
会計パーソンのためのExcel~PowerQueryを嫌いにならないために~

皆さん、こんにちは。
お読みいただき、ありがとうございます。
なかなか連載を続けることが難しいと痛感している(と同時に、連載を継続できている方々に尊敬の念を抱きまくっている)筆者です。
今回、少し休憩がてらに以下のお題目で記事を書こうと思います。
PowerQueryをイマイチ使う気になれない理由
わたしがnoteを書こうと思った理由に直結しています。
これはわたしの経験ですから、違う理由も当然ありえます。ただ、同じ意見の人も一定数いらっしゃるのでは?と想像しています。
数式組んでるんだから、データソースのシートだけ貼りかえれば良いんじゃないの?
読み込み直すたびにエラーが出てめんどくさい・・・
PowerQueryでデータの読込を相対パス的に実行する方法
以下のような共有フォルダの構成例を考えてみます。
実際はもっと複雑だったり、会社により構成は様々ですが、基本的には決算期(202403Q01、202403Q02、202403Q03)が変わっても中身の構成は一緒、ということが多いと思います。
今回は、PowerQueryで集計するファイルを「決算期」フォルダの直下に置いてある、という前提です。


通常の方法
教科書的には、
データ>データの取得>ファイルから>Excelブックから
と進み、直接ファイルを指定する形になります。
もしくは、
データ>データの取得>ファイルから>フォルダーから
を選択し、フォルダー内にある情報を一括取得することもできます。

もちろん、この方法で指定したファイルの情報を取得することはできます。
ただし、決算期が変わることに伴い、ファイルの絶対パスが変わるケースにおいては、使いまわしができません。
理由は、PowerQuery起動後の「ソース」ステップの数式にあります。
以下の数式が意図せずとも自動で実行されることで読込がなされるわけですが、よく見るとパスが文字列(""で囲まれている)として決め打ちになっています。PowerQueryファイルの場所を変えたからといってもここは自動では変わりません。逆に言うと、ここさえ可変にできれば、毎回指定したフォルダにある同ファイルを読み込めるということです。


ちなみに、「フォルダーから」だと、フォルダに含まれるファイル自体の情報(拡張子、作成、更新日時など)が取得でき、何かと便利ですので、わたしは「フォルダーから」を使うことがほとんどです。

そこで、わたしが普段から実行している方法を一案として紹介します。
事前準備
PowerQueryを埋め込んでいくワークブックに、以下のようにフォルダ構成をまとめた一覧を用意します。

PowerQueryで読み込む関係で、7行目以降は、「Folderpath」というテーブル名を付しています。わかりやすければ何でも構いません。
「ここだけ毎期変更する」とある決算期セルを変更すれば、連動してファイルパスが作成できるようになっています。
D列の「Fullpath数式」は今回のnote用に可視化※しているだけですので、業務上は必要ありません。※=FORMULATEXT([@Fullpath])
テーブル「Folderpath」をPowerQueryで読み込む
「Folderpath」テーブルを選択した状態で、「データ>テーブルまたは範囲から」を選択し、Power Query エディターを起動します。


読み込んだパスからファイル情報を取得する
列の追加>カスタム列にて、以下の数式を入力します。
すると、追加した列に「Table」というセルが現れます。
上で紹介した、そのフォルダに含まれるファイル情報テーブルです。


// [Fullpath]は[Fullpath]列という意味
= Folder.Files([Fullpath])不要な列を削除し、展開


展開後、以下のようになっていれば一覧を取得できています。

必要なデータを取得する
上記ではファイルの情報自体は取得できましたが、肝心の中身がまったく取得できていませんので、そこをクリアしていきます。
会社マスタの取得
上で作った「Folderpath」クエリを参照します。参照元の結果とまったく同じテーブルが作成されます。


クエリ名を変更します。自動では、Folderpath(2)などになるので、「会社マスタ」等に変更します。

今回欲しいデータのみフィルタ(Contrent列が会社マスタ)します。
※Contrentは表作成時のスペルミスです。。。すみません😵

会社マスタのフォルダには、マスタデータ以外にメモファイルが混じっているので、それを取込み対象から除外します。以下例ではファイル名で絞っていますが、メモ帳とマスタファイルが異なる拡張子であれば、Extension列でも可です。

