
【CVPR'19 / ICCV'19】3D Human Pose Estimationの最新研究動向まとめ

はじめに
Pose Estimationとは、画像や動画から人物の姿勢(関節位置)を推定するタスクのことです。特殊なマーカーを身に着けたりせずに、一般的な動画像のみから人物の姿勢を推定できるため、例えば
・スポーツにおける選手のフォーム分析
・映画やアニメの制作におけるモーションキャプチャ
・店舗の監視カメラ映像を元にした人物の行動解析
など、様々なアプリケーションが考えられます。
従来は画像上の関節位置のXY座標のみを推定する2D Pose Estimationの研究や応用が主流でしたが、近年のDeep Learningを中心とした画像認識技術の発展により、奥行方向も含めて3次元的に人物の姿勢を推定する3D Pose Estimationの研究が活発化しており、現実世界のヒトの動き・行動をよりリアルに認識することが可能になってきています。
本記事では特に2019年のCVPRやICCVなど画像認識のトップカンファレンスに採録された7本の論文を取り上げながら、3D Pose Estimationに関する近年の研究動向を追っていきます。
7本の論文のトピックを簡潔に整理してみたのが以下の図です。

以下で詳しく見ていきます。
断りがない限り、記事中で用いられる図表は元論文から掲載したものです。
[Wandt+ CVPR'19] RepNet: Weakly Supervised Training of an Adversarial Reprojection Network for 3D Human Pose Estimation
こちらは2D Poseと3D Poseの対応関係に関する制約をうまく用いて、弱教師あり学習で単一画像から3D Pose Estimationを学習する手法の提案です。

パイプラインは以下のようにシンプルなものです。
1. 任意の2D Pose Estimatorで画像から2D Poseを抽出
2. 2D Poseを入力として、3D PoseとCamera Poseを出力
3. 3D PoseとCamera Poseを入力として、2D Poseを出力
学習時は以下の3つの損失関数を最小化するように学習します。
・2で生成された3D Pose*に対するWasserstein Loss
・2で生成されたCamera Poseに対するCamera Loss
・3で生成された2D PoseのReprojection Loss
* 厳密にはKCSと呼ばれる人体構造を明示的に考慮する特徴も生成して識別
2D→3D+Camera→2DというReprojectionの活用(と敵対的誤差での学習)が肝であることがタイトルのRepNet(Reprojection Network)にも現れていますが、このようなテクニックを用いたアプローチは近年増えているようです。実際に、次に紹介する2つの論文も、似たようなテクニックをベースにしています。
[Habibie+ CVPR'19] In the Wild Human Pose Estimation Using Explicit 2D Features and Intermediate 3D Representations
こちらも[Wandt+ CVPR'19]同様に、3Dから2Dへの射影をうまく使うことで3D Pose Estimationを学習する手法の提案です。

パイプラインも[Wandt+ CVPR'19]とほぼ同様ですが、中間で2D Poseの情報(h_2D)と3D Pose Estimationに必要なdepthに関する特徴(d)を明示的に分けて扱う機構を導入しています。これによって入力画像の見た目の変化などに対してロバストな表現が学習可能とされています。
また、3D Poseについては、ラベルが存在する場合は誤差を最小化するように教師ありで学習します。(Boneの長さを考慮する損失も導入しています)
[Chen.C+ CVPR'19] Unsupervised 3D Pose Estimation with Geometric Self-Supervision
こちらも[Wandt+ CVPR'19]や[Habibie+ CVPR'19]同様に2D↔3D間の射影を考慮した幾何学的(Geometric)な制約を用いた自己教師あり学習によって、教師なしに3D Pose Estimationを行う手法の提案です。

パイプラインはこれまでの2本の論文と比べるとやや複雑です。
まず、入力として2D Poseを用意した後、以下の手順を踏みます。
1. Lifting Networkで2D Poseを3D Poseに変換(Estimated 3D Skeleton)
2. ランダムな3D回転行列をかけて視点を変換(Transformed 3D Skeleton)
3. 回転後の3D Poseを2D Poseに射影(Random 2D Projection)
4. Lifting Networkで2D Poseを3D Poseに変換(Estimated 3D Skeleton)
5. 2と逆の回転変換をかけ、元の視点に戻す(In original coordinates)
6. 2D Poseに射影(Recovered 2D Pose)
学習時は以下の3つの損失関数を最小化するように学習します。
・2と4の3D Pose同士の誤差(L_3D)
・3で生成した2D Poseの敵対的誤差(L_adv)
・1と5の2D Poseの再構成誤差(L_2D)
回転普遍な3D Poseの性質をうまく考慮した機構と、人体の構造として不自然な姿勢を学習しないように敵対的誤差を導入することで教師なしに3D Poseを学習できるようにしているのがポイントと考えられます。
また、さらなる工夫として、ドメイン適応の技術を用いてin the wildな2D Poseに対する頑健性を向上させるための工夫も提案しています。
[Chen.X+ CVPR'19] Weakly-Supervised Discovery of Geometry-Aware Representation for 3D Human Pose Estimation
こちらは上記3つの論文とは異なり、複数視点(Multi-view)の静止画と2D Poseのアノテーションのみから3D Pose推定に役立つ潜在表現を学習する手法の提案です。

