
Amazon Bedrockをアプリと繋げてみる ~ AWS環境の作成 ~

前回は「Amazon Bedrockをアプリと繋げてみる ~ ローカル開発用フロントエンドの作成 ~」ということで、ローカル開発用のフロントエンドの作成をし、ローカル環境(一部AWS)で動作確認が出来るところまでをやってみました。
本記事では全てのリソースをAWSに作成し、AWS上で動く環境を作成し、Bedrockからの回答を画面に反映するところまでをやっていきます。
構成
構成としては以下の形です。
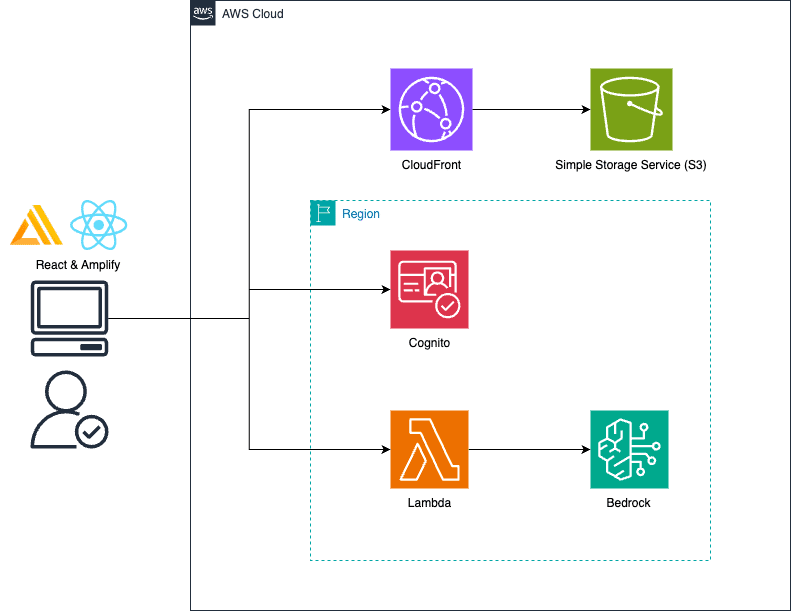
ローカル環境との違いは、フロントエンドの資材がローカルではなく、CloudFront & S3から取得するという点になります。
今回は、Route53、ACMなどを使って自ドメインを利用することはせずに、CloudFrontのドメインを利用します。
CDKのポイント
新たにS3をオリジンとした静的Webサイトの配信用のCloudFrontを作成し、フロントエンドの資材をユーザーに提供できるようにします。この構成はAWSではよく利用されるSPAや静的サイトの構成になります。
今回はCDKで作ると言う点でポイントになる部分を見てみます。
ローカル環境とAWS環境用のスタックの切り替え
ローカル環境でも作成したCDKのコードは、AWS環境でも利用したいところです。そのためローカル環境用のスタックとAWS環境用のスタックを切り替えられるようにします。
bin配下の実行ファイルで、以下のようにしておくと、実行するスタックをコマンドで指定することが出来るようになります。
const app = new cdk.App()
const region = app.node.tryGetContext('region')
// ローカル環境用のスタックを作成
const localBedrockSampleStack = new LocalBedrockSampleStack(app, 'LocalBedrockSampleStack', {
env: { account: process.env.CDK_DEFAULT_ACCOUNT, region },
})
// AWS環境用のスタックを作成
const awsBedrockSampleStack = new AwsBedrockSampleStack(app, 'AwsBedrockSampleStack', {
env: { account: process.env.CDK_DEFAULT_ACCOUNT, region },
}# AWS環境用のスタックの実行
cdk deploy AwsBedrockSampleStack
# ローカル環境用のスタックの実行
cdk deploy LocalBedrockSampleStackこういった形で簡単に切り替えることができます。また、package.jsonのscriptにcdk:productionなどの形で設定しておくのもよいでしょう。
スタック別のリソース
今回はフロントエンドの資材の配信用のCloudFront & S3がAWS環境だけ必要になるため、そこを追加するだけになります。
以下はAWS用のスタックのコードですが、新たにフロントエンドのリソース作成のコンストラクトを作って呼び出すようにしています。
const region = this.region
const account = this.account
const namePrefix = 'bedrock-sample-aws'
