
【Python】セクターローテーション?

無料で読めます。
普段、ふわっと語られる事が多いセクターローテーションについて、検証してみました。過去のデータから、次に来るセクターが分かるかも・・・
スタンダード&プアーズのチーフ投資ストラテジスト、サムストーバルが、1996年に開発したセクターローテーション理論。彼は、米国の全米経済研究所(NBER)によって提供された1854年までさかのぼる景気循環に関するデータを研究することによってこの理論を導き出したらしい。
Twitterアカウントは多分これ ↓
https://twitter.com/StovallCFRA?s=20
この理論では、景気循環に着目しながらセクターローテーションを説明しているようなので、景気循環を示す一つの指標であるイールドカーブを中心にして、セクターローテーションについて、検証してみたい。
その前に、まずは、セクターローテーションが本当にあるのか確認してみよう。
1.セクターローテーションの存在確認
セクターローテーションがあるのか確認するため、米国株を幅広くカバーするバンガード社のVTIをベースとして、各セクターのパフォーマンスの優劣を確認してみる事にした。
確認方法
・各業種の変動率からVTIの変動率を引きパフォーマンスの優劣を見る。
・大きな循環を見るため、変動率は半年前と比較する。(120営業日)
2.コード(セクターローテーション存在確認)
実行するコードは下記の通り。
事前準備として、日本語のライブラリをインストールする。
pip install japanize_matplotlib株価取得のライブラリをインストールする。
pip install yfinance事前準備が終わったところで、下記を実行。
# !pip install yfinance
# !pip install japanize_matplotlib
import datetime
import yfinance as yf
import pandas_datareader.data as web
import matplotlib.pyplot as plt
import pandas as pd
import japanize_matplotlib
%matplotlib inline
#開始・終了日の設定
start = datetime.date(2004,1,1)
end = datetime.date.today()
chdays=120
codelist = ["VTI","VDE","VFH","VAW","VIS","IYR","VOX","VDC","VCR","VHT","VGT","VPU","^TNX"]
data = yf.download(codelist, start=start, end=end)["Adj Close"]
df_all=(data.pct_change(chdays))
df_all.rename(columns={'VDE':'エネルギー','VFH':'金融','VAW':'素材',
'VIS':'資本財','IYR':'不動産','VOX':'通信',
'VDC':'生活必需品','VCR':'一般消費財',
'VHT':'ヘルスケア','VGT':'情報技術','VPU':'公共事業',
'^TNX':'10 Year Treasury'},inplace=True)
#取得データを作業用にコピーしてVTIと変化率を比較
df_all2 =df_all.copy()
df_all2['エネルギー - VTI']=pd.DataFrame(df_all['エネルギー']-df_all['VTI'])
df_all2['金融 - VTI']=pd.DataFrame(df_all['金融']-df_all['VTI'])
df_all2['素材 - VTI']=pd.DataFrame(df_all['素材']-df_all['VTI'])
df_all2['資本財 - VTI']=pd.DataFrame(df_all['資本財']-df_all['VTI'])
df_all2['一般消費財 - VTI']=pd.DataFrame(df_all['一般消費財']-df_all['VTI'])
