
カンタンに機械学習で株価分析・予測

いくつかアイデアはあるんだけど、
Pythonで簡単にできる事は、やり尽くした感がある。
そこで、新境地を開拓すべく機械学習で株価分析・予測する領域に一歩足を踏み入れてみた。
しかし、なにかと壁が高い。
なんやら、わからない用語が飛び交うのである。サポートベクターマシーンとかいう強そうな覆面レスラーのような名前が出てきたり、教師あり学習、教師なし学習とかいう用語が出てきたりする。
私が小さい時は、教師いなくてもちゃんと自習したし、「機械も教師が不在でも、ちゃんと勉強してほしい」ものである。なんなら、悪い大人を見本にして「反面教師学習」をしてほしいものである。と、機械相手に説教しだしたら、おしまいである。
そんな事を考えているうちに、眠くなってぐっすり寝れるのである。
あーこれが、Deep Learningなのかもしれない。
機械学習は難しく、眠気に襲われ、壁が高い。
でも何か違う。
機械学習は本来「機械が学習して楽ちんになるはず」なのに、「なぜ人間の私が学習して苦労しているのか」これでは立場が逆転していて本末転倒ではないか!と、ヒューマンである私はフマン♪。と韻を踏んだところで読者のガマン♪も限界だと思うので本題に入ろう。
なんやら、PyCaretを使えば簡単に機械学習ができそうなのである。
という事で、PyCaretを使い「経済指標と株価の関係」を機械学習で分析・予測してみた。
プログラムで株価予測をしている人は結構いるのだけど、個別株の出来高とかテクニカルを意識したものが多い。株の知識とプログラムスキルがあるだけでもたいしたものではあるんだけど、全体の視点というか、経済の視点・ファンダメンタルズの視点で分析しているものは少ない様に思われる。
そこで、「株の知識」✖️「プログラムスキル」✖️「経済知識」を駆使して、巷に溢れるものとは一線を画した分析をしてみようと思う。
注意:と偉そうに言ってみたものの私のパイソンのスキルなんて素人に毛が生えたぐらいのものである。省略して言うと「パイ○ンに毛が生えた程度」である。特に機械学習は始めたばかりなので、そういう、毛が生えているのか生えてないのかよくわからない程度のスキルなので、間違いがあるかもしれません。
1.必要ライブラリのインストール
pip install pycaretPycaretのインストール(少し時間がかかる)
pip install japanize_matplotlib日本語ライブラリのインストール(なくても良い。)
pip install yfinance株価取得ライブラリのインストール
2.データ取得処理
S&P500の株価と関係性を知りたい指標を取得する。
関係性を知りたい指標
金利(2年、5年、10年、”10年-2年”)
金、銅、原油、ドルインデックス
失業率、新規失業保険申請件数、失業保険受給件数
FRBのバランスシート、M2:マネーストック(マネーサプライ)
CPI、CPIコア、PCE、PCEコア(注意:オリジナルの数値)
GDP、GDPC1(インフレ調整後GDP)
注意:インフレ率を表すため、CPI等は前年比で報告されるが、株価(や他の指標)と統一するため、前年比でなくオリジナルの数値を採用した。
from pycaret.regression import *
import datetime
import yfinance as yf
import pandas as pd
import pandas_datareader.data as web
import japanize_matplotlib
import matplotlib.pyplot as plt