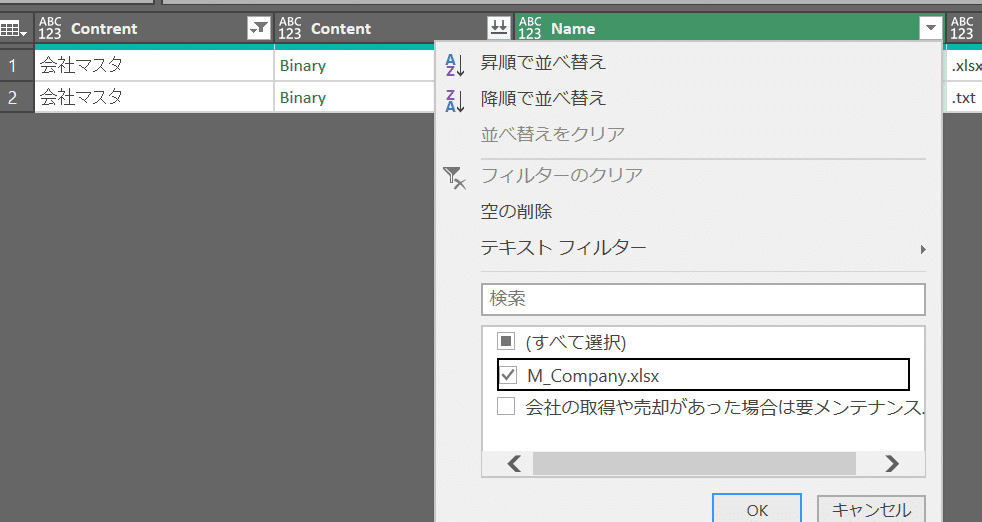
Contrent列(Binaryというデータがある列)以外を削除します。

「Binary」の文字をクリック

Binaryを展開すると、以下のようなテーブルが自動作成されますが、必要なデータは「Data」列にあるため、それ以外の列を削除


展開すると必要なデータは取得できていますが、1行目を列名として使用したいため、ホーム>1行目をヘッダーとして使用、をクリック


以下のようにワークシートに2社読み込まれていれば完成です。

テスト
今回の目的は、決算期が変わっても、正しく情報が更新されることです。
そこで、決算期「202403Q02」において、2社買収、1社売却した、という前提でマスタを変更し、それが正しく読み込まれるか確認します。
「202403Q02」フォルダで、以下のとおりマスタを更新します。
当然ながら「202403Q01」フォルダ配下の会社マスタは変更していません。
※S001は削除、S002とS003は新規追加


「すべて更新」により、最新のデータに更新されました!

勘定科目マスタの取得
会社マスタと同じことをやれば良いだけです!
で終わらせても良いのですが、内容は違ってもファイル構成が同じ場合、「クエリの複製」で効率化を図ることができます。
作成した「会社マスタ」クエリで右クリック>複製、を選択

名前に(2)とついた、まったく同じステップのクエリが作成されます。
つまり、これをベースに変えるところだけ変えれば時短ができます。
プロパティの名前を「勘定科目マスタ」に変えて作業を進めましょう。


違うところは、以下のフィルターされた行のみです。
「会社マスタ」を作るときは、ここで会社マスタを選択したわけなので、
「勘定科目マスタ」でフィルタし直せばいいだけです。

ソースステップに戻って、「Contrent」列で「勘定科目マスタ」を選択。


「フィルターされた行」が2つできるので、「会社マスタ」をフィルタしている方を削除

警告文が出ますが、問題ないので「削除」をクリック

「適用したステップ」の末尾(今回の例だと「昇格されたヘッダー数」)を選択すると、勘定科目マスタが取得できていることが確認できました!

ファイル読込時のよくあるエラーを回避する
よくあるエラーとは
結論から言うと、「データ型の検出」という便利な機能がネックになるケースがあります。
「データ型の検出」は、取り込んだテーブルの各列が、テキストなのか数字(整数、10進数)なのか日付なのか。。。ということを、自動で判定してくれる仕組みになっています。
Excelファイルを読み込むとき、デフォルトでは、以下の4ステップが自動で作成されます。「変更された型」というのが、このデータ型の検出を実行した、ということです。


「変更された型」の数式を確認すると、{"取り込んだ列名", type 変更後の型}という羅列になっていますが、ここが最初に取り込んだ状態(固定値)になっています。

つまり、上記の例では、メモ列A、メモ列B、メモ列Cという列があるファイルを最初に構築するときに取り込むと、以後はこれが前提になります。取り込むファイルが次回もこの構成なら良いですが、担当者が変わるなどして削除したような場合、「そんな列ないよ」って怒られるわけです。

クエリのオプションの変更
私は自分で構築するときは以下のとおり設定を変更して、必要なときに「データ型の検出」ステップを実行しています。
ファイル>オプションと設定>クエリのオプション>データの読み込み>
非構造化ソースの列の型とヘッダーを検出しない
※デフォルトは「非構造化ソースの列の型とヘッダーを常に検出する」


すると、ステップ数が減ります。
※「昇格されたヘッダー数」「変更された型」が自動作成されなくなる。

これでエラーは回避できるわけですが、基本的にはデータ型の変換自体は必要なことが多いので、手動で実行します。
ちなみに、「データ型の検出」を手動で実行することをお勧めしている理由は、エラー回避リスクを減らす、以外にもあります。
「データ型の検出」の仕組みは、大まかに以下のとおりだそうです。
列ごとに最初の200行(バージョンによるそうです)をスキャン
スキャン結果をもとに、その列が数字なのかテキストなのか、、、を判断
上記をすべての列で実行
ただ、これだと以下のデメリットがあります。
同じ列に、数字のみのテキストと文字を含むテキストが混在するケースでは、最初の200行に数字しか含まれないケースがある。この場合、自動では整数が設定されるが、途中の行から数字以外の文字が含まれる場合はエラーになってしまう。
例:伝票番号や各種コード。これらは性質としては文字列。
※四則演算に使わない列は基本的に数字にはしないのがベスト。デフォルトではファイル読込時に「データ型の検出」が実行されるが、すべての列で実行されるため、膨大な列数があるファイルを読み込む場合は処理時間がかかる。
最終的に必要な列数はファイルの一部であるケースが多いため、絞ってから「データ型の検出」を実行する方がパフォーマンスも良くなりますから、使用頻度が高い方はぜひ試してみてください!
以上、PowerQuery触ってみようかなーと思っていただければ幸いです。