AWSの生成AIサービスBedrockを使ってRAGをやってみる

BedrockでRAGが使えるようになりました
RAG(検索拡張生成)とは、生成AIが学習してない情報、例えば企業内のクローズドな情報などを与えたうえで、検索や回答を求める手法です。
Bedrockでは、「Knowledge base」という機能によってRAGを実現できるようになりました。
さっそくKnowledge baseの設定をしてみたいと思います。
いくつか前提条件があるので注意してください。
前提
1. Bedrockの初期設定が済んでいて、Claudeが使えること
2. Knowledge baseのモデルとして「Titan Embeddings G1」を
使いますので、有効化します。
Bedrockの初期設定
初期設定を行いAnthropic社のClaudeを使えるようにします。
初期設定が済んでない方は、こちらの記事が参考になります。
モデルの有効化
「Titan Embeddings G1」を有効化します。
※バージニアリージョンを使います
Bedrock > 左メニュー > 「モデルアクセス」をクリック
「モデルアクセスを管理」 > Titan Embeddings G1にチェックを入れ、最下段の「変更を保存」をクリックします。

Titan Embeddings G1が利用できるようになりました。

Knowledge baseの設定
前提条件をクリアしたら、以下の工程ですすめていきます。
1. S3バケットの用意
2. データのアップロード
3. Knowledge baseの作成
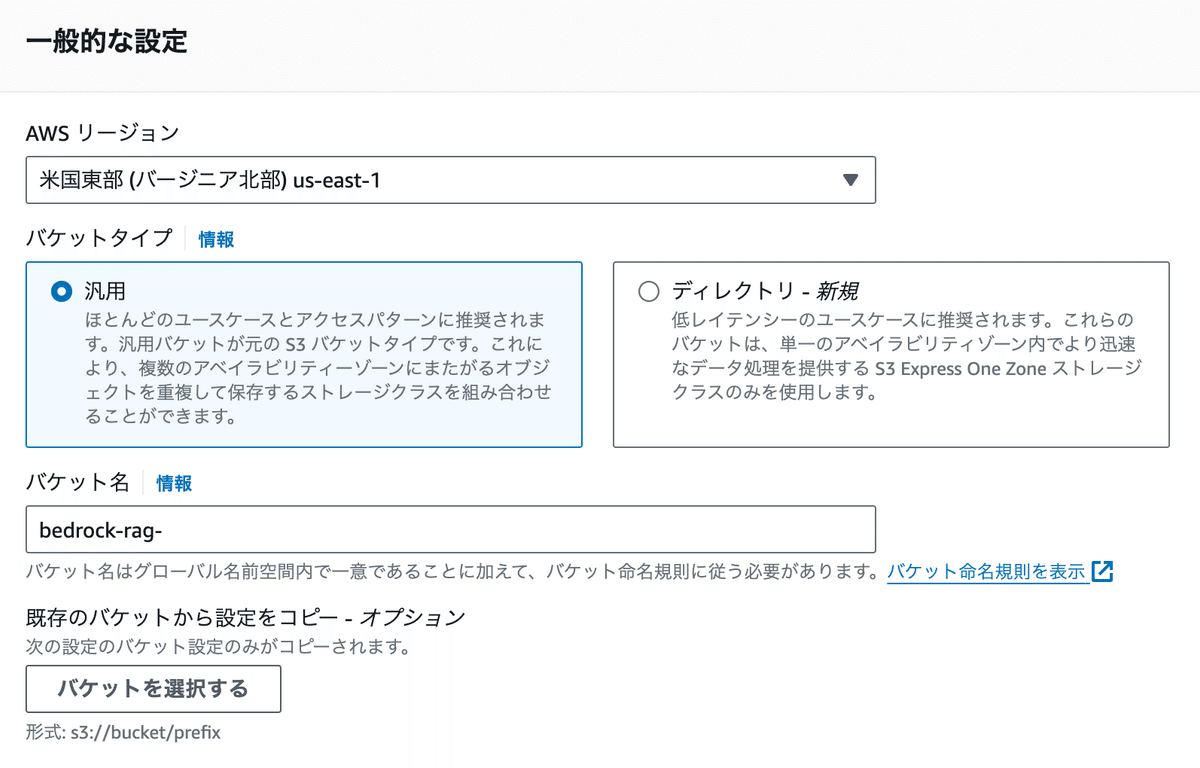
S3バケットの用意
生成AIが情報取得するためのデータソース保管場所を用意します。
バージニアリージョンにS3バケットを作成します。
データのアップロード
生成AIが取得する情報データを用意しS3バケットにアップします。
データは各自用意しましょう。
筆者は、こちらの厚生労働省が公開している「モデル就業規則」をS3バケットにアップしました。
Knowledge baseの設定
Knowledge baseの設定をしていきます。
※バージニアリージョンを使います
Bedrock 左メニュー > 「ナレッジベース」をクリック