%matplotlib inline
#データ取得期間(開始・終了日)
start = datetime.date(2000,1,1)
end = datetime.date.today()
# データ取得
codelist = ["^GSPC","GC=F","CL=F","HG=F","DX=F"]
data = yf.download(codelist, start=start, end=end)["Adj Close"]
# カラム名変更
data.rename(columns={"^GSPC":"S&P500","GC=F":"金","CL=F":"原油","DX=F":"ドル","HG=F":"銅"},inplace=True)
# データ取得
df_fred = web.DataReader(["DGS2","DGS5","DGS10",
"UNRATE","ICSA","CCSA",
"WALCL","WM2NS","GDP","GDPC1",
"PCEPILFE","PCEPI","CPILFESL","CPIAUCSL"],"fred", start, end)
# カラム名変更
df_fred.rename(columns={'PCEPILFE':'PCEコア','PCEPI':'PCE','CPILFESL':'CPIコア','CPIAUCSL':'CPI',
"DGS2":"金利2Y","DGS10":"金利10Y","DGS5":"金利5Y",
"UNRATE":"失業率","ICSA":"新規失業保険","CCSA":"失業保険(受給者)",
'WALCL':'FRB Assets','WM2NS':"M2"},inplace=True)
# 金利のスプレッド
df_fred["金利10Y-2Y"]=df_fred["金利10Y"] - df_fred["金利2Y"]
# 月次・週次指標の空欄を同じ値で補完
df_fred=df_fred.interpolate()
# データ結合
data=data.join(df_fred)
# 空欄を同じ値で補完
data=data.interpolate()
# df_all=(data.pct_change(20))
df_all=data
# 空欄を含む列は削除(初めの方の空欄を想定)
df_all=df_all.dropna()
データが取得できたところで、機械学習のセットアップをしていく。
3.機械学習のセットアップ
exp = setup(df_all, target='S&P500')さまざまな指標から、株価を予測したいので、前段で色々なデータを放り込んだ「df_all」を指定し、その中の「S&P500」の項目(カラム)をターゲット(目的変数)として指定する。
そうすると、
他の項目が説明変数として設定され、
データが自動的に学習データとテストデータに分割される。
面倒な処理が自動で行われるのだから、たいしたものである。
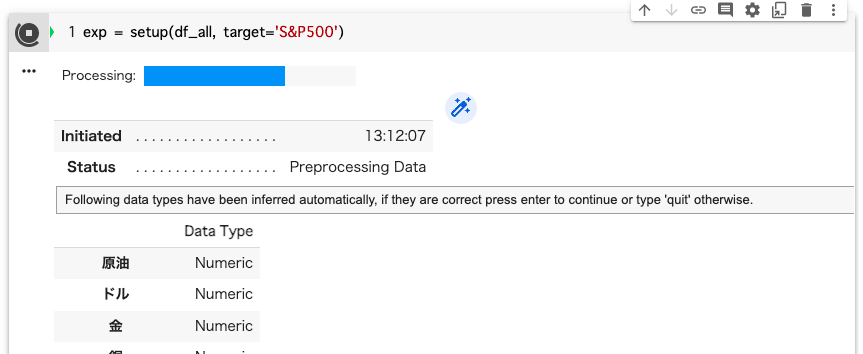

注意:上記の画面で、処理続行が聞かれます。青の入力欄にカーソルを移動して、Enterキーを入力してください。(処理は数秒ですが、キー入力に気付かず、処理中と思い込み、私はうさぎがもひもひしている動画見ながら、30分ぐらい無為に時間を潰してしまいました。もひもひが気になる人は、TikTokで「うさぎ」「もひもひ」を検索してみてください。癒されます。)
4.分析モデルの比較
compare_models()コマンドを実行すると、
18種類のモデルの中からベストのモデルを探してくれる。
よく分かんないけど、凄い!!
