
酵素活性データを例にした棒グラフの描画(Matplotlib, Seaborn)

バイオ実験で出てきそうな酵素活性を測定した実験データをmatplotlibとseabornで棒グラフにする例を書き留める。
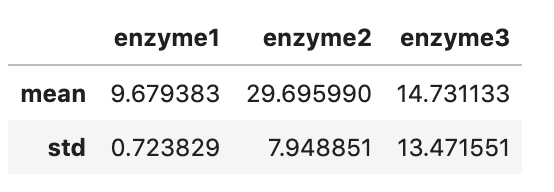
(データ例の概要)酵素1-3の酵素活性を3回繰り返し測定したデータ(下表)。
平均値,標準偏差を計算後, matplotlib, seabornの両方で棒グラフを描く

データの準備
# import modules
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
a,b,c = [],[],[]
for i in range(1,4):
np.random.seed(i)
a.append(np.random.uniform(5,15))
b.append(np.random.uniform(20,40))
c.append(np.random.uniform(1,50))
data_df =pd.DataFrame({'experiment':[1,2,3],'enzyme1':a,'enzyme2':b,'enzyme3':c})
print("sample1-3の酵素活性測定結果:")
display(data_df) 
平均値(mean), 標準偏差(SD)の計算
meansd_df=data_df.describe().loc[['mean', 'std'],:].
drop('experiment', axis = 1) # (1)
display(meansd_df)(1) np.mean()やnp.std()でも計算できるが,describe()で出力される統計データ一覧から,'mean'と'std'を取り出し表示。
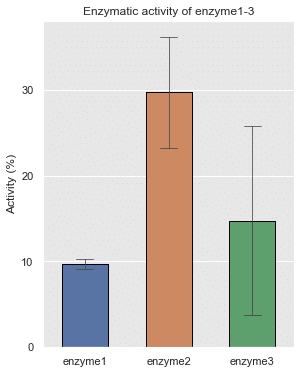
Matplotlibの Axes.barで棒グラフを描画
sns.set()
sns.set_style('darkgrid',{"axes.facecolor": ".9"}) # (1)
sns.set_context('notebook')
fig, ax = plt.subplots(figsize = (4.5,6))
x = meansd_df.columns
y = meansd_df.loc['mean',:]
yerr = meansd_df.loc['std',:]
width = 0.45
for i, j,k in zip(x,y,yerr): # (2)
ax.bar(i,j, width, yerr = k, edgecolor = "black",
error_kw=dict(lw=1, capsize=8, capthick=1)) # (3)
ax.set(ylabel = 'Activity (%)', title = 'Enzymatic activity of enzyme1-3')
#yticksを10刻みに
from matplotlib import ticker
ax.yaxis.set_major_locator(ticker.MultipleLocator(10)) (1)この色が最近好きなので指定: 'darkgrid',{"axes.facecolor": ".9"}
(2)loopで1変数ずつ指定してグラフを書くと各棒の色が変わるということに気づいたのでループで処理(ループしなくてももちろん描画できる)。
(3)error bar の太さは error_kw= dict(lw= , capsize = ,capthick = ) で指定。

Seabornの sns.barplot()でグラフを描画
Seabornでグラフを書くときは上記のようなテーブルではなく,列が全て変数のいわゆる"tidy"なテーブルに変換することが必要。なので,pd.melt()で各カラムに独立した一つの変数が入ったデータフレームに変換してからseabornでグラフを描画する。そうすることで,Seabornが自動で平均値(mean)と標準偏差(sd)を計算してグラフ上に出力してくれる。
data_melt = pd.melt(data_df, id_vars='experiment', var_name='samplename',
value_name='activity')
display(data_melt)
・id_vars :そのまま残す変数: 'experiment'
・var_name : meltするvariant(sample1-2)につける名前を指定: 'samplename'
・value_name : meltするvalues(数値)につける名前を指定: 'activity'

Seaborn sns.barplotで描画
# sns.barplotで描画
sns.set()
sns.set_style('darkgrid',{"axes.facecolor": ".9"})
sns.set_context('notebook')
fig, ax = plt.subplots(figsize = (4.5,6))
ax = sns.barplot(x='samplename', y = 'activity', data = data_melt,
edgecolor="black", ci='sd', capsize=.2, errwidth=.75) # (1)
ax.set(ylabel='Activity (%)', xlabel = '' ,
title = 'Enzymatic activity of enzyme1-3')
#yticksを10刻みに
from matplotlib import ticker
ax.yaxis.set_major_locator(ticker.MultipleLocator(10))
#グラフの太さを指定 # (2)
#### Set these based on your column counts
columncounts = [55,55,55]
# Maximum bar width is 1. Normalise counts to be in the interval 0-1. Need to supply a maximum possible count here as maxwidth
def normaliseCounts(widths,maxwidth):
widths = np.array(widths)/float(maxwidth)
return widths
widthbars = normaliseCounts(columncounts,100) #それぞれの軸の%をだす [55,55,55]だと55/100 (0.55)
# Loop over the bars, and adjust the width (and position, to keep the bar centred)
for bar,newwidth in zip(ax.patches,widthbars):
x = bar.get_x()
width = bar.get_width()
centre = x+width/2.
bar.set_x(centre-newwidth/2.)
bar.set_width(newwidth)
(1)
・標準偏差を出すためにci で誤差の種類を'sd'に指定
・edgecolor:棒グラフの枠線を指定
・capsize :エラーバーの横棒部分の長さを指定
・errwidth: エラーバーの線の太さを指定
(2)sns.barplot()では,かく棒の太さ(width)を指定出来ないみたいっぽい。ネットで見つけた関数を利用して太さを調節。
方法は棒の本数分太さの比を値を[カッコ ]内に入れて指定(ソースは下記)。
https://stackoverflow.com/questions/36824229/how-to-set-width-on-seaborn-barplot
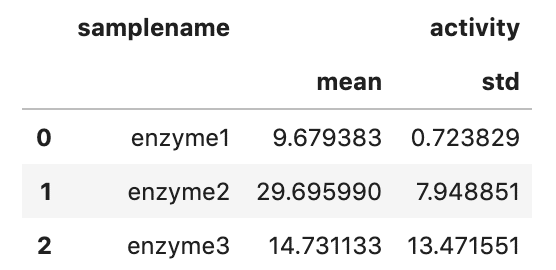
データから平均,標準偏差をgroupby と aggを使って計算
一応練習としてpd.meltで作成したdata_meltからそれぞれの平均を算出する
# Caluculate mean and std
meanstd = data_melt.groupby(['samplename'], as_index=False).agg({'activity': [np.mean, np.std]})
display(meanstd)agg : 辞書で{'計算するcolum': [計算方法(np.mean, np.sd, np.median, max, min etc..)]を指定できる。
(おまけ)multicolumnでのデータの指定方法
multicolumnはデータを指定するときに二重括弧[[]]で囲まないと,dataframeではなくseriesとして出力されてしまう。
print('samplename:')
display(meanstd[['samplename']]) # multicolumnなので[[]]にする
print('mean:')
display(meanstd['activity'][['mean']]) # multicolumnなので[[]]にする
print('std:')
display(meanstd['activity'][['std']]) # multicolumnなので[[]]にする
おしまい