Python + ESPNetをオリジナルデータで学習する(データ生成編)

セマンティックセグメンテーションの中で軽いモデルであるESPNetv2を実装します.
本稿ではCityscapesデータセットから人のみを抽出して,仮のオリジナルデータで学習に向けて,データ生成を実施します.
有料枠設定にしていますが,下記のサイトで無料でみれます.youtubeの投げ銭的な物として,お考えください.
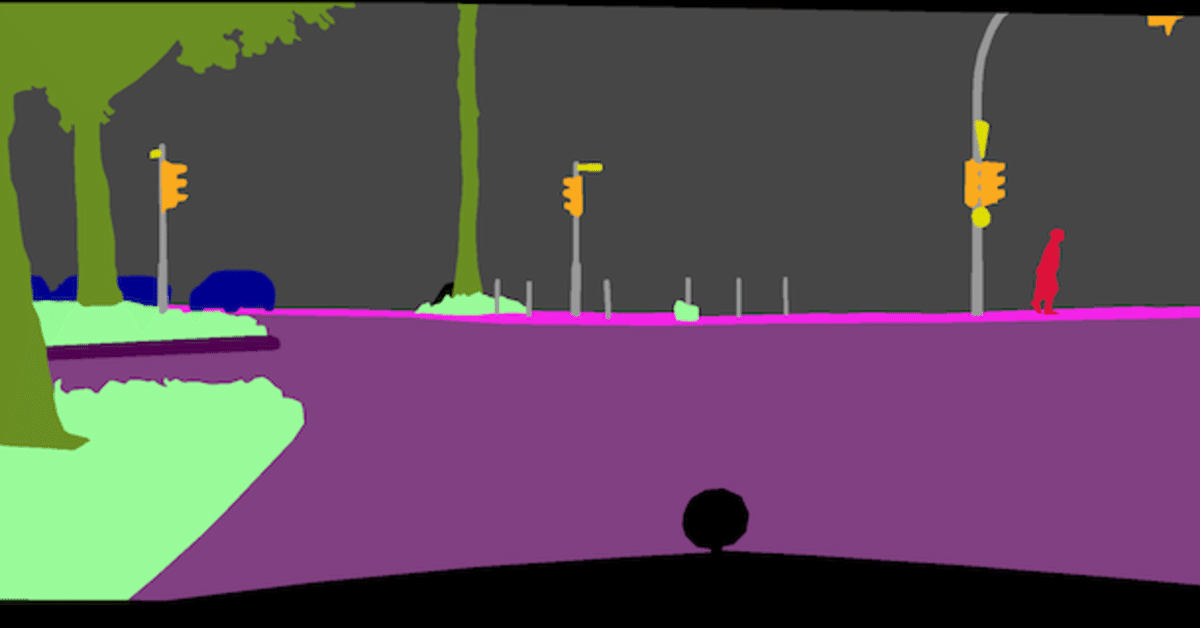
本稿の成果物のイメージ

作業ディレクトリのファイル構成
ここでは,作業ディレクトリのsegmentation/EdgeNets/vision_datasetsのファイル構成を以下に示します.
segmentation/EdgeNets/vision_datasets
├── /cityscapes
├── /human_city <- 仮オリジナルデータ
│ ├── train.txt
│ ├── val.txt
│ ├── /images
│ │ ├── /train
│ │ │ └── オリジナル画像
│ │ └── /val
│ │ └── オリジナル画像
│ └── /annotations
│ ├── /train
│ │ └── マスキング画像
│ └── /val
│ └── マスキング画像
│
└── create_data.ipynb <- データ生成用ノートブックオリジナルデータの学習データセット
今回はCityscapesデータセットから人だけを抽出して,仮オリジナルデータとします.
オリジナルデータでESPNetv2を学習する場合は,データセットのファイル構成は以下の通りです.
ここでは,データセット名前をhuman_cityとしています.
/human_city
├── train.txt
├── /images
│ ├── /train
│ │ └── オリジナル画像
│ └── /val
│ └── オリジナル画像
├── val.txt
└── /annotations
├── /train
│ └── マスキング画像
└── /val
└── マスキング画像オリジナル画像は実際の風景画像で,マスキング画像はクラスのIDに応じたRGBでマスキングした画像です.
例として,背景はRGB=(0, 0, 0),人のクラスIDが1とするならば人の領域はRGB=(1, 1, 1),車のクラスIDが2とするならば車の領域はRGB=(2, 2, 2)として,マスキング画像を作成する.
RGB=(0, 0, 0)の領域とRGB=(1, 1, 1)の領域は肉眼では判別不可能なので,最初は確認のためRGB=(0, 0, 255)など目立つ色で作成して,学習用に色を置換する方が個人的にお勧めします.
オリジナル画像