df_all2['不動産 - VTI']=pd.DataFrame(df_all['不動産']-df_all['VTI'])
df_all2['通信 - VTI']=pd.DataFrame(df_all['通信']-df_all['VTI'])
df_all2['生活必需品 - VTI']=pd.DataFrame(df_all['生活必需品']-df_all['VTI'])
df_all2['ヘルスケア - VTI']=pd.DataFrame(df_all['ヘルスケア']-df_all['VTI'])
df_all2['情報技術 - VTI']=pd.DataFrame(df_all['情報技術']-df_all['VTI'])
df_all2['公共事業 - VTI']=pd.DataFrame(df_all['公共事業']-df_all['VTI'])
#不要カラムをドロップしてグラフ化
df_all2.drop(["VTI","エネルギー","金融","素材","資本財","不動産","通信",
"生活必需品","一般消費財","ヘルスケア","情報技術","公共事業"], axis=1, inplace=True)
df_all2.plot(figsize=(10,16),fontsize=15,linewidth=2,alpha=0.6,subplots=True,grid=True,xlim=("2005-01-01","2028-01-01"))
plt.xlabel(xlabel="")
plt.show()
#ここまで3.実行結果
実行結果は、下記の通り。VTIに対して各業種のパフォーマンスは上下しており、大きなスパンで見ると、何らかの大きなトレンドがありそうなのが確認できる。
そして、トレンドは、図の一番上にある金利と連動して動いているものもある様に見える。(注:10 Year Treasuryは純粋な変動率であり、VTI変動率との差分ではない。)
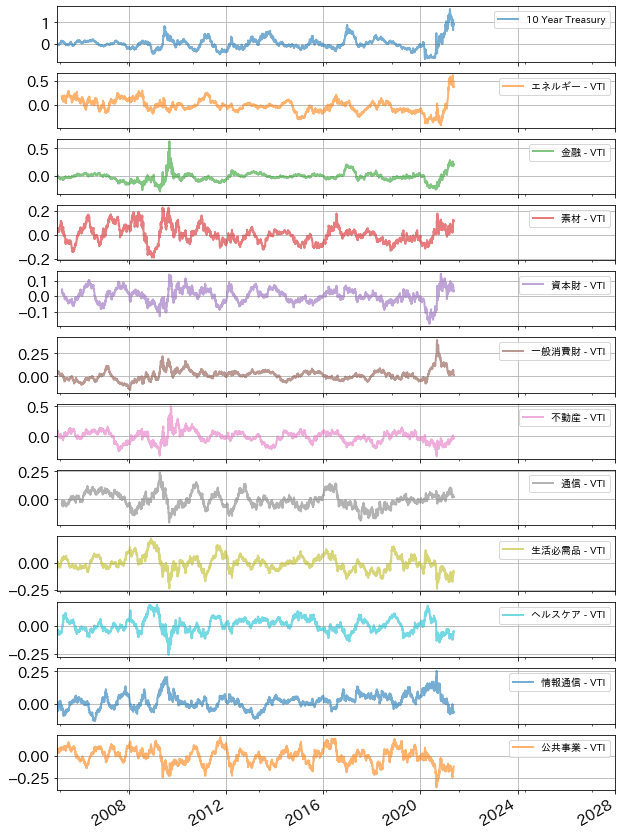
上図では、大きなスパンで見た時に、VTIに対して、売れ過ぎ買われ過ぎの業種や、そのトレンドがどれくらいの期間続くものなのか確認できるように思われる。その確認に、このコード利用するのも良いだろう。(たとえば、トレンドは半年ぐらい続く事があっても、1年継続することは稀の様に見える。)
ここでは、業種別のパフォーマンスには、何らかのトレンドがあり、金利と関連が高そうだという大枠が確認できたので、次は、本題である景気循環を示す一つの指標であるイールドカーブを中心にして、セクターローテーションについて、検証してみたい。
4.セクターローテーションの傾向
景気の状態に合わせたセクターローテーションの傾向(業種ごとのパフォーマンス)を確認するために、区分を行う。
区分方法としては、イールドカーブが表す下記の4つ景気の状態に分けて、それぞれの時期の業種毎のパフォーマンスを見ていく事とする。
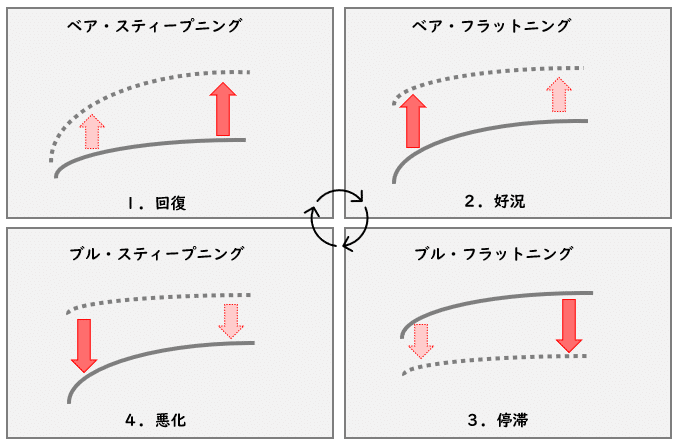
・ベア・スティープニング(回復)
景気の先行き期待から長期金利が上昇し、イールドカーブが立ってきている状態。
・ベア・フラットニング(好況)
景気の好調さを反映し、利上げを伴い、短期金利が上昇し、イールドカーブが寝てきている状態。
・ブル・フラットニング(停滞)
景気に先行きの強さが見られず、上昇した短期金利が長期金利の追いつき、イールドカーブが寝てきている状態。
・ブル・フラットニング(悪化)
景気に先行きの弱さが見られ、利下げを伴い、短期金利が下落し、イールドカーブが立ってきている状態。
だいたいの区分を把握したところで、確認方法を説明したい。
5.コード(セクターローテーション傾向)
セクターローテーションの傾向を確認する方法と条件は下記の通り。
確認方法と条件
・期間はVTIと各業種のETFが組成された時点(2004年12月)から現在まで。
・各業種の変動率からVTIの変動率を引きパフォーマンスを見る。
・変動率は3か月前(60営業日)からの変動率とする。
・イールドカーブの判定条件について