「ナレッジベースを作成」をクリックします。
設定画面が開きますので、各項目の設定をしていきます。
ナレッジベース名:適宜入力
ナレッジベースの説明:空欄
ランタイムロール:「新しいサービスロールを作成して使用」にチェック
サービスロール名:適宜入力
「次へ」

データソース名:適宜入力
S3のURI:前項で作成したS3バケットを指定
「次へ」

埋め込みモデル:「Titan Embeddings G1」を選択します。

ベクトルデータベースの選択:デフォルトのままにします。
「新しいベクトルストア」をクイック作成を選択。
(これによりOpenSearch Serverlessのコレクションが出来上がります。)
「次へ」

最終確認画面が出ますので、最下段の「ナレッジベースを作成」をクリックします。
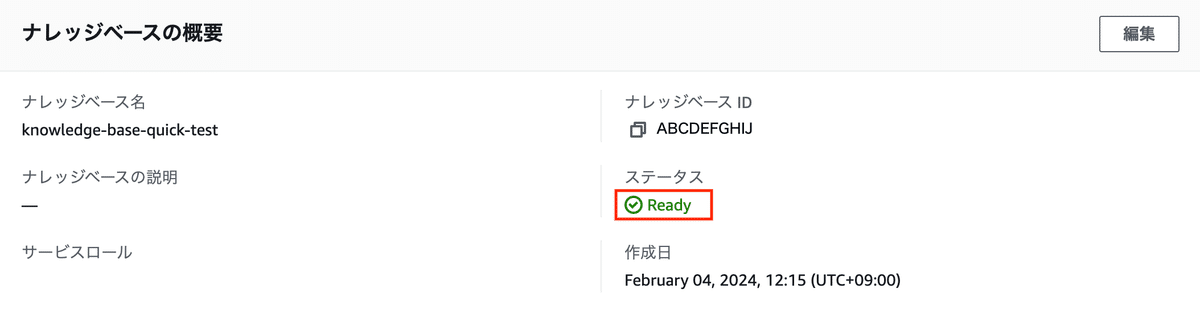
数分待つとナレッジベースが出来上がります。
ステータスが「Ready」になれば完成です。
データソースの同期
まだこのままではRAGの動作確認ができません。データソースと同期する必要があります。
データソース欄の「同期」をクリックします。
※データ量によりますが、筆者の場合1分程度で同期完了しました。