// 認証周りのリソースを作成
const auth = new Auth(this, 'auth', {
namePrefix,
})
// API周りのリソースを作成
const api = new Api(this, 'api', {
namePrefix,
region,
idPool: auth.idPool,
})
// フロントエンドのリソースを作成
const front = new Front(this, 'front', {
namePrefix,
account,
frontEnv: {
region,
userPoolClientId: auth.client.userPoolClientId,
userPoolId: auth.userPool.userPoolId,
identityPoolId: auth.idPool.identityPoolId,
predictStreamFunctionArn: api.predictStreamFunction.functionArn,
},
}また、各リソースで名称を設定しているため、それらも環境別で指定ができるようにnamePrefixを渡すようにしています。
各環境ごとのファイルやコードなどの管理
前述までで今回のデモ用のコードについては終わりですが、実際には、細かな設定値などをローカル環境、検証環境、本番環境などで変更したいかと思います。
私としては、CDKのファイル構成や環境変数などのやり方などは、まだまだ検討中ですが、今のところは以下の動画が参考になりました。
スタックの分割でも環境ごとや、デプロイの頻度や、組織の部署ごとなど、さまざまな分け方が考えられます。システムや組織に、どういった特性があるのかを見極め、適切なCDKの構築になるようにしたいところです。
また、環境変数については、cdk.jsonで管理するのが良さそうですが、dotenvを利用するという方法も考えられます。状況に応じて使い分けられれば良いかなと思います。
フロントエンドの動作確認
CloudFrontのドメインを利用して、ブラウザでアクセスをします。
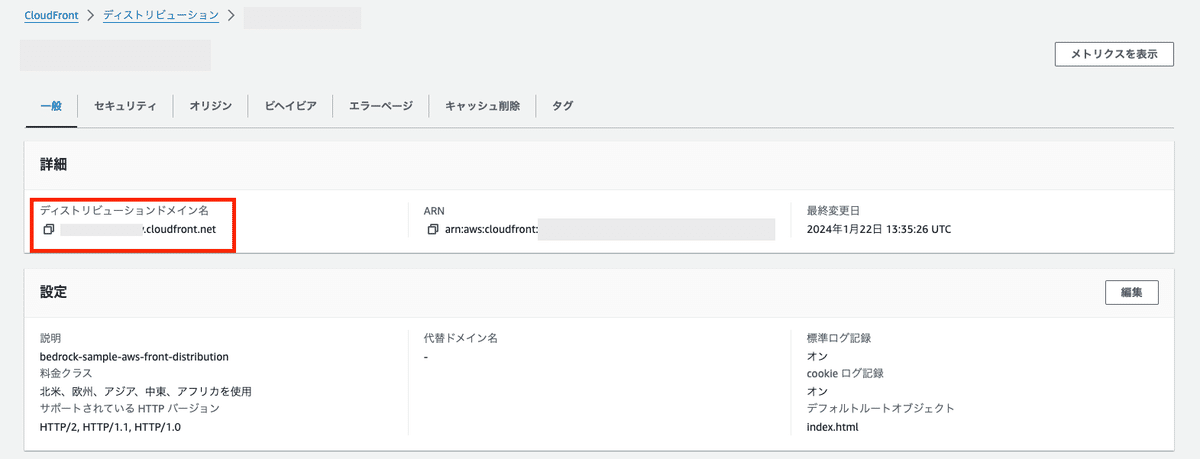
CDKの出力でも出力ができますし、AWSコンソールでは以下で確認ができます。
ディストリビューションドメイン名の前にhttps://をつければ、ブラウザでアクセスができるURLになります。
あとは、前回のローカル環境のフロントエンドの記事と同じように、Amplify UIの認証画面が表示されるので、アカウント登録などを行い、ログインし適当な質問を投げてみます。

AWS環境でも同じようにBedrockからの回答が返ってきたことが確認できました。
まとめ
今回はAWS上でアプリの動作環境を作成し、実際にBedrockからの回答を画面に反映するところまでをやってみました。
実際のアプリなどでは、データベースに登録したり、細やかなユーザーの権限制御、UI/UXへの考慮、そしてBedrockへのプロンプト制御など、さまざまなことを行わなくてはいけないため、難しくはなってきますが、比較的に簡単に生成AIを利用することが出来ることがわかったかと思います。
ChatGPTでも実現はできますが、今のところはコスト的にはBedrockの方が安価になりそうなので、検討の候補としては上がってくるかなと思います。モデルについても、Claude以外も利用可能なので色々探ってみるというのも良いのではないでしょうか。
今までのソースの完全版は以下で確認ができます。