【AWSのログ管理】WAFのログをAthenaを使って調査してみる

WAFのログについて
AWS WAFのログは、攻撃の検出やブロックに関する情報を記録します。リクエスト日時、送信元のIPアドレス、リクエスト情報、ルールの評価アクションなどが記録されます。
これらのログ情報を分析することで、攻撃の詳細な分析や、セキュリティ対策の改善に役立てることができます。また、ログ情報を基にアラートや通知を設定することも可能です。
今回は、WAFのログをAthenaを使って分析をしてみたいと思います。
それでは設定を行っていきます。
前提
CloudFrontに設定されたWAFを前提とし、かつ、WAFログの設定が無効化の状態からすすめたいと思います。
WAFログの保存先設定(S3バケット)
S3バケットの作成と注意点
まずは、WAFログを保存するためのS3バケットを作成します。
S3バケット作成の手順は割愛しますが、バケット名は「aws-waf-logs-」から始まる名前にする必要があります。
WAFログの有効化
※WAFログの設定が済んでいる場合は、この作業は必要ありません。
1.AWS コンソールにログインし、WAF & Shieldを選択します。
2.左メニューからWeb ACLsを選択します。
3.有効化する対象のACLをクリックします。
4.「Logging & metrics」タブを選択します。
5.「Logging」欄のEnableをクリックします。

6.ログ設定項目を入力します。
「Logging destination」: S3 Bucketを選択します。
「Amazon S3 bucket」:先程作成したS3バケットを選択します。
「Redacted fields」:適宜設定します。
※記録したくないフィールドがある場合検討します。
「Filter logs」:デフォルトのまま。
※今回はフィルターはかけず設定します。
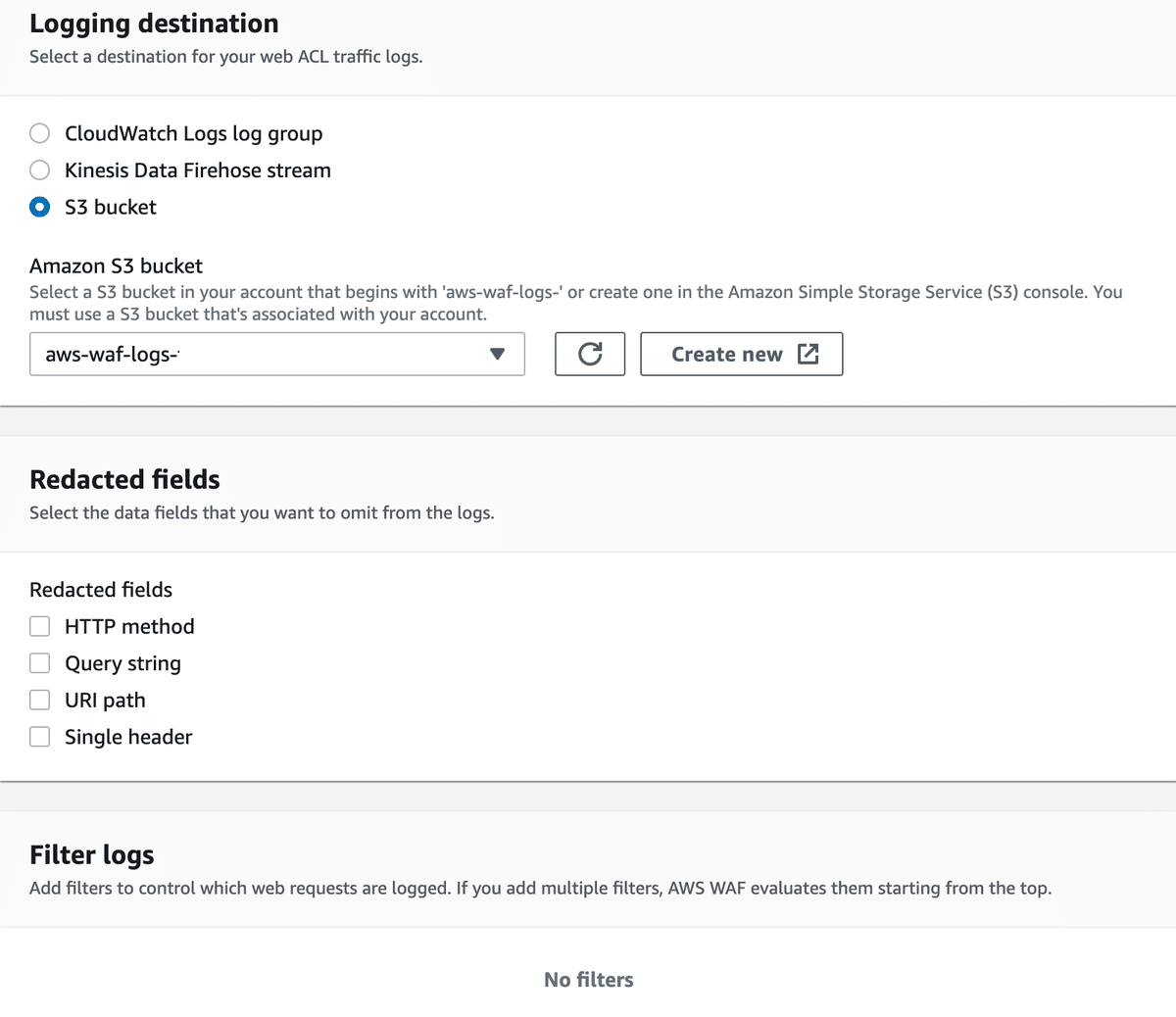
設定は以上となります。「Save」をクリックするとログが取得されるようになります。
※しばらく待つとログが指定したS3バケットに出力し始めます。
WAFログの形式について
ログの出力形式は、こちらが参考になります。
ログの各フィールドの説明は、こちらが参考になります。
Athenaの設定
WAFログの調査ができるように、Athenaを設定していきます。
1.AWS コンソールにログインし、Athenaを選択します。
2.「クエリエディタを起動」をクリック。
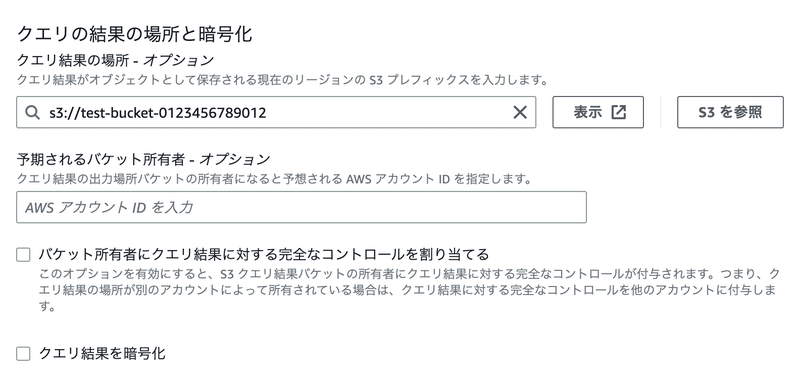
3.クエリ結果の保存設定
初めてAthenaを利用する場合、画像にあるような注意事項が表示され、クエリエディタからクエリを実行することができません。
Athenaのクエリ結果を保存するためのS3バケット設定が必要になります。
予めS3バケットの用意がある場合はそのまま「設定を編集」をクリックして設定にすすみます。
