
Google Cloud Datalab でアドホック分析環境をチームに共有する #Zaim

こんにちは、Zaim で開発を担当している原です。これまで Android アプリやサーバーサイドがメイン業務でしたが、2019 年からは機械学習・データ分析にも関わるようになりました。
今回は、そのアドホック分析の環境をチーム内で共有するために実施した、Google の Datalab の整備について書いてみようと思います。
Datalab とは何か
Datalab は、GCP(Google Cloud Platform)およびローカル PC 上でデータ探索・分析、そして機械学習モデル構築などを行うための Jupyter ベースの分析環境です。
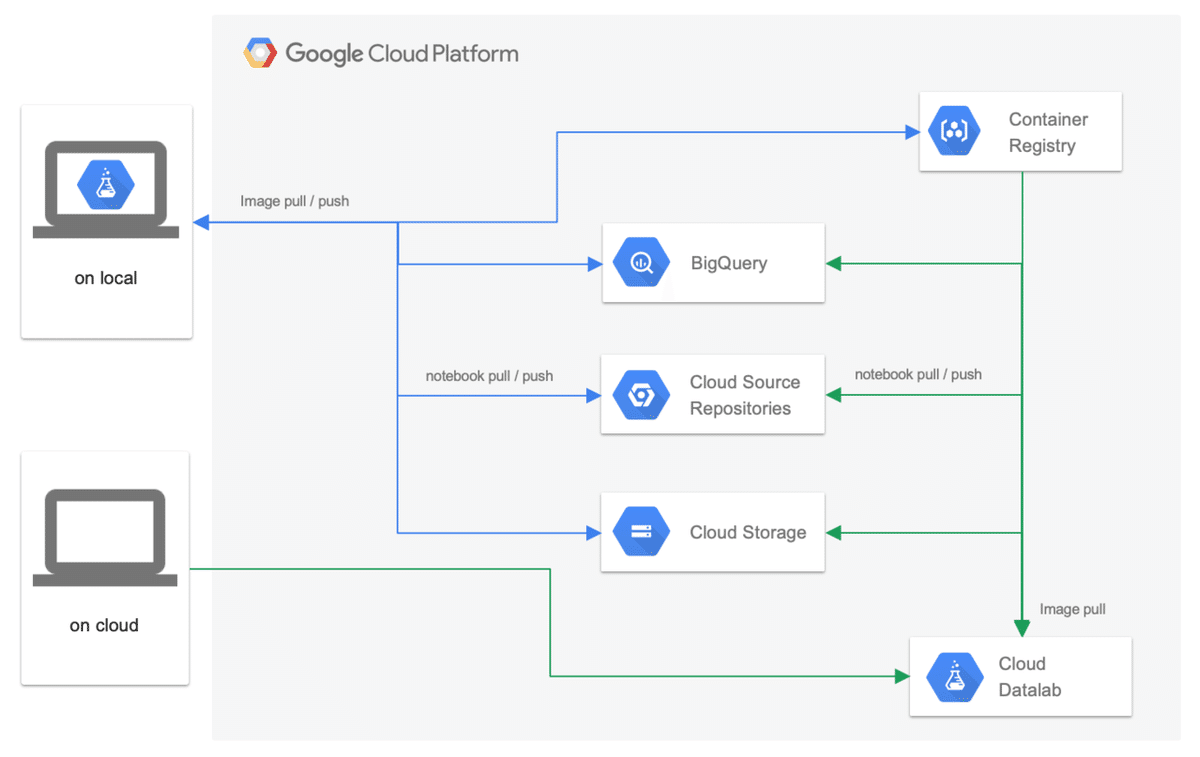
実態は Docker イメージなので、ローカルでも GCP のクラウド上でも同じ環境で作業できるメリットがあります。
また、GCP 関連のサービスとシームレスに連携可能なことも非常に使いやすい点です。データレイクとして BigQuery や Cloud Storage へ簡単にアクセスできたり、さらに Cloud Source Repositories と自動連携してチーム内で Notebook などをバージョン管理しながら共有できたりと、大きな恩恵があります。
Datalab の利用シーン
Datalab の利用シーンとしては、大きく二つあります。
一つ目はローカル上の Docker 環境としてです。ちょっとしたデータ分析やデータ探索、実験的にモデルを構築する場合には、ローカル PC 上で試します。
Datalab の Docker イメージは、GCP のコンテナコードレジストリである Container Registry 上で管理しています。このため、一度 pull すれば Cloud にインスタンスを準備せずとも利用可能な状態になります。また、アクセス権のある Google アカウントでログインして、ローカル PC から GCP 上のリソースにアクセスすることで、Cloud インスタンスで起動した場合と同じように作業できます。
もう一つは GCP のクラウド環境としてです。数十万から数百万以上の学習データでモデルを構築したり、大量のデータを正規化したりする場合は、クラウド環境で実行します。
長い時間、連続で実行する必要があったり、ローカル PC ではスペックが不足していたりするのであれば、クラウドの力に頼ります。特に処理の高速化のために GPU(Graphics Processing Unit)が必要な場合には、GCP 環境を利用することで簡単に環境を準備できます。
Datalab を採用した理由
Zaim では、もともと分析用のデータレイクは GCP 上にあり、また機械学習の環境も GCP 上で構築していました。こうした背景から、GCP サービス群とシームレスに接続できるアドホック環境が必要だったため、Datalab の検討を始めました。
Datalab 以外で検討したアドホック分析環境としては、同じく Google が提供している Colaboratory があります。
Colaboratory は、GCE の n1-highmem-2 インスタンスをユーザーごとに占有でき、かつ GPU/TPU も無料で使えるため、一時的にぱっと使うには一番良い選択だと思います。これが無料で利用できるとは、驚きです!
では、なぜ Colaboratory ではなく Datalab にしたかというと、Colaboratory には以下の二つの課題があったためです。どちらも少しの手間で回避できるのですが、そこを避けたいというのがエンジニアというものですね。
(1)毎回インスタンスが初期状態になる
Colaboratory でも Notebook などは保存できますが、独自に追加した deb パッケージや Python のパッケージは毎回インストールをし直す必要があります。Datalab ではこうした部分も含め、Dockerイメージとして共有することが可能です。
(2)同一環境をチーム内に共有しづらい
Colaboratory でも、同一環境をチームで共有できないわけではありません。しかしながら、 requirements.txt や deb パッケージリスト、インストール手順ないしインストールスクリプトを配布して、Colaboratory の起動時に各自で毎回インストールするーーーといった、複雑な手順が必要になります。環境が大きくなりメンバーが増えると、チーム全体で浪費する時間は無視できません。
これも、Datalab では Docker イメージとして共有すれば、各自はイメージを pull し直すだけで最新の環境が手に入ります。
その他、Colaboratory の制限項目は以下のようなものがあります。
・十分なスペックではあるものの、マシンスペックが固定
・インスタンスが起動してから 12 時間後に停止する