試してみる
準備ができましたのでRAGを試してみましょう。
画面上部の「テスト」をクリックします。

モデルはClaude v2.1を選択します。
プロンプトに質問を記入し、「実行」しましょう。
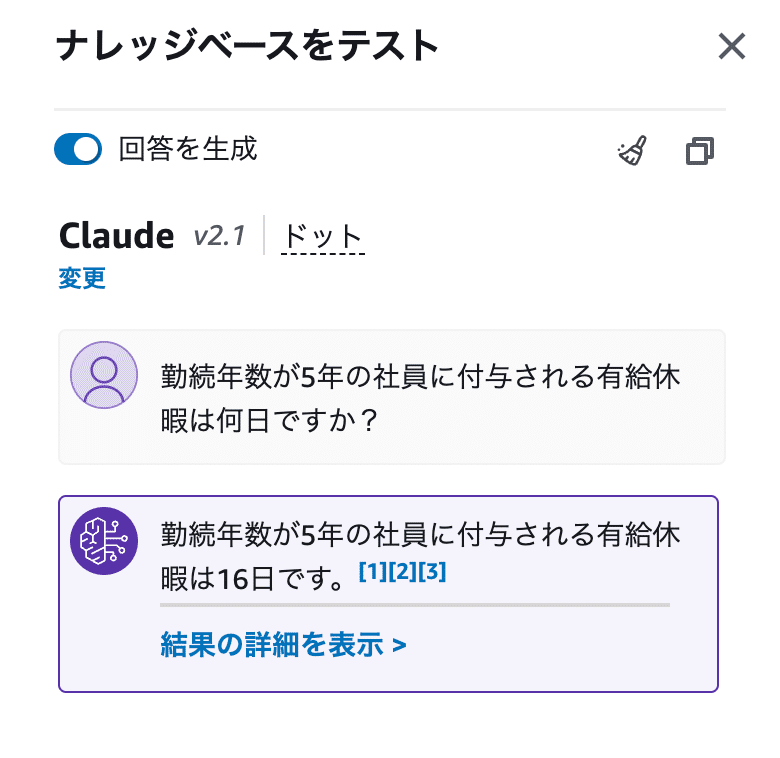
筆者は就業規則データをアップしているので、就業規則に関する質問を投げてみたいと思います。
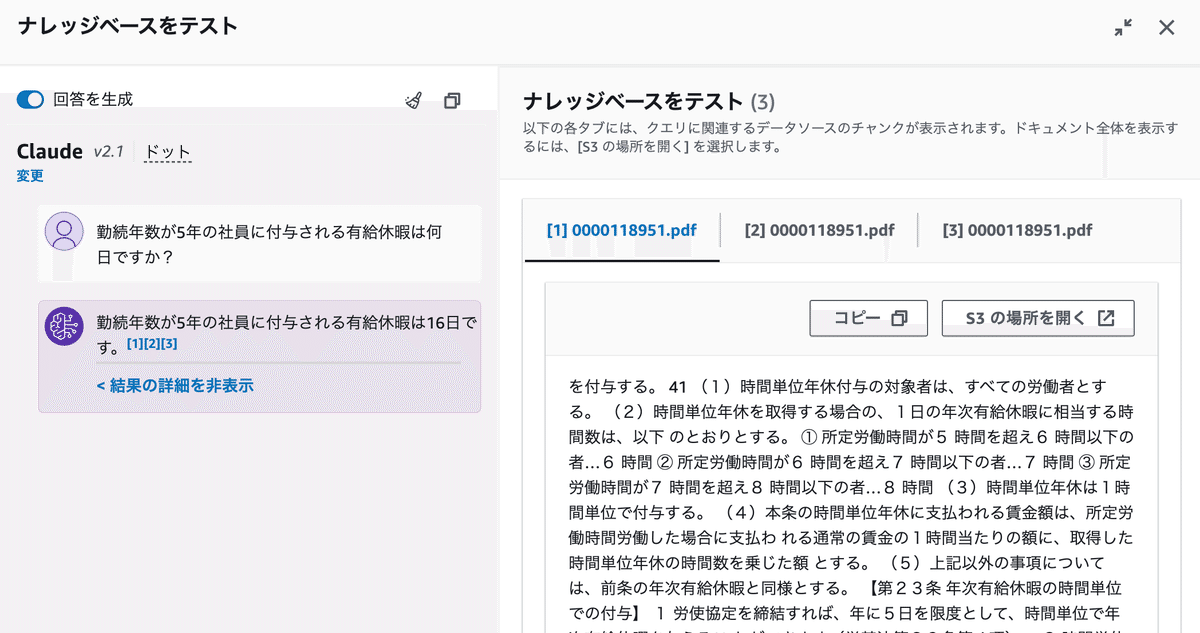
勤続年数が5年の社員に付与される有給休暇は何日ですか?回答が返ってきましたね。約10秒程度でしょうか。ふむふむ。
「結果の詳細を表示」をクリックするとデータソースの詳細を確認することができます。
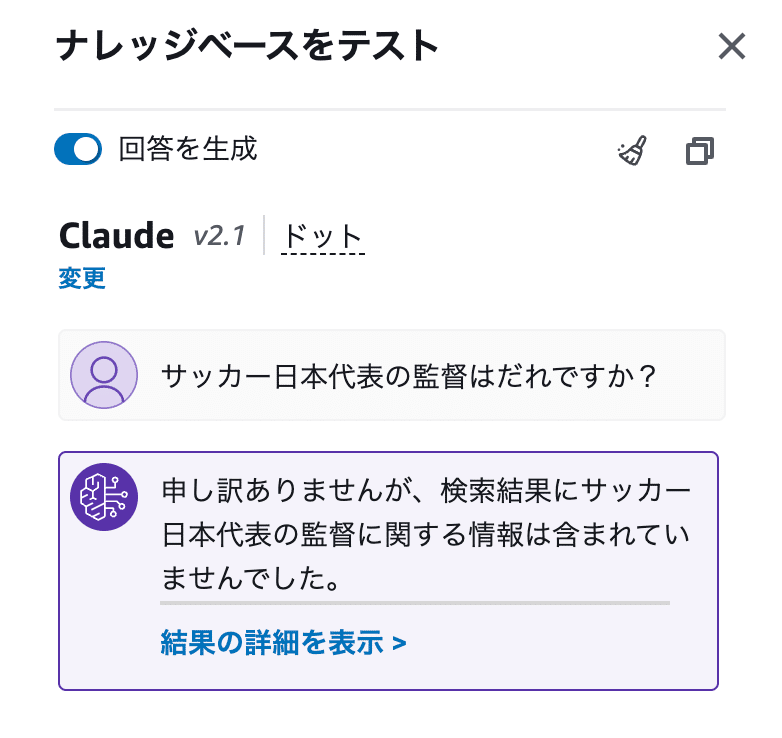
今度は、データソースに無い質問をしてみます。
サッカー日本代表の監督はだれですか?回答が返ってきました。予想通りの回答です。
ハルシネーション処理が効いているようです。すばらしいですね。
まとめ
いかがだったでしょうか。今回は簡単にマネージメントコンソールから利用しました。Knowledge baseの一通りの動きを確認することはできたと思います。実際の本番システムでは、Web画面を通してAPI利用した運用が望まれることでしょう。こちらに関しては今後記事にしたいと思います。
削除時の注意点
Knowledge baseを削除する場合の注意があります。
Knowledge baseを削除してもOpenSearch Serverlessのリソースが残ります。知らず知らずに課金されてしまいますので、直接OpenSearchサービスから削除を行いましょう。
参考
関連記事
AWSの生成AIサービス「Bedrock」を使ってみる
AWSの生成AIサービスBedrockを使って画像生成をやってみる