手法としては以下のようになります。
1. まず2つの視点i, jの画像を用意する
2. それぞれ任意の2D Pose Estimatorに入力し、2D Pose v_i, v_j を得る
3. それぞれの2D PoseをEncodeし、潜在表現 G_i, G_jを得る
4. 視点iとjを変換する回転行列をそれぞれに適用し、G_ij, G_jiを得る
5. それぞれDecoderに通し2D Pose v'_j, v'_iを得る
学習の際は、モデルの入力v_i, v_jと出力v'_i, v'_jの誤差に加えて、潜在表現G_ijとG_jの誤差を最小化するように学習させることで、表現の一貫性を担保します。
実験の結果、学習した潜在表現を既存の3D Pose Estimationのモデルに組み込む(特徴ベクトルを足す)ことで、精度の改善が確認されました。
この論文のポイントの一つが、Pose空間での潜在表現を学習することです。
複数視点の2D画像を用いて3D Poseの表現を学習する手法は、例えば[Rhodin+ ECCV'18] などがありますが、これはRGB画像の空間上で直接学習を行っているため、表現学習が見た目などの特徴に引っ張られやすいことが考えられます。特に学習に用いているHuman3.6Mのデータセットはスタジオ環境で撮影されているため、人物や背景の見た目のばらつきが小さく特殊なため、見た目の特徴に十分に汎化していないとin the wildな一般画像に適用した時に精度が大きく低下する可能性が考えられます。
そのため、本論文ではPoseの空間で表現を学習することで、見た目にロバストな3D Poseの表現を学習する(見た目の多様性は2D Pose Estimatorのほうに吸収させる)というイメージかなと思います。
ネックになり得るのが、2つの視点i, jの位置関係が既知であることを前提としている点かなと思います。カメラの正確な位置関係がわからない場合も現実では数多くあるため、その場合は利用が難しそうです。あくまでHuman3.6Mのようなリッチなデータで学習した表現を他に活用する、
という利用法になるかと思います。
[Kocabas+ CVPR'19] Self-Supervised Learning of 3D Human Pose using Multi-view Geometry
こちらも複数視点の画像を活用して2D Pose→3D Poseの変換を学習する手法です。こちらはエピポーラ幾何を利用したEpipolarPoseを提案しています。
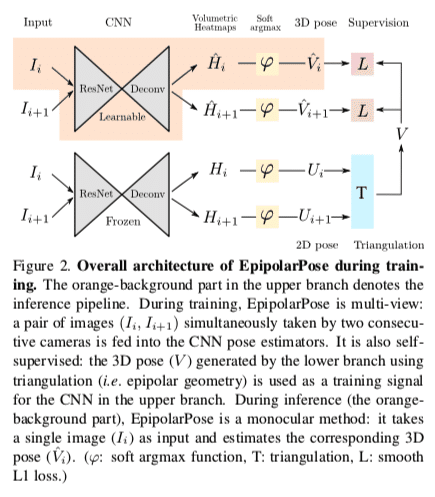
まず、2つのPose Estimation Network(branch)を用意します。
一つ(Upper Branch)は単一画像から3D Poseを推定するためのネットワークで、もう一つ(Lower Branch)は複数画像からそれぞれ2D Poseを出力し、エピポーラ幾何を用いて3D Poseを生成するためのネットワークです。
つまり、学習時はLower Branchとエピポーラ幾何から3D Poseの正解ラベルを作成してUpper Branchの教師ラベルとして学習させることで、3Dの正解ラベルなしに単一画像から3D Poseを推定できるモデルを学習させることができます。
また、カメラの位置関係などの外部パラメータがわからない場合でも、データから推定・キャリブレーションできるテクニックも提案しています。
また、本手法と合わせて、関節の位置情報だけでなく人物の構造を考慮した(structure awareな)評価指標であるPose Structure Score(PSS)も提案しています。行動認識などの後段のタスクを考慮すると重要な指標と考えられるので、今後こういった評価指標が普及するかにも注目です。
[Moon+ ICCV'19] Camera Distance-aware Top-down Approach for 3D Multi-person Pose Estimation from a Single RGB Image
最後は複数人(Multi-Person)の3D Pose Estimationを行う手法です。
一般的な3D Pose Estimationのモデルは、骨盤など人物の空間位置の基準点となる関節(root)を決めておき、その基準点からの相対的な位置関係で各関節の座標を表現し、人物の3次元的な姿勢を推定します。
単一人物の姿勢を推定するだけであれば、これでも十分なのですが、複数人の姿勢を推定するとなると、各人が空間上のどの位置にいるのか、すなわちrootの絶対座標も推定する必要が出てきます。

