
Python + ESPNetをCityscapesデータセットで学習する

セマンティックセグメンテーションの中で軽いモデルであるESPNetv2を実装します.
本稿ではまず,デモの起動と公開データセットのCityscapesでの学習を実施します.
今回はGoogle ColabとGoogle Driveを連携させて,notebook形式で実行してます.
Google Colaboratory(以下Google Colab)は、Google社が無料で提供している機械学習の教育や研究用の開発環境です。開発環境はJupyter Notebookに似たインターフェースを持ち、Pythonの主要なライブラリがプリインストールされています。
引用元:Google Colabの使い方(opens new window)
最終的に,人以外の背景を着色して,zoomのバーチャル背景機能のようなクロマキー合成を実装したいです.

本稿の成果物

ファイル構成
プロジェクトディレクトリはsegmentationとしています.度々,省略しています.
segmentation
├── /EdgeNets
│ ├── /data_loader
│ │ └── /segmentation
│ │ ├── /scripts
│ │ │ ├── download_cityscapes.sh
│ │ │ └── (省略)
│ │ └── /cityscape_script
│ │ ├── process_cityscapes.py <- コピー元
│ │ ├── generate_mappings.py <- コピー元
│ │ └── (省略)
│ ├── /sample_images <- サンプル画像
│ ├── /results_segmentation <- モデルの出力ディレクトリ
│ ├── /result_images <- 着色画像の出力ディレクトリ
│ ├── /vision_datasets
│ │ └── /cityscapes <- cityscapesデータセット
│ ├── segmentation_demo.py
│ ├── train_segmentation.py
│ ├── test_segmentation.py
│ ├── process_cityscapes.py <- コピー先
│ ├── generate_mappings.py <- コピー先
│ ├── custom_test_segmentation.py <- 新規作成
│ └── (省略)
└── ESPNetv2.ipynb <- 実行用ノートブックEdgeNets(ESPNetv2)
EdgeNetsのダウンロード
Google ColabとGoogle Driveを連携させて,gitからESPNetv2を内包しているEdgeNets (opens new window)をダウンロードします.
segmentationの解説はREADME_Segmentation.mdに記載されています.
# Google ColabとGoogle Driveを連携
from google.colab import drive
drive.mount('/content/drive')# ディレクトリの移動
%cd /content/drive/My Drive/segmentation
# gitのダウンロード
!git clone https://github.com/sacmehta/EdgeNets.gitEdgeNetsの起動チェック
正常に起動するか,デフォルトで入っているデモコードでチェックします.
# ディレクトリの移動
%cd EdgeNets
# デモコード
python segmentation_demo.py上記のコードを実行すると,/segmentation_resultsに着色された画像が出力されます.
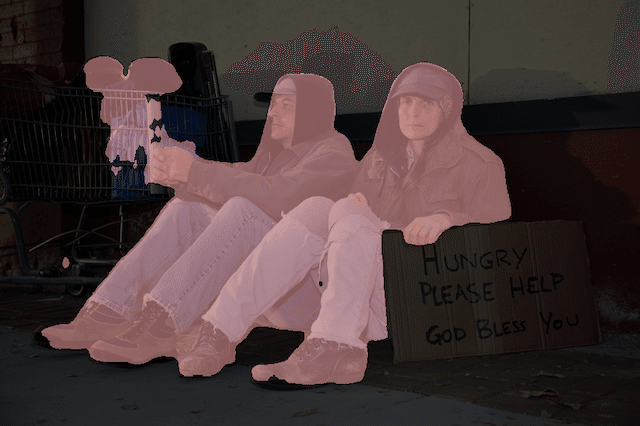
Cityscapesデータセットで学習デモ
本稿ではまず,Cityscapesという街中の景色のデータセットでespnetv2の学習を実施します.
Cityscapesデータセットのダウンロード
Cityscapesデータセットをダウンロードするには,まずCityscapesのサイト (opens new window)に登録する必要があります.
そして,./EdgeNets/data_loader/segmentation/scripts/download_cityscapes.shに登録したアドレスとパスワードを記入します.
# download_cityscapes.sh
# 8~10行目
# enter user details
uname='登録したアドレス'
pass='登録したパスワード'以下のコマンドを実行し, Cityscapesデータセットをダウンロードします.