・長期金利は10年、短期金利は2年とする。
・長短金利うち、変動率が大きいものをブル・ベアの方向性とする。
・長短金利差拡大はスティープニングとする。
・長短金利差縮小はフラットニングとする。
・イールドカーブの状態に合わせて業種別のリターンを確認。
だいたいの条件を把握したところで、下記のコードを実行してみよう。
# !pip install yfinance
# !pip install japanize_matplotlib
import datetime
import yfinance as yf
import pandas_datareader.data as web
import matplotlib.pyplot as plt
import pandas as pd
import japanize_matplotlib
%matplotlib inline
#開始・終了日の設定
start = datetime.date(2004,1,1)
end = datetime.date.today()
#変動率を見るスパンの設定
chdays=60
#パフォーマンスを見るETF情報
codelist = ["VTI","VDE","VFH","VAW","VIS","IYR","VOX","VDC","VCR","VHT","VGT","VPU","^TNX"]
data = yf.download(codelist, start=start, end=end)["Adj Close"]
df_all=(data.pct_change(chdays))
df_all.rename(columns={'VDE':'エネルギー','VFH':'金融','VAW':'素材',
'VIS':'資本財','IYR':'不動産','VOX':'通信',
'VDC':'生活必需品','VCR':'一般消費財',
'VHT':'ヘルスケア','VGT':'情報技術','VPU':'公共事業',
'^TNX':'10 Year Treasury'},inplace=True)
#取得データを作業用にコピーしてVTIと変化率を比較
df_all2 =df_all.dropna().copy()
df_all2['エネルギー - VTI']=pd.DataFrame(df_all['エネルギー']-df_all['VTI'])
df_all2['金融 - VTI']=pd.DataFrame(df_all['金融']-df_all['VTI'])
df_all2['素材 - VTI']=pd.DataFrame(df_all['素材']-df_all['VTI'])
df_all2['資本財 - VTI']=pd.DataFrame(df_all['資本財']-df_all['VTI'])
df_all2['一般消費財 - VTI']=pd.DataFrame(df_all['一般消費財']-df_all['VTI'])
df_all2['不動産 - VTI']=pd.DataFrame(df_all['不動産']-df_all['VTI'])
df_all2['通信 - VTI']=pd.DataFrame(df_all['通信']-df_all['VTI'])
df_all2['生活必需品 - VTI']=pd.DataFrame(df_all['生活必需品']-df_all['VTI'])
df_all2['ヘルスケア - VTI']=pd.DataFrame(df_all['ヘルスケア']-df_all['VTI'])
df_all2['情報技術 - VTI']=pd.DataFrame(df_all['情報技術']-df_all['VTI'])
df_all2['公共事業 - VTI']=pd.DataFrame(df_all['公共事業']-df_all['VTI'])
#不要カラムをドロップしてグラフ化
df_all2.drop(["VTI","エネルギー","金融","素材","資本財","不動産","通信",
"生活必需品","一般消費財","ヘルスケア","情報技術","公共事業"], axis=1, inplace=True)