本研究ではこれを実現するために以下の3つのネットワークからなるパイプラインを提案しています。
1. 画像内から人物を検出してクロップするためのDetectNet
2. 人物画像からrootの絶対座標を推定するRootNet
3. 人物画像から各関節のrootからの相対的な位置を推定するPoseNet

1のDetectNetは任意のObject Detectionモデル、3のPoseNetは任意の3D Pose Estimationモデルでよく、肝となるのは2のRootNetです。
RootNetは、DetectNetによって検出・クロップされた人物画像から、人物のrootの3D座標の R =(x_R, y_R, Z_R)を推定します。このうち、2D座標の(x_R, y_R)の推定は比較的容易ですが、3Dの深さ(Z_R)は容易には求まりません。
本論文では、画像上の面積(pixel^2)と実空間上の面積(mm^2)の比率をカメラパラメータと組み合わせることで深さを近似します。ここで、実空間上の面積は、「人物領域のbboxが2,000mm x 2,000mm (xアスペクト比)である」という仮定を置き、bboxのサイズから求めるという手法を取ります。
ただし、この手法だけだと
(a) 実際には同じ距離にいるのに、bboxのサイズが異なる
(b) 実際には違う距離にいるのに、bboxのサイズが等しい
という場合に対応できないため、これらの影響を補正するために画像の見た目上の特徴から推定深度を補正する係数 γ を出力することで対応します。


以下は結果の一例ですが、rootのGround Truthの情報を使わない手法と比べて大きく精度が改善しています。(表下)
従来の3D Pose EstimationのSoTAモデルはGround Truthを使っているものが多いため、公平な比較が難しいのですが、勝ってはいないものの遜色のない精度が発揮できているといえます。(表上)

[Pavllo+ CVPR'19] 3D human pose estimation in video with temporal convolutions and semi-supervised training
こちらは動画の時系列情報を活用して3D Pose Estimationを行う手法です。
既存手法の多くは、まず2Dの姿勢を推定→3Dに変換するという手順を踏むことが多いですが、根本的に2Dと3Dの姿勢は一意に対応するとは限らないという曖昧性(ambiguity)の問題があります。
一方、動画では人物の動きが連続的に観測できるため、その時間的一貫性をうまく活用することで曖昧性を解消することができそうです。
従来はこの時系列処理をRNNで行うことが多かったのですが、本論文ではDilated Convolutionを用いたFully-Convolutionalなモデルで扱うことで計算効率や学習効率の改善などを実現しています。(RNNをCNNなどに置き換える流れは自然言語処理などを中心に最近良く見られますね)
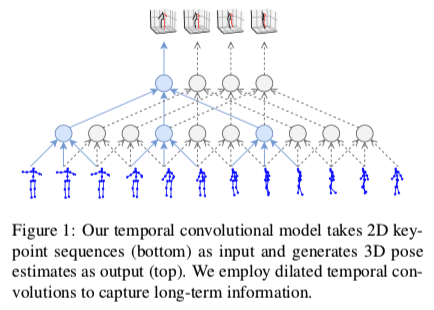
さらに、Back-Projectionを活用した半教師あり学習によって、3D Poseのラベルがないデータを効果的に利用する学習方法も提案しています。詳細な説明は割愛しますが、2D PoseのラベルやMulti-viewの画像などを必要とせず、カメラの内部パラメータのみあればよいというのもポイントです。