・アイドル状態で 90 分後に停止する
・毎回インスタンスが初期状態になる。
Datalab をチームで共有する手順
では実際に、Datalab に独自パッケージを追加し、チーム内に共有できるようにDocker イメージを作成、Cloud Registryで管理するまでに手順を紹介していきましょう。Docker for Mac や gcloud コマンドのインストール及び初期設定などは完了しているところから記載します。
(1)Dockerfile の作成
ベースとするイメージを gcr.io/cloud-datalab/datalab:latest として、後は必要な deb パッケージや Python パッケージなどをインストールするように記載していけば良いだけです。今回は、日本語の自然言語処理をするために必要な辞書やパッケージをインストールするサンプルを紹介します。
* Zaimで利用しているバージョンやパッケージとは一部異なります
以下が Dockerfile です。ベースが gcr.io/cloud-datalab/datalab:latest となっています。
# Dockerfile
FROM gcr.io/cloud-datalab/datalab:latest
COPY ./install.sh ./
COPY ./neologd.sh ./
COPY ./requirements.txt ./
RUN ./install.sh
install.sh ファイルです。conda で py2env を remove しているところはポイントです。なお、利用しない Python 2 系の環境は消して、少しでもイメージサイズを小さくすることにしています。
#!/usr/bin/env bash
cd `dirname $0`
apt-get update -qy && apt-get install --no-install-recommends -qy \
build-essential git file swig \
mecab libmecab-dev mecab-ipadic mecab-ipadic-utf8 nkf net-tools && \
source activate py3env && \
conda remove -y -n py2env --all && \
conda update -n base -c defaults conda && \
conda update pip && \
pip install wheel && \
pip install -U pip && \
pip install -U datalab && \
pip install -U -r requirements.txt && \
./neologd.sh && \
apt-get purge -y build-essential bzip2 cpp pkg-config libfreetype6-dev &&\
apt-get autoremove -y &&\
rm -rf /var/lib/apt/lists/* &&\
rm -rf /var/lib/dpkg/info/* &&\
rm -rf /tmp/* &&\
rm -rf /root/.cache/*
neologd.sh は、mecab 用の辞書である、neologd のインストール処理を記載しています。再現性を担保するには、同じ辞書を利用することが重要であり、辞書のバージョンを固定してイメージが作成できるようにしています。
#!/usr/bin/env bash
REVISION=a626602b1390514658a087684c18465abc260cc7
DICT_REVISION=c28d369b5a36f88e77c471f8698bb281e34205e2
DICT_NAME=mecab-user-dict-seed.20190211.csv.xz
DEPTH=100
mkdir -p `mecab-config --dicdir` && \
git clone --depth $DEPTH https://github.com/neologd/mecab-ipadic-neologd.git && \
cd mecab-ipadic-neologd && \
git checkout $REVISION -b old_revision && \
wget https://github.com/neologd/mecab-ipadic-neologd/blob/$DICT_REVISION/seed/$DICT_NAME?raw=true -O seed/$DICT_NAME && \
./bin/install-mecab-ipadic-neologd -y -u && \
cd ../ && rm -rf mecab-ipadic-neologd
お馴染みの requirements.txt です。バージョンは固定化しています。