%%bash
# 現在ディレクトリ:/content/drive/My\ Drive/segmentation/EdgeNets
# ディレクトリの移動
cd ./data_loader/segmentation/scripts
# ダウンロード実行
sh download_cityscapes.shCityscapesデータセットを学習用にマスキング
学習のためにCityscapesセグメンテーションマスクで処理する必要があります.
sacmehta/EdgeNets/README_Segmentation.md (opens new window)に記述されているコマンドをそのまま実行すると,エラーが発生しますので「process_cityscapes.pyとgenerate_mappings.py」を./EdgeNets直下に置きます.
%%bash
# 現在ディレクトリ:/content/drive/My\ Drive/segmentation/EdgeNets
# cp <移動前> <移動先>
# process_cityscapes.pyを/EdgeNets直下にコピー
cp data_loader/segmentation/cityscape_scripts/process_cityscapes.py process_cityscapes.py
# process_cityscapes.pyを/EdgeNets直下にコピー
cp data_loader/segmentation/cityscape_scripts/generate_mappings.py generate_mappings.py「process_cityscapes.pyとgenerate_mappings.py」の場所を変えたので,それに応じて読み込む場所の記述も書き換えます.
# process_cityscapes.py
# 486行目
cityscapes_path = './vision_datasets/cityscapes/'
# generate_mappings.py
# 70行目
cityscapes_path = './vision_datasets/cityscapes/'以下のコマンドでマスキングを実行します.
%%bash
# 現在ディレクトリ:/content/drive/My\ Drive/segmentation/EdgeNets
# セグメンテーションマスキング
python process_cityscapes.py
python generate_mappings.py学習の第1段階
最初の段階では、低解像度の画像を入力として使用して,より大きなバッチサイズに合わせることができます.
学習したモデルは/results_segmentation内に格納されます.
%%bash
# 現在ディレクトリ:/content/drive/My\ Drive/segmentation/EdgeNets
# Cityscapes dataset
!CUDA_VISIBLE_DEVICES=0 python train_segmentation.py \
--model espnetv2 \
--s 2.0 \
--dataset city \
--data-path ./vision_datasets/cityscapes/ \
--batch-size 25 \
--crop-size 512 256 \
--lr 0.009 \
--scheduler hybrid \
--clr-max 61 \
--epochs 50学習の第2段階
第2段階では、バッチ正規化レイヤーをフリーズしてから,わずかに高い画像解像度で微調整します.
学習したモデルは/results_segmentation内に格納されます.
%%bash
# 現在ディレクトリ:/content/drive/My\ Drive/segmentation/EdgeNets
# Cityscapes dataset
CUDA_VISIBLE_DEVICES=0 python train_segmentation.py \
--model espnetv2\
--s 2.0 \
--dataset city \
--data-path ./vision_datasets/cityscapes/ \
--batch-size 6 \
--crop-size 1024 512 \
--lr 0.005 \
--scheduler hybrid \
--clr-max 61 \
--epochs 30 \
--freeze-bn \
--finetune results_segmentation/model_espnetv2_city/s_2.0_sch_hybrid_loss_ce_res_512_sc_0.25_0.5/****/espnetv2_2.0_512_best.pthCityscapesデータセットでテスト
/sample_imagesの画像でテストを実施します.
test_segmentation.pyの改良
そこで任意のディレクトリでsegmentationできるようにtest_segmentation.pyを改良して,custom_test_segmentation.pyを作成します.
# ./EdgeNets/model/segmentation/espnetv2.py
# 36行目付近
dec_feat_dict={
'pascal': 16,
'city': 16,
'coco': 32,
'custom': 16
}custom_test_segmentation.pyでは元コードから以下のように若干いじっています.
・入力画像の読み込みを,「.png・.jpg・.jpeg」に対応させた.
・入力画像の読み込みを任意のディレクトリに指定できるようにした.
・出力画像を「背景黒の着色画像」から「元画像と直色画像の合成」に変更した.
・出力画像の着色の仕方を固定のカラーマップからクラス数で変更できるようにした.
・出力画像の保存先を./result_images/<任意のディレクトリ名>に変更した.