人をRGB=(1, 1, 1)のマスキング画像(学習用)
※肉眼じゃわからん・・・

人をRGB=(255, 0, 0)のマスキング画像(確認用)

仮オリジナルデータの生成
Cityscapesデータセットから人だけを抽出して,仮オリジナルデータを生成します.
Cityscapesデータセットのダウンロードは,Python, ESPNetでCityscapesデータセットでSemantic Segmentationの学習を実施する (opens new window)を参照ください.
作業ディレクトリの移動
作業ディレクトリは,Cityscapesデータセットのダウンロードで自動で生成される/EdgeNets/vision_datasetsとしています.
# Google ColabとGoogle Driveを連携
from google.colab import drive
drive.mount('/content/drive')# ディレクトリの移動
%cd /content/drive/My\ Drive/segmentation/EdgeNets/vision_datasetsCityscapesデータセットの整理
仮オリジナルデータの生成について,Cityscapesデータセットからオリジナル画像とカラーマスキング画像を使用します.
Cityscapesデータセットは,オリジナル画像とカラーマスキング画像は,以下の画像名となっています.
オリジナル画像:/cityscapes/leftImg8bit/train or val/*/*_leftImg8bit.png
カラーマスキング画像:/cityscapes/gtFine/train or val/*/*_gtFine_color.png
オリジナル画像