tensorflow == 1.12
mecab-python3 == 0.996.1
pyknp == 0.4.1
Cython == 0.29.6
gensim == 3.7.1
jaconv == 0.2.4
zenhan == 0.5.2
xmltodict == 0.12.0
google-cloud-storage == 1.14.0
(2)Dokcer イメージのビルド
イメージのビルドは、通常の Docker イメージのビルドと同じです。
$ docker build -t your-datalab .(3)Container Registry に push
まずは、docker コマンドで GCP の Container Registry に対して push / pull ができるようにします。
$ gcloud auth configure-dockerその後は、docker コマンドでイメージを push します。以下の例の GCP リージョン、プロジェクト ID などは、ご自身の環境に合わせて読み替えてください。
$ docker tag your-datalab-nlp us.gcr.io/your-gcp-project-id/your-datalab:latest
$ docker push us.gcr.io/your-gcp-project-id/your-datalab:latest
(4)ローカルで Datalab を起動
下記のような起動スクリプトを準備しておくと便利だと思います。
#!/bin/bash
IMAGE=us.gcr.io/your-gcp-project-id/your-datalab:latest
CONTENT=/your-work-directory/datalab-local
PROJECT_ID=$(gcloud config get-value project)
PORTMAP="127.0.0.1:8081:8080"
docker pull $IMAGE
docker run -it \
-p $PORTMAP \
-v "$CONTENT:/content" \
-e "PROJECT_ID=$PROJECT_ID" \
$IMAGE上記スクリプト実行後は http://localhost:8081 にアクセスすると Jupyter の画面が表示されます。
Datalab の GPU 化の手順
機械学習のモデル構築は、ベクトル・行列の演算処理が多く、学習データが膨大になったり、ディープラーニングのパラメータ数が多くなると CPU 処理では非常に(とても待てないくらい)時間がかかります。こうした場合は、GPU で処理をさせています。
しかしながら、GPU を使うには NVIDIA のドライバ、CUDA Toolkit、cuDNN のインストールなど、環境準備に手間がかかります。
当初、GPU の Datalab 環境を構築するにあたり前項で作った Dockerfile に CUDA Toolkit などをインストールしていました。ですが、これは非常に手間がかかる作業だったので、いろいろ調査したところ gcr.io/cloud-datalab/datalab-gpu:latest を発見しました。これをベースにイメージをビルドすれば、datalab コマンドで GCP にデプロイするだけで、すぐに GPU 環境が手に入ります。
以下で、xgboost を GPU 環境で動かせるようにする手順を紹介します。
(1)Dockerfile の修正
以下が Dockerfile の差分です。ベースを変更しています。
-FROM gcr.io/cloud-datalab/datalab:latest
+FROM gcr.io/cloud-datalab/datalab-gpu:latest
ENV DEBIAN_FRONTEND noninteractive
ENV DEBCONF_NOWARNINGS yes
COPY ./install.sh ./
COPY ./neologd.sh ./
COPY ./requirements.txt ./
RUN ./install.sh
次に install.sh の差分です。xgboost の本家のサイトに従い、直接 whl ファイルを指定してインストールし直しています。
#!/usr/bin/env bash
cd `dirname $0`
apt-get update -qy && apt-get install --no-install-recommends -qy \
build-essential git file swig \
mecab libmecab-dev mecab-ipadic mecab-ipadic-utf8 nkf net-tools && \
source activate py3env && \
conda remove -y -n py2env --all && \
