
Tableau のリレーションシップ機能 その10 ~ 参照整合って何?② ~

参照整合について、SQLの観点から何が行われているかを見ていきたいと思います。参照整合が何かについては前回記事を参照下さい。
前回調査した4つのケースについて一つずつ見ていきます。
① 一部のレコードが一致 対 一部のレコードが一致 の場合
前回テストでは、CST_CD でリレーションを行い、CST_CD を使用しない集計を行いました。この場合、クエリーは3つ走ります。え!2つじゃないの? 中身を見ていきましょう。


1つ目の SQL がなぜ実行されたのか? Tableau が内部的に必要としているのではないかと思われますが、よく解りません。後にパフォーマンスの考察で調べてみたいと思っています。ここでは、2つ目と、3つ目を見ていきましょう。
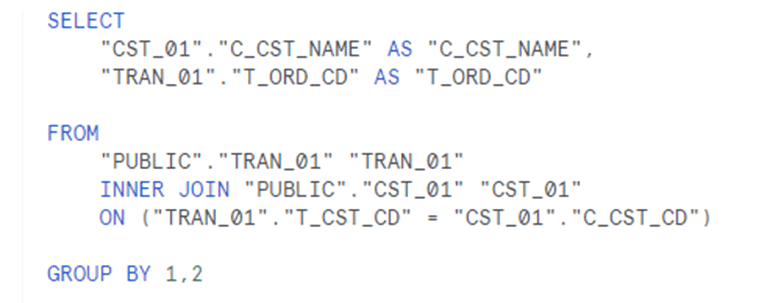
両方のテーブルの数値が集計されているので2つのクエリーが実行されることは既にお伝えしていますが、よく見ると、その3でご説明したSQLと異なっていることにお気づきでしょうか?
その3では、リレーションキーを使用しての完全外部結合を行っています。その場合より複雑になっています。ここで着目しておきたいのは、内側の FROM句が LEFT JOINになっている点です。
② 一部のレコードが一致 対 すべてのレコードが一致 の場合
1つ目、2つ目の SQL は同じです。CST_01 テーブル側を「すべてのレコードが一致」にすることによって、3つ目の SQL が変化しています。
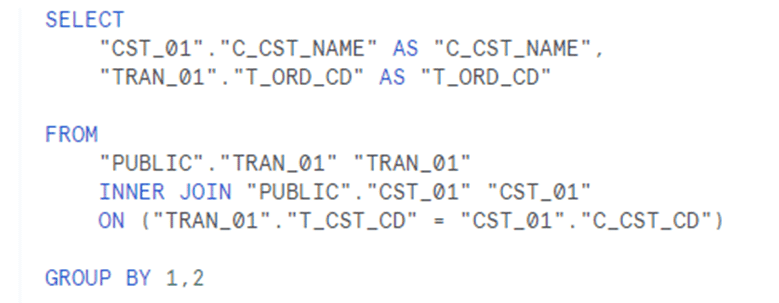


3つ目の SQL (CST_01側) は、先ほど確認した内側の FROM句が INNER JOIN に変わっています。即ち、この時点で、TRAN_01 にない、CST_CD: "e" は除外されることになります。従って、クエリー結果には、CST_NAME: "name e" は出現しません。 もう一つの違いは、外側の INNER JOIN で … IS NOT DISTINCT FROM … がなくなっていること。詳しい説明は省きますが、INNER JOIN を使用しているので、null を考慮する必要性がなくなった、ということだと思います。
③ すべてのレコードが一致 対 一部のレコードが一致 の場合
ここで予想外の動きが起こりました。SQLが2つしか発行されません。先ほどまであった1つ目のクエリーがなくなりました。まだ正確には理由が解っていませんので、これはまた別の機会に検証してみたいと思います。


他は予想通り、1つ目の SQL (TRAN_01側) の内側の FROM句が INNER JOIN になりました。但し、TRAN_01 に対して CST_01 が INNER JOIN されています。INNER JOIN なので、どちらが先でも同じ結果になるのですが、この辺りも気になる変化です。
③ すべてのレコードが一致 対 すべてのレコードが一致 の場合
また3つの SQL が走りました。



どちらも、内側の FROM句がシンプルになっています。どちらも すべてのレコードが一致 にした場合、内部結合をすれば良く、SQL が簡素化されたと言えます。
参照整合で何が行われているか?を見てみると、意外なことが解りました。両方のテーブルにある数値を集計結果として表示しているので、リレーションシップでは、最低2つの クエリーが実行されますが、参照整合が すべてのレコードが一致 対 すべてのレコードが一致 の場合、SQL がシンプルです。即ち、この状態が一番パフォーマンス的に良いと言えます。ならば、データ元を整備し、極力この状態に持っていったほうが Tableau のパフォーマンスが上がってくる、と言えるのではないでしょうか? だからこそ、データの準備は大切なんですね。もちろん、用途によっては、左結合、右結合、完全外部結合にしなくてはならない場合もありますが、極力内部結合に持っていったほうがパフォーマンスは出ます。
Tableau は、リレーションシップのカーディナリティと参照整合で「設定がよくわからない場合は既定の設定をお勧めします」と説明しています。既定の設定でもちゃんと動くように設計されています。しかしながら、設定がよく解かっていれば、データがどんな状況なのかをしっかり把握できれば、利用目的に応じて適切なパフォーマンスオプションの設定を行ったほうが良い、とも言えます。
次回は、カーディナリティを変えてテストしてみます。