カラーマスキング画像

入力画像のリスト作成
画像を読み込ませるために,画像パスリストのtxtファイルも作成する必要があります.(train.txt, val.txt)
# train.txt, val.txt
# オリジナル画像, マスキング画像
train/rgb/zurich_000072_000019_leftImg8bit.png,train/label/zurich_000072_000019_gtFine_color.png
train/rgb/zurich_000003_000019_leftImg8bit.png,train/label/zurich_000003_000019_gtFine_color.png
train/rgb/zurich_000116_000019_leftImg8bit.png,train/label/zurich_000116_000019_gtFine_color.png
train/rgb/zurich_000119_000019_leftImg8bit.png,train/label/zurich_000119_000019_gtFine_color.png
train/rgb/zurich_000032_000019_leftImg8bit.png,train/label/zurich_000032_000019_gtFine_color.png仮オリジナルデータ生成の工程
人を抽出する工程は,カラーマスキング画像の色を,人以外をBGR(0, 0, 0),人をBGR(1, 1, 1)に置換して実施してます.
カラー画像で特定の色を置換する場合は,本サイトの「Python, OpenCVで指定した色の抽出と別の色への置換を実装する (opens new window)」を参照ください.
以下のコードでは一通りの工程をdef文でまとめました.
import os
import glob
import shutil
import cv2
import numpy as np
# 学習データセットのディレクトリの作成
def make_dataset_dir(dataset_name):
os.makedirs('{}/images/train/'.format(dataset_name), exist_ok=True) # 訓練用オリジナル画像
os.makedirs('{}/annotations/train/'.format(dataset_name), exist_ok=True) # 訓練用マスキング画像
os.makedirs('{}/images/val/'.format(dataset_name), exist_ok=True) # 評価用オリジナル画像
os.makedirs('{}/annotations/val/'.format(dataset_name), exist_ok=True) # 評価用マスキング画像
# オリジナル画像をコピー
def copy_org_image(color_image_path, data_type, dataset_name):
# カラーマスキング画像の名前
color_name = os.path.basename(color_image_path)
# データのディレクトリ名(データを取得した都市名)
city_name = color_name.split('_')[0]
# オリジナル画像の名前とパス
org_name = color_name.replace('_gtFine_color.png', '_leftImg8bit.png')
org_path = './cityscapes/leftImg8bit/{0}/{1}/{2}'.format(data_type, city_name, org_name)
# オリジナル画像をコピー
shutil.copy(org_path, './{0}/images/{1}/{2}'.format(dataset_name, data_type, org_name))
return '{0}/{1}'.format(data_type, org_name)
# 画像の特定の色を抽出
def color_extract(cv2_img, color1):
# BGRでの色抽出
bgrLower = np.array(color1) # 抽出する色の下限(BGR)
bgrUpper = np.array(color1) # 抽出する色の上限(BGR)
img_mask = cv2.inRange(cv2_img, bgrLower, bgrUpper) # BGRからマスクを作成
ex_img = cv2.bitwise_and(cv2_img, cv2_img, mask=img_mask) # 元画像とマスクを合成
return ex_img
# 画像の特定の色を別の色に置換
def color_replace(ex_img, color1, color2):
before_color = color1
after_color = color2
ex_img[np.where((ex_img == before_color).all(axis=2))] = after_color
return ex_img
# 学習用マスキング画像を出力
def replace_masking(cv2_img, data_type, dataset_name, color1, color2):
# 学習用マスキング画像を生成
ex_img = color_extract(cv2_img, color1)
mask_img = color_replace(ex_img, color1, color2)
# グレースケール化
mask_img_gray = cv2.cvtColor(mask_img, cv2.COLOR_BGR2GRAY)
# マスキング画像の出力
color_name = os.path.basename(color_image)
mask_path = './{0}/annotations/{1}/{2}'.format(dataset_name, data_type, color_name)
cv2.imwrite(mask_path, mask_img_gray)
return '{0}/{1}'.format(data_type, color_name)
# パスリストのtxtファイル作成
def create_txtfile(txt_path, txt, txt_flag):
# 新規作成
if not txt_flag:
with open(txt_path, mode='w') as f:
f.write(txt)
# 追記
else:
with open(txt_path, mode='a') as f:
f.write(txt)
return 1仮オリジナルデータ生成の実行
以下のコードで仮オリジナルデータ生成を実行します.
cityscapesScripts/cityscapesscripts/helpers/labels.py (opens new window)より人のマスキングのRGBは(220, 20, 60)となります.
カラーマスキング画像を読み込んで,人のRGB=(220, 20, 60)の箇所があれば,学習用データセットとして整形するようにしています.
import os
import glob
import cv2
import numpy as np
# 学習データセットのディレクトリの作成
dataset_name = 'human_city'
make_dataset_dir(dataset_name)
# Cityscapes
data_type = 'train'
# カラーマスキング
color_images = glob.glob('./cityscapes/gtFine/{}/*/*_gtFine_color.png'.format(data_type))
# 人のマスキングカラー(BGR)
human_color = [60, 20, 220]
label_color = [1, 1, 1]
txt_flag = 0
for color_image in color_images:
# カラーマスキング画像の読み込み
img = cv2.imread(color_image)
# 人の色があるか,判定
if len(img[np.where((img == human_color).all(axis=2))]) > 0:
# 学習用マスキング画像を出力
txt_mask_path = replace_masking(img, data_type, dataset_name, human_color, label_color)
# オリジナル画像をコピー
txt_org_path = copy_org_image(color_image, data_type, dataset_name)
# パスリストのtxtファイル作成
txt_path = './{0}/{1}.txt'.format(dataset_name, data_type)
txt = '{0},{1}\n'.format(txt_org_path, txt_mask_path)
txt_flag = create_txtfile(txt_path, txt, txt_flag)まとめ
Cityscapesデータセットから人のみを抽出して,仮のオリジナルデータで学習に向けて,データ生成を実施しました.
次回からは本稿の仮オリジナルデータでの学習を実施します.
参考サイト
ここから先は
¥ 100
この記事が気に入ったらチップで応援してみませんか?