「コマンドラインの引数を変更」
・dataset::任意のデータでsegmentationできるように「custom」を追加
・split :任意のデータでsegmentationできるように「custom」を追加.,
・savedir-name:任意の任意のディレクトリ名で保存できるようにしました
# custom_test_segmentation.py
import torch
import glob
import os
from argparse import ArgumentParser
from PIL import Image
from torchvision.transforms import functional as F
from tqdm import tqdm
from utilities.print_utils import *
from transforms.classification.data_transforms import MEAN, STD
from utilities.utils import model_parameters, compute_flops
# ===========================================
__author__ = "Sachin Mehta"
__license__ = "MIT"
__maintainer__ = "Sachin Mehta"
# ============================================
IMAGE_EXTENSIONS = ['.jpg', '.png', '.jpeg']
def data_transform(img, im_size):
img = img.resize(im_size, Image.BILINEAR)
img = F.to_tensor(img) # convert to tensor (values between 0 and 1)
img = F.normalize(img, MEAN, STD) # normalize the tensor
return img
def evaluate(args, model, image_list, device):
im_size = tuple(args.im_size)
# get color map for dataset
from utilities.color_map import VOCColormap
cmap = VOCColormap(num_classes=args.num_classes).get_color_map_voc()
print(cmap)
model.eval()
for i, imgName in tqdm(enumerate(image_list)):
img = Image.open(imgName).convert('RGB')
img_clone = img.copy()
w, h = img.size
img = data_transform(img, im_size)
img = img.unsqueeze(0) # add a batch dimension
img = img.to(device)
img_out = model(img)
img_out = img_out.squeeze(0) # remove the batch dimension
img_out = img_out.max(0)[1].byte() # get the label map
img_out = img_out.to(device='cpu').numpy()
img_out = Image.fromarray(img_out)
# resize to original size
img_out = img_out.resize((w, h), Image.NEAREST)
# pascal dataset accepts colored segmentations
img_out.putpalette(cmap) # クラスごとに着色
img_out = img_out.convert('RGB')
blended = Image.blend(img_clone, img_out, alpha=0.7)
# save the segmentation mask
name = imgName.split('/')[-1]
img_extn = imgName.split('.')[-1]
name = '{}/{}'.format(args.savedir, name.replace(img_extn, 'png'))
blended.save(name)
def main(args):
# read all the images in the folder
if args.dataset == 'custom':
if args.split in ['train', 'val', 'test']:
image_list = []
for extn in IMAGE_EXTENSIONS:
image_path = os.path.join(args.data_path, args.split, "rgb", '*' + extn)
image_list = image_list + glob.glob(image_path)[0:50]
seg_classes = args.num_classes
elif args.split == 'custom':
image_list = []
for extn in IMAGE_EXTENSIONS:
image_path = os.path.join(args.data_path, '*' + extn)
image_list = image_list + glob.glob(image_path)
seg_classes = args.num_classes
else:
print_error_message('{} split not yet supported'.format(args.split))
else:
print_error_message('{} dataset not yet supported'.format(args.dataset))
if len(image_list) == 0:
print_error_message('No files in directory: {}'.format(image_path))
print_info_message('# of images for testing: {}'.format(len(image_list)))
if args.model == 'espnetv2':
from model.segmentation.espnetv2 import espnetv2_seg
args.classes = seg_classes
model = espnetv2_seg(args)
elif args.model == 'dicenet':
from model.segmentation.dicenet import dicenet_seg
model = dicenet_seg(args, classes=seg_classes)
else:
print_error_message('{} network not yet supported'.format(args.model))
exit(-1)
# mdoel information
num_params = model_parameters(model)
flops = compute_flops(model, input=torch.Tensor(1, 3, args.im_size[0], args.im_size[1]))
print_info_message('FLOPs for an input of size {}x{}: {:.2f} million'.format(args.im_size[0], args.im_size[1], flops))
print_info_message('# of parameters: {}'.format(num_params))
if args.weights_test:
print_info_message('Loading model weights')
weight_dict = torch.load(args.weights_test, map_location=torch.device('cpu'))
model.load_state_dict(weight_dict)
print_info_message('Weight loaded successfully')
else:
print_error_message('weight file does not exist or not specified. Please check: {}', format(args.weights_test))
num_gpus = torch.cuda.device_count()
device = 'cuda' if num_gpus > 0 else 'cpu'
model = model.to(device=device)
evaluate(args, model, image_list, device=device)
if __name__ == '__main__':
from commons.general_details import segmentation_models, segmentation_datasets
parser = ArgumentParser()
# mdoel details
parser.add_argument('--model', default="espnetv2", choices=segmentation_models, help='Model name')
parser.add_argument('--weights-test', default='', help='Pretrained weights directory.')
