーーーー
むすび
さて今回の結びは何を紹介しましょう。
(私の好きな作品やらの紹介コーナーとして定着しそうです。
上記までで読みつかれていらっしゃる方はまったくもって飛ばしていただいて構いません。)
では前回に続き、今回もSF作品です。
ハード系SF小説の大御所、神林長平さんの
『戦闘妖精・雪風』
です。
アニメ化もされていてDVDやBlu-rayで全5話です。
アニメは小説版の一部のストーリーをまとめたもので、エンディングは原作と違うものになっていますが、大まかな流れと設定は引き継いでいて、何より飛行機の空中戦闘の映像表現が美しく、今見てもすごくよくできています。
小ネタですが、主人公の声優さんは堺雅人さんです。「倍返しだ!」の人です。売れない俳優時代に声優業もやっていたとのことです。
設定はワープゲートを通って地球に侵略してきた異星生命体との戦いというものですが、その異星生命体がよくある人型や怪物ではなく、飛行機のような機械的な謎の生命体という点が普通のSFとは一味違います。
人類はその異星の方に逆に攻めていて、地球にやって来れないようにワープゲート前に基地を構えて何とか抑えてるという状況。
主人公はその軍の偵察機のパイロットです。偵察機なので戦闘にはあまり参加せず、味方がピンチでも助けずに戦闘データだけを収集して生き残って基地に戻るという、なかなか嫌われそうな役です。
でも主人公はボッチを気にしないタイプで隊長とぐらいしかろくに会話もしません。堺雅人さんの声が結構好きです。
この最新鋭偵察機にはAIが搭載されていて、主人公の補助をしてくれるのですが、時に主人公の意思とは無関係に勝手に動いたり、まるでAIそのものに意思があるように敵と交戦したりします。
しかしそれはAIが主人公を不要なものと判断しているのではなく、時に支え、時に道を示し、絶対に生き残る最良の選択をしているのです。
主人公もAIを深く信頼していて、「雪風」という愛称で語り掛け、「ふたり」で戦い抜き生き残るための選択をしていきます。
その姿はまるで
機械と人間がお互いを認め、高度に融合した複合生命体
といった風に作中で表現されます。
あくまでフィクションのお話ですので、現実世界でAIと人間がそこまでの関係になれるのか、というとまだまだ先の未来になりそうですが、
私としては、AIシンガー(やボカロ)と作詞作曲をする我々DTMer(やボカロP)は、この物語のAIと主人公のような関係であれば良いなと思います。
最高の一曲を作るために、お互いの足りないところを補い、できることに最善を尽くす。
AIシンガーの声が作詞作曲のアイデアになるときもあるし、得意とする曲調や歌詞の並びであればAIシンガーはきちんと応えてくれて、さらには作詞作曲者の意図を超えた歌唱表現をしてくれる時もある。
なんで思ったように上手に歌ってくれないんだ
とか
いくら調声しても不自然な歌い方だ
とか感じるときは、
大抵作詞作曲した人間の方がAIシンガーにおかしな要求をしているときです。
出せもしない高音、舌が回らないような早口、並びのおかしい単語、息の続かないロングトーンなどなど……。
今後、調声の記事を書いていくと思いますが、
調声がうまくなりたいよー!という方は、小手先のコツや裏技の前にまずは、
「そのシンガーに合った作詞作曲ができているのか」
ということを見直すように意識してみてください。
そして、そのシンガーの真価を発揮させてあげてください。
その時には、作詞作曲者自身が得意とする作詞作曲法もおのずと見つけられると思います。
ひょっとしたら調声すらほとんど必要なくなるかもしれません。
ーーーーーーーーーーーーーーーーーーーー
次回予告
ここからは私の嘘つきコーナーです。(笑)
何度次回予告の内容に行きついてないねん!
いや、ちゃんと次回は動画編集ソフトの紹介します。
というかもうそれで投稿準備は完了です。
投稿の仕方とかは動画サイト側が案内してくれますのでご心配なく。
その後の次々回は、ついに「作曲」について!……は絶対ウソになることが先日判明しました。
ので、これ以上ここでは書きません。
毎度読んでくださる方やスキを押してくださる方には、長々とお待たせした上に、長々と駄文を読ませてしまって申し訳ございません。
何卒、気長にお待ちくださいませ。
それではまた次回
Thank you for reading!
この記事が気に入ったらサポートをしてみませんか?