S3バケットの用意が無い場合は、S3バケットを新たに作成してから画像にある「設定を編集」にすすみます。

「設定を編集」をクリック後、いくつか入力項目があります。
「クエリ」結果の場所にS3バケット名を指定します。
他の設定は適宜指定をしてください。後で変更することもできます。
「保存」をクリックするとクエリが実行できるようになります。
4.データベースの設定
Athena内にWAFログを分析するためのデータベースを作成します。
データベース名はわかりやすいように「waflogs」としてます。
クエリエディタ画面に下記のコードをペーストして「実行」します。
CREATE DATABASE waflogs;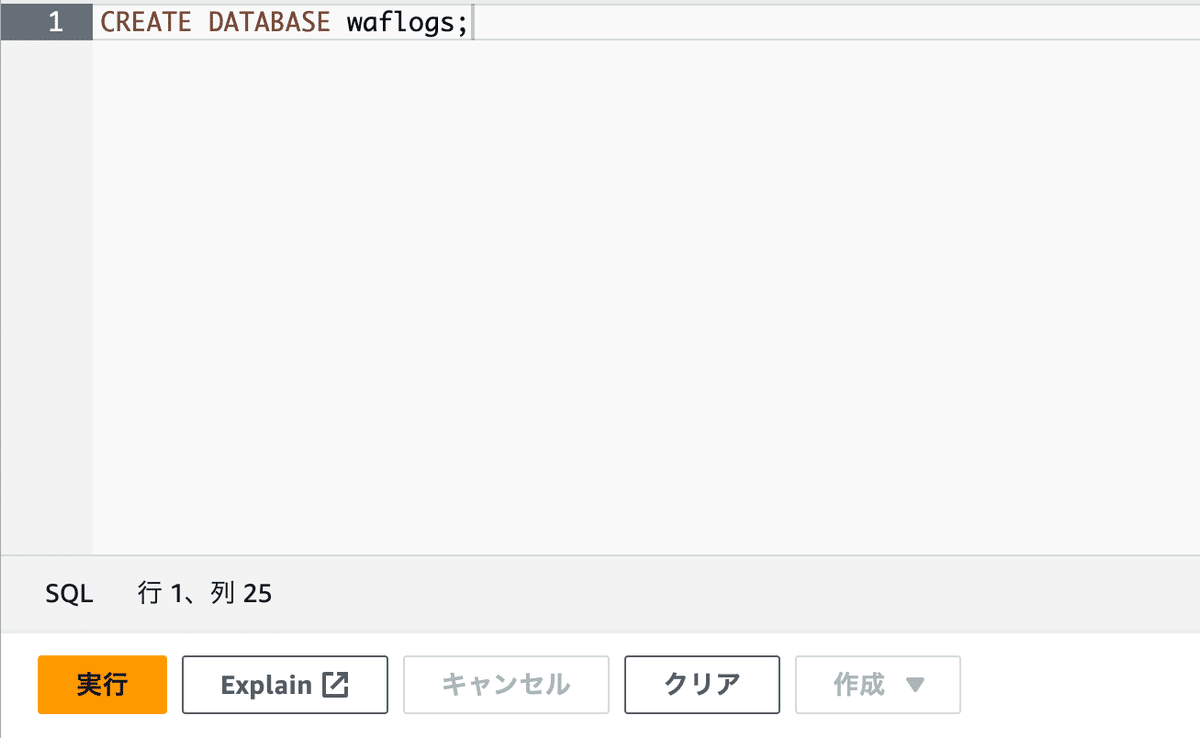
コマンドが正常に実行できれば、データベース欄のプルダウンメニューに作成したデータベース「waflogs」が表示されます。

5.テーブル作成
続いてテーブル作成をします。
テーブル作成用のコマンドはAWSドキュメントに記載のコマンドを参考にして実行します。
参考:AWSドキュメント
https://docs.aws.amazon.com/ja_jp/athena/latest/ug/waf-logs.html
※今回はパーティショニングなしでテーブル作成してます。
最下部にある、「LOCATION」部分の編集が必要です。WAFログ用に作成したS3バケットを指定します。
CREATE EXTERNAL TABLE `waf_logs`(
`timestamp` bigint,
`formatversion` int,
`webaclid` string,
`terminatingruleid` string,
`terminatingruletype` string,
`action` string,
`terminatingrulematchdetails` array <
struct <
conditiontype: string,
sensitivitylevel: string,
location: string,
matcheddata: array < string >
>
>,
`httpsourcename` string,
`httpsourceid` string,
`rulegrouplist` array <
struct <
rulegroupid: string,
terminatingrule: struct <
ruleid: string,
action: string,
rulematchdetails: array <
struct <
conditiontype: string,
sensitivitylevel: string,
location: string,
matcheddata: array < string >
>
>
>,
nonterminatingmatchingrules: array <