parser.add_argument('--s', default=2.0, type=float, help='scale')
# dataset details
parser.add_argument('--data-path', default="", help='Data directory')
parser.add_argument('--dataset', default='custom', choices=['custom'], help='Dataset name')
# input details
parser.add_argument('--im-size', type=int, nargs="+", default=[512, 256], help='Image size for testing (W x H)')
parser.add_argument('--split', default='val', choices=['train', 'val', 'test', 'custom'], help='data split')
parser.add_argument('--model-width', default=224, type=int, help='Model width')
parser.add_argument('--model-height', default=224, type=int, help='Model height')
parser.add_argument('--channels', default=3, type=int, help='Input channels')
parser.add_argument('--num-classes', default=20, type=int,
help='ImageNet classes. Required for loading the base network')
parser.add_argument('--savedir-name', default='demo', type=str,
help='Save folder location')
args = parser.parse_args()
if not args.weights_test:
from model.weight_locations.segmentation import model_weight_map
model_key = '{}_{}'.format(args.model, args.s)
dataset_key = '{}_{}x{}'.format(args.dataset, args.im_size[0], args.im_size[1])
assert model_key in model_weight_map.keys(), '{} does not exist'.format(model_key)
assert dataset_key in model_weight_map[model_key].keys(), '{} does not exist'.format(dataset_key)
args.weights_test = model_weight_map[model_key][dataset_key]['weights']
if not os.path.isfile(args.weights_test):
print_error_message('weight file does not exist: {}'.format(args.weights_test))
# set-up results path
if args.dataset == 'custom':
if args.split in ['train', 'val', 'test']:
args.savedir = 'results_images/{}_{}'.format(args.dataset, args.split)
elif args.split == 'custom':
args.savedir = 'results_images/{}'.format(args.savedir_name)
else:
print_error_message('{} split not yet supported'.format(args.split))
else:
print_error_message('{} dataset not yet supported'.format(args.dataset))
if not os.path.isdir(args.savedir):
os.makedirs(args.savedir)
# This key is used to load the ImageNet weights while training. So, set to empty to avoid errors
args.weights = ''
main(args)テストの実行
以下のコマンドでテストを実行します.
以下のコマンドでは,pascalとcityscapesの公開学習済みモデルを使っていますが,--weights-testから任意のモデルを指定することができます.
%%bash
# 現在ディレクトリ:/content/drive/My\ Drive/segmentation/EdgeNets
# Cityscapes molel
CUDA_VISIBLE_DEVICES=0 python custom_test_segmentation.py \
--model espnetv2 \
--s 2.0 \
--dataset custom \
--data-path ./sample_images/ \
--split custom \
--im-size 1024 512 \
--num-classes 20 \
--weights-test model/segmentation/model_zoo/espnetv2/espnetv2_s_2.0_city_1024x512.pth \
--savedir-name sample_images_city%%bash
# Pascal model
CUDA_VISIBLE_DEVICES=0 python custom_test_segmentation.py \
--model espnetv2 \
--s 2.0 \
--dataset custom \
--data-path ./sample_images/ \
--split custom \
--im-size 384 384\
--num-classes 21 \
--weights-test model/segmentation/model_zoo/espnetv2/espnetv2_s_2.0_pascal_384x384.pth \
--savedir-name sample_images_pascalテストの結果
以下がpascalとcityscapes,それぞれの学習済みモデルで直色した画像です.
人単体でやるならば,pascalの方がいいようです.
オリジナル画像

cityscapesモデルの着色画像

pascalモデルの着色画像

まとめ
本稿ではSemantic Segmentationの中で軽いモデルであるESPNetv2の,デモの起動と公開データセットのCityscapesでの学習を実施しました.
デフォルトのコードでは若干不便なところもあったので,逐次改造したコードを作成しています.
次回からはオリジナルデータで学習することも想定しつつ,人だけを着色するモデルの学習を実施します.
参考サイト
ここから先は
¥ 100
この記事が気に入ったらサポートをしてみませんか?