df_all2.plot(figsize=(10,16),fontsize=15,linewidth=2,alpha=0.6,subplots=True,grid=True,xlim=("2005-01-01","2028-01-01"))
plt.xlabel(xlabel="")
plt.show()
#イールドカーブを判定材料となる金利情報取得
df_rate = web.DataReader(["DGS2","DGS10"], "fred", start, end)
df_rate_ch = df_rate.pct_change(chdays)
#イールドカーブの状態を4つに区分
df_rate_ch.loc[(abs(df_rate_ch['DGS10'])-abs(df_rate_ch['DGS2'])>0) &(df_rate_ch['DGS10']>0), 'Yield_Curve'] = "BearSteep"
df_rate_ch.loc[(abs(df_rate_ch['DGS10'])-abs(df_rate_ch['DGS2'])<=0) &(df_rate_ch['DGS2']>0), 'Yield_Curve'] = "BearFlatt"
df_rate_ch.loc[(abs(df_rate_ch['DGS10'])-abs(df_rate_ch['DGS2'])>0) &(df_rate_ch['DGS10']<=0), 'Yield_Curve'] = "BullFlatt"
df_rate_ch.loc[(abs(df_rate_ch['DGS10'])-abs(df_rate_ch['DGS2'])<=0) &(df_rate_ch['DGS2']<=0), 'Yield_Curve'] = "BullSteep"
#業種別リターンとイールドカーブの状態のデータを結合
df_all2=df_all2.join(df_rate_ch)
#業種別リターンをイールドカーブの状態毎に集計
df_temp=pd.DataFrame(data=None, index=None, columns=None, dtype=None, copy=False)
df_temp["1.ベア・スティープ(回復)"]=df_all2[df_all2.Yield_Curve == "BearSteep"].sum()
df_temp["2.ベア・フラット(好況)"]=df_all2[df_all2.Yield_Curve == "BearFlatt"].sum()
df_temp["3.ブル・フラット(停滞)"]=df_all2[df_all2.Yield_Curve == "BullFlatt"].sum()
df_temp["4.ブル・スティープ(悪化)"]=df_all2[df_all2.Yield_Curve == "BullSteep"].sum()
#イールドカーブの状態に依存しない、全体のリターンを集計
df_temp["合計"]=df_all2.sum()
#グラフ作成前処理、不要カラムの削除
df_temp.drop(["DGS2","DGS10","10 Year Treasury"], axis=0, inplace=True)
#項目の行列を入れ替えてグラフ作成
df_temp.T.plot.bar(figsize=(12,6), width=0.8,fontsize=17)
plt.legend(loc='center left', bbox_to_anchor=(1, 0.5), fontsize=20)
plt.xticks(rotation=60)
plt.show()
#項目の行列を入れ替えて不要カラム削除し、ソート
df_temp_t=df_temp.T
df_temp_t.drop(["Yield_Curve"], axis=1, inplace=True)
df_temp_t.sort_values(by=df_temp_t.index[0], axis=1, ascending=False, inplace=True)
#4項目目までを分割してグラフ化