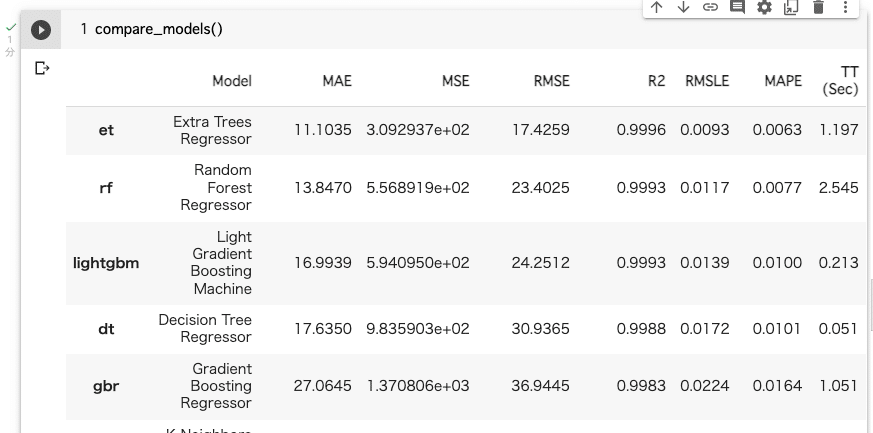
ベストのモデルが降順に並ぶ。(R2の値が最小のもの、その他の値は小さいものが良いらしい。)最上位に「et :Extra Trees Regressor」が表示されている。
5.モデルの作成
model = create_model('et')前述の処理で上位に表示された「et」のモデルを作成する。
6.ハイパーパラメータの調整
tuned_model = tune_model(model)ハイパーパラメータの設定。
この処理は時間がかかる。(8分:20項目,4822行)いろいろパラメータを調整しながらベストなパラメータを探してくれている様子。(本来は試行錯誤して、パラメータを調整しないといけない処理を自動でやってくれているのだろう。)
7.テストデータで妥当性の確認
predict_model(tuned_model)学習データとテストデータに分割したデータから、テストデータを元に、株価を予測し、モデル(ハイパーパラメータ)の妥当性を検証する。

R2の値は1に近い値となっていて、良さそうだ。
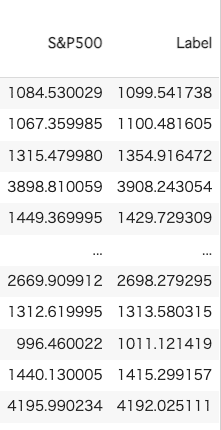
画面の右端を見ると、ターゲットで指定したS&P500の値と、予想で出力されたLabelの値は近い値になっているので、結果は上々の様に見える。
8.結果を図で表示(モデルの正しさ)
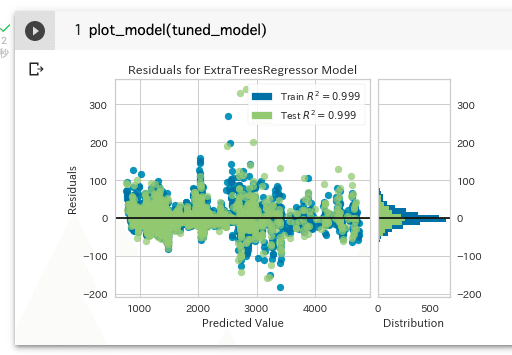
plot_model(tuned_model)下図をみると学習結果(青)とテスト結果(緑)の予測値がともに0に近い位置を中心として散らばっており、精度が高そうに見える。
ただし、±50ドルぐらいの予測誤差は、結構発生するし、-200ドル〜+300ドルぐらいの誤差も稀に発生するので注意は必要だ。
9.結果を図で表示(指標の重要度)
plot_model(tuned_model, plot = 'feature_all')今回の肝、株価の決定要因となる指標の重要度は下記のようになっている。

以上より、
FRBのバランスシートのデータが取得できる「2002-12-18」以降で、前述の指標を入力すると、株価予測に重要な要素は、下記の結果となった。
株価予測に重要な要素(降順)
GDP
M2マネーストック
GDP(インフレ調整あり)
CPI(消費者物価指数)
FRBのバランスシート
銅価格(景気を表す指標)
つまり、「経済の拡大(GDP)」と「インフレ具合」と「通貨供給量(M2、FRBバランスシート)」そして、重要度が少し下がって「銅(景況感を表すとされる)」が重要。
という結果となった。