struct <
ruleid: string,
action: string,
overriddenaction: string,
rulematchdetails: array <
struct <
conditiontype: string,
sensitivitylevel: string,
location: string,
matcheddata: array < string >
>
>
>
>,
excludedrules: string
>
>,
`ratebasedrulelist` array <
struct <
ratebasedruleid: string,
limitkey: string,
maxrateallowed: int
>
>,
`nonterminatingmatchingrules` array <
struct <
ruleid: string,
action: string,
rulematchdetails: array <
struct <
conditiontype: string,
sensitivitylevel: string,
location: string,
matcheddata: array < string >
>
>,
captcharesponse: struct <
responsecode: string,
solvetimestamp: string
>
>
>,
`requestheadersinserted` array <
struct <
name: string,
value: string
>
>,
`responsecodesent` string,
`httprequest` struct <
clientip: string,
country: string,
headers: array <
struct <
name: string,
value: string
>
>,
uri: string,
args: string,
httpversion: string,
httpmethod: string,
requestid: string
>,
`labels` array <
struct <
name: string
>
>,
`captcharesponse` struct <
responsecode: string,
solvetimestamp: string,
failureReason: string
>
)
ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe'
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://<ログ保存用に作成したS3バケット名を指定>/'コマンドが成功すると、左側の画面のテーブル欄に「waf_logs」テーブルが表示されるようになります。
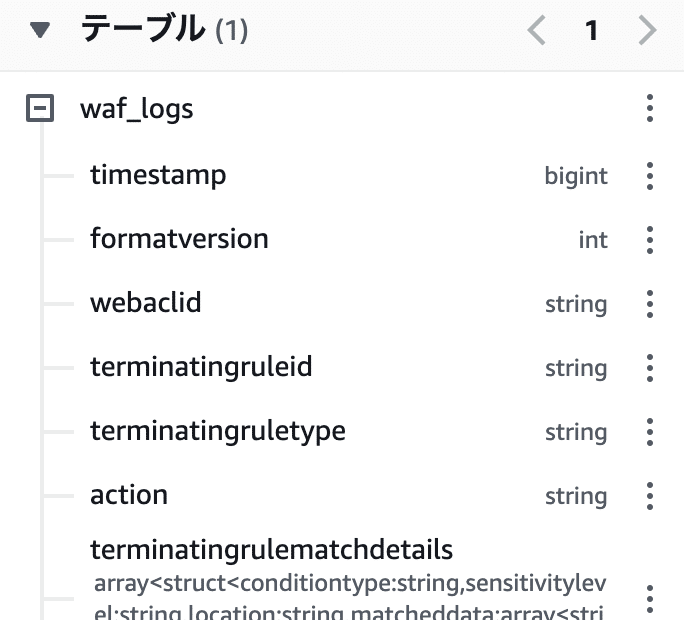