conda update -n base -c defaults conda && \
conda update pip && \
pip install wheel && \
pip install -U pip && \
pip install -U datalab && \
+conda uninstall xgboost && \
+wget https://files.pythonhosted.org/packages/54/21/8b2ec99862903a6d3aed62ce156d21d114b8666e669c46d9e54041df9496/xgboost-0.81-py2.py3-none-manylinux1_x86_64.whl && \
pip install xgboost-0.81-py2.py3-none-manylinux1_x86_64.whl && \
pip install -U -r requirements.txt && \
./neologd.sh && \
+rm -f xgboost-0.81-py2.py3-none-manylinux1_x86_64.whl
apt-get purge -y build-essential bzip2 cpp pkg-config libfreetype6-dev &&\
apt-get autoremove -y &&\
rm -rf /var/lib/apt/lists/* &&\
rm -rf /var/lib/dpkg/info/* &&\
rm -rf /tmp/* &&\
rm -rf /root/.cache/*上記の修正をしたら、イメージを build して Container Registry に push します。
(2)GCP にデプロイ
下記のコマンドを実行すると GCP 上に GCE(Google Compute Engine)インスタンスが作られ、ブラウザが起動して Jupyter の画面が確認できるはず。現在、利用できる GPU は NVIDIA の Tesla K80 のみのようです。
$ datalab beta create-gpu hara-datalab \
--image-name us.gcr.io/your-gcp-project-id/your-datalab:latest \
--machine-type n1-highmem-2 \
--disk-size-gb 30 \
--accelerator-type nvidia-tesla-k80 \
--accelerator-count 1ちなみに CPU インスタンスで起動させる場合は下記になります。
$ datalab create hara-datalab \
--image-name us.gcr.io/your-gcp-project-id/your-datalab:latest \
--machine-type n1-highmem-2 \
--disk-size-gb 30(3)xgboost が GPU を認識しているか確認
起動した Jupyter の Notebook 上で、xgboost が GPU を認識しているか確認するための方法も記載しておきます。下記を実行して例外が発生しなければ、GPU が認識されています。
import xgboost as xgb
import numpy as np
X = np.random.rand(20,2)
y = np.random.randint(0,3,20)
clf = xgb.XGBClassifier(n_jobs=-1,tree_method='gpu_hist')
clf.fit(X,y)
(4)(おまけ)Docker イメージのサイズを確認
おまけとして、Dockerイメージのサイズをみてみましょう。かなりのイメージサイズになりました。サーバサイドの開発でもDockerを利用していますが、Datalabは桁違いに大きいサイズです。
$ $ docker images --format "table {{.Repository}} {{.Tag}} {{.Size}}" | grep datalab
your-datalab latest 6.38GB
gcr.io/cloud-datalab/datalab-gpu latest 8.66GB
gcr.io/cloud-datalab/datalab latest 4.67GB終わりに
今回は、データ探索・分析および機械学習のためのアドホック環境の構築について紹介しました。今後は、定期学習環境や予測環境などを充実させ、また環境整備と並行して、より複雑な課題に対してのディープラーニングの活用にも挑戦していきたいと考えています。こうした学習・予測環境はまた改めて紹介できればと思います。
なお、今回は Datalab の紹介でしたが、Colaboratory は無料で利用できるので、まずはすぐに動かしてみたい方には Colaboratory がオススメです。