この期間には1970年代〜1980年代のインフレ時代は含まれていないので、CPIと株価の関係性が今後も同じ様に機能するのか、疑問を挟む余地はあるかもしれないが、概ね納得感のある結果になった様に思う。
これを見ると、湯水のように給付金が配布されてマネーストック(M2)が膨れ上がった去年までのようなイージー相場は終わったと理解した方が良さそうだ。そして、FRBのバランスシート縮小が見込まれる中で、今後の株価へのマイナス影響を考慮しながら、GDPの増加や、M2、CPI、銅価格の推移に目を配るのが良さそうだ。
注意:久しぶりにあった友人が、たまたま自分と同じ様に太っているのをみて相関関係を見出すようなミスをしている可能性もあります。この場合、友人にダイエットを勧めたところで、当然、自分の体重が減るわけではありません。年齢のような他の重要な要因を見逃している可能性もあります。
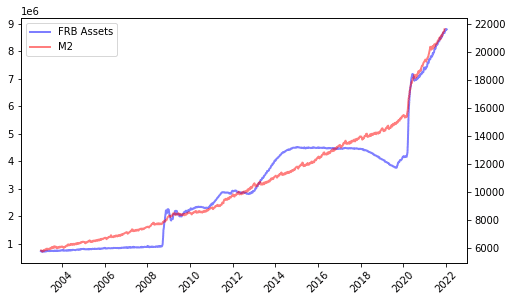
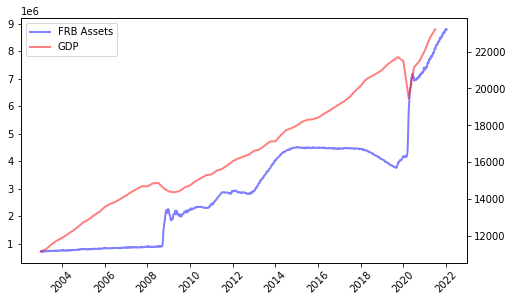
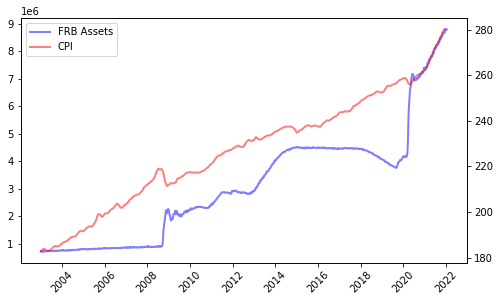
なお、下図のように、FRBのバランスシート縮小が短絡的にM2(他の指標も同じ)の縮小に結び付くわけではない点を、一応、捕捉しておきたい。
FRB資産とM2
FRB資産とGDP
FRB資産とCPI
期間を変えると、結果は違ってくるので、今の経済状況と似た期間に変更して検証してみたり、他のパラメータを入れて検証してみたりすると、新たな発見があるかもしれないですね。(たとえば、グロース株のインデックスをターゲットにすると、金利の重要度が、もう少し上がる様な気もします。)
参考になれば幸いです。
おつかれさん
「缶コーヒー1杯、ご馳走してあげよう」という太っ腹な人は投げ銭を!
課金しなくても、参考になったら「ハートボタン、フォロー、リツイート」をお願いします。読まれる可能性があがるので、次の記事を書くやる気が出ます。
おまけ
特に、現時点での予定はありませんが、何かしらのバージョンアップがあれば、課金してくれた方へのコンテンツで更新していこうと思います。
と思っていたんだけど、
早速、やりたい事があったので、少しカスタマイズしてみました。
新たな指標を1つ追加したり、株価を5日スライドさせて、現在の指標から、未来の株価を予測するプログラムを書いてみたので、「プログラムとその結果」をおまけにつけておきます。
まぁ、予測なんて、政策やFRB議長の一言や重要イベントで覆るものなので、そう言う不確かなもので役に立たないおまけ程度のものだと思って期待しないでください。
ここから先は
¥ 100
この記事が気に入ったらチップで応援してみませんか?