こうした動画の時系列情報を前提としたアプローチは、精度高く3D Poseが推定できるだけでなく、推定結果の時間的一貫性がある程度担保されることが想定できます。実際に下のデモを見ても、普通の静止画に対する予測を重ね合わせるだけ(Single-frame model)だと推定位置が飛び飛びになってしまう一方、提案手法(Temporal model)ではフレーム間で関節位置の推定が滑らかにつながっている様子が見て取れますね。
スムージングの技術は他にも様々ありますが、例えばスポーツのフォーム分析など時系列的な情報が重要な場面ではこうした技術が重要になってくると考えられます。

Source: GitHub
3D Pose Estimationのモデルは、
・その手法単独ではなく過去のSoTAモデルと組み合わせて使うもの
・部分的にGround Truthの情報を使うもの
・異なるデータ分割や評価のプロトコルを使うもの
などが存在するため正確な精度の比較が難しいのですが、Human3.6Mに限っていえば、今回紹介した論文の中では本論文のスコアが安定して高いように見受けられました。

まとめ
今回はCVPR2019 / ICCV2019における3D Pose Estimationに関する論文から7本を紹介しました。さまざまな課題感や工夫がありましたが、概ね以下の3つの方向性が中心にあったように思います。
・{Un/Self/Weakly/Semi}-Supervised Learningによるデータ効率改善
・Multi-Personの3D Pose推定のためのAbsolute Localization機構の導入
・動画の時系列情報の活用による曖昧性の解消と時間的一貫性の改善
今後の方向性としては、根本的にアノテーションが難しい・コストの高い3D Pose Estimationの学習を効率化するために、データのラベル効率を改善する研究は引き続き出てくると考えられますが、In the Wildなデータ・独自データでの学習のニーズを考えると、その中でも画像の枚数(視点数)やカメラパラメータに対する事前情報の制約がより緩和された手法が好まれるような気がします。(Human3.6Mのようなリッチなデータでのみ学習できる手法は、他に転移できるくらい十分ロバストであれば価値があると思います)
また、複数人の場合に必要な深度推定や動画の効率的な活用による時間的一貫性の担保なども、一つの要件・評価指標として定着していきそうです。
今回は、CVPR'19 / ICCV'19に採録された論文をベースに、近年の3D Human Pose Estimationの動向をまとめてみました。今後も引き続きキャッチアップしていきたいと思います。
さいごに
私が所属している株式会社ACESでは、Deep Learningを用いた画像認識技術を中心に、APIによるアルゴリズムパッケージの提供や、共同研究開発を行っています。特に、ヒトの認識・解析に強みを持って研究開発を行っておりますので、ご興味のある方は、ぜひお問い合わせください!
【詳細・お問い合わせはこちら↓】
◆画像認識アルゴリズム「SHARON」について
ヒトの行動や感情の認識、モノの検知などを実現する画像認識アルゴリズムを開発しています。スポーツにおけるパフォーマンス分析やマーケティングにおけるヒトの心の動きの可視化、ストレスなどの可視化による健康状態の管理を始めとするAIアルゴリズムを提供しています。
参考文献
・[Wandt+ CVPR'19] Wandt, Bastian, and Bodo Rosenhahn. "RepNet: Weakly Supervised Training of an Adversarial Reprojection Network for 3D Human Pose Estimation." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019.
・[Habibie+ CVPR'19] Habibie, Ikhsanul, et al. "In the Wild Human Pose Estimation Using Explicit 2D Features and Intermediate 3D Representations." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019.
・[Chen.C+ CVPR'19] Chen, Ching-Hang, et al. "Unsupervised 3D Pose Estimation with Geometric Self-Supervision." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019.
・[Chen.X+ CVPR'19] Chen, Xipeng, et al. "Weakly-supervised discovery of geometry-aware representation for 3d human pose estimation." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019.
・[Kocabas+ CVPR'19] Kocabas, Muhammed, Salih Karagoz, and Emre Akbas. "Self-supervised learning of 3d human pose using multi-view geometry." arXiv preprint arXiv:1903.02330 (2019).
・[Pavllo+ CVPR'19] Pavllo, Dario, et al. "3D human pose estimation in video with temporal convolutions and semi-supervised training." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019.
・[Moon+ ICCV'19] Moon, Gyeongsik, Ju Yong Chang, and Kyoung Mu Lee. "Camera Distance-aware Top-down Approach for 3D Multi-person Pose Estimation from a Single RGB Image." arXiv preprint arXiv:1907.11346 (2019).
・[Rhodin+ ECCV’18] Rhodin, Helge, Mathieu Salzmann, and Pascal Fua. "Unsupervised geometry-aware representation for 3d human pose estimation." Proceedings of the European Conference on Computer Vision (ECCV). 2018.