これで準備は終了です。
WAFログを調査する
WAFログにたいしてクエリを実行できるようになりました。まずはデータが入っているか確認します。
クエリエディタ画面に下記のコマンドをペーストして「実行」します。
うまくいけば、10件のログが出力されます。
SELECT * FROM "waf_logs" limit 10;参考までにいくつかクエリを紹介します。
日付を指定し、ログを抽出するコマンド。
※WAFログはUNIX時間のため、from_unixtime関数を使ってTimestamp表示を変更しています。
SELECT DATE_FORMAT(FROM_UNIXTIME(waf_logs.timestamp/1000, 'Asia/Tokyo') ,'%Y-%m-%d %h:%i:%s') AS JST, *
FROM waf_logs
WHERE
from_unixtime(timestamp / 1000, 'Asia/Tokyo') >= timestamp '2023-05-17 00:00:00 Asia/Tokyo'
and from_unixtime(timestamp / 1000, 'Asia/Tokyo') <= timestamp '2023-05-18 23:59:59 Asia/Tokyo';HTTP ソース名、ソース ID、およびリクエストの上位10件を返します。
SELECT DATE_FORMAT(FROM_UNIXTIME(waf_logs.timestamp/1000, 'Asia/Tokyo') ,'%Y-%m-%d %h:%i:%s') AS JST,
httpsourcename,
httpsourceid,
httprequest
FROM waf_logs
LIMIT 10; 日付指定で、「BLOCK」のみ抽出するコマンド。
SELECT DATE_FORMAT(FROM_UNIXTIME(waf_logs.timestamp/1000, 'Asia/Tokyo') ,'%Y-%m-%d %h:%i:%s') AS JST, *
FROM waf_logs
WHERE
from_unixtime(timestamp / 1000, 'Asia/Tokyo') >= timestamp '2023-05-17 00:00:00 Asia/Tokyo'
and from_unixtime(timestamp / 1000, 'Asia/Tokyo') <= timestamp '2023-05-18 23:59:59 Asia/Tokyo'
AND action = 'BLOCK';このようにAthenaを使えば簡単にログの分析をすることができるようになります。
まとめ
WAFログを有効にすることで、アクセスに関する情報を収集することができます。万が一ネットワーク攻撃を受けた際の分析やセキュリティ対策の改善にも利用することができます。
ぜひ有効化したいものですね。