df_temp_t[0:4].plot(figsize=(3.5,12),linewidth=2,alpha=0.5,subplots=True,layout=(12,1),grid=False)
plt.xticks(rotation=90)
plt.show()
#イールドカーブの状態で区分した日数をカウント
print("---1.ベア・スティープ(回復)対象日数---")
print((df_all2.Yield_Curve == "BearSteep").sum())
print("---2.ベア・フラット(好況)対象日数---")
print((df_all2.Yield_Curve == "BearFlatt").sum())
print("---3.ブル・フラット(停滞)対象日数---")
print((df_all2.Yield_Curve == "BullFlatt").sum())
print("---4.ブル・スティープ(悪化)対象日数---")
print((df_all2.Yield_Curve == "BullSteep").sum())
print("--------")
#ここまで6.実行結果
実行すると、下記の結果が得られる。
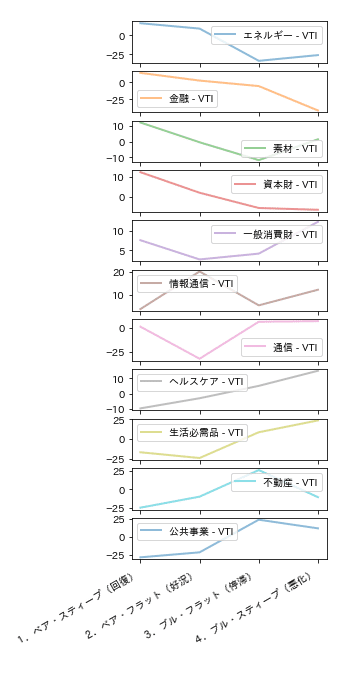
イールドカーブがベア・スティープニングの状態、つまり、「1.回復期」にはVTIと比較して、エネルギーや金融、素材、資本財のパフォーマンスが良くなっている。これは、足元の状況とも合致しているように思われる。

下記のセクターローテーションが順調に右回りで推移するとすれば、次に備えて仕込むべきは、エネルギーや情報技術であるように思われる。もう少し先を考えるのであれば、停滞の時期にパフォーマンスが良くなる不動産や公共事業を、好況の時期に仕込むというような事も考えられる。
しかし、上図の右端を見ればわかるように、過去を合計したリターンは、一般消費財と情報技術が圧倒的なので、この二つを全体のセクターローテーションのサイクルを見ながら仕込むのが良いのか知れない。

(追記)もう少し業種ごとの推移が分かり易くなるように、コーディングを追記しました。下記の様な図が出力されます。
これを見れば、業種ごとに売り買いするのに適切なタイミングが見やすくなったように思います。0のラインを意識して見て貰えると、良いと思います。(例えば、情報技術の0のラインはグラフの底辺になっています。)
最後に、注意点を述べておきたいと思います。
注意点
今回の結果は、設定したプログラムの条件で2004年以降を検証すると、上記の結果が得られたという事であり、今後を保証するものではありません。
想定外の事態が発生して、経済の再開が進まずに、上図「1.回復期」が続く可能性もあります。また、2、3、4と駆け足で進む可能性や、途中で2と1を行き来するような可能性もあります。
更には、過去パフォーマンスが良かった「一般消費財と情報技術」のパフォーマンスが今後も良いとは限らないので、ご注意ください。
個人的には、今回の検証では、かなり満足のいく結果が得られた様に思います。これを使って、前から買いたいと思っていた株の業種を見ながら買うタイミングを考えることができそうです。
一方で、この様なセクターローテーションを意識しなくても良い、VTIやVOOと言ったETFは非常に優れている様に思いました。
普段、ふわっと語られる事が多いセクターローテーションについて、Pythonを使いながら検証してみました。
何かの役に立てば幸いです。
おつかれさん「缶コーヒー一杯ぐらい、ご馳走してあげよう」という太っ腹な方がいれば、よろしくお願いします!
課金しなくても、参考になったら、「ハートボタン」をクリックしたり、「リツイート」してくれると読まれる可能性があがるので嬉しいです。やる気が出ます。よろしくお願いします!
本文はここまでですが、以下おまけです。
以下のおまけでは、イールドカーブで景気を4つの期間を区分したけど、「どの期間を何に区分したの?」「今って、どこに区分されているの?」っていう事が分かる派生ツールを作ったので、その情報を付けておきます。
あと、すこし、余談的なネタもあります。
ここから先は
¥ 100
この記事が気に入ったらチップで応援してみませんか?