
実験記録ツール「neptune.ai」を使ってみた

はじめまして。
九州工業大学情報工学府、本田あおい研究室メンバーの穴井です。現在修士2年生で、学生最後の1年ということもあり、今までで一番楽しみながら研究に時間を費やしている気がします。
これから約1年間、よろしくお願いします!
早速ですが、記念すべき1記事目は、最近使ってみた機械学習用の実験記録ツールである「neptune.ai」について紹介します!以下、目次です。
きっかけ
膨大な量の実験が必要になったため
実験結果の記録と管理よりも、実験そのものに時間とエネルギーを割きたいため
手動での記録では記録方法に一貫性が欠けてしまったり、うっかり誤入力してしまったりする場合があり、再現性の限界があるため
メリット
あらゆる変数で絞った結果の可視化が容易に行える
記憶容量がいらず(100Gまで無料)、必要なときに必要なデータをcsv形式で保存・分析できたり、グラフのダウンロードが可能である
そこで、今回はメジャーなツールのうち、最も使われていそうな「neptune.ai」というツールを使用してみました。その使用方法と感想を簡単に述べようと思います.
neptune.aiの使い方
使いはじめるまで、たった4ステップで意外とすぐに試すことができます。
ログイン(googleアカウントでログイン可能)
user name を決める
アンケートに回答 (数分で終わります)
チュートリアル、スタート!
チュートリアル内でも説明がありますが、すでにプロジェクトと学習されたサンプルのデータが初めから用意されており、グラフ化したりデータをいじってみたり色んな条件でフィルタリングしたり、ということが簡単にできて楽しかったです。
Pytorch用サンプルプログラムの動作確認
jupyter notebookで実行・記録
チュートリアルであらかた使い方を把握したのち、自分の実験環境であるjupyter notebook上で動作確認をしてみました。
1 neptune.ai上でnew project 作成する。
2 プログラムの最初に [ !pip install neptune torch torchvision --user ] を実行する (--user がないとエラーで実行できないので注意です)。
3 サンプルプログラムをコピー&実行する (私は次項のPytorch用のコードをコピペしてやってみました)。
4 実行後、プロジェクト内に学習データが記録される。
コードの説明
<pytorch用サンプルコード>
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
import neptune
run = neptune.init_run(
project="project_name",
api_token="api_token_name",
)
params = {
"lr": 1e-2,
"bs": 128,
"input_sz": 32 * 32 * 3,
"n_classes": 10,
}
run["parameters"] = params
transform = transforms.Compose(
[
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),
]
)
trainset = datasets.CIFAR10("./data", transform=transform, download=True)
trainloader = torch.utils.data.DataLoader(
trainset, batch_size=params["bs"], shuffle=True
)
class BaseModel(nn.Module):
def __init__(self, input_sz, hidden_dim, n_classes):
super(BaseModel, self).__init__()
self.main = nn.Sequential(
nn.Linear(input_sz, hidden_dim * 2),
nn.ReLU(),
nn.Linear(hidden_dim * 2, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim // 2),
nn.ReLU(),
nn.Linear(hidden_dim // 2, n_classes),
)
def forward(self, input):
x = input.view(-1, 32 * 32 * 3)
return self.main(x)
model = BaseModel(params["input_sz"], params["input_sz"], params["n_classes"])
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=params["lr"])
for i, (x, y) in enumerate(trainloader, 0):
optimizer.zero_grad()
outputs = model.forward(x)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, y)
acc = (torch.sum(preds == y.data)) / len(x)
run["train/batch/loss"].append(loss)
run["train/batch/acc"].append(acc)
loss.backward()
optimizer.step()
model.eval()
correct = 0
for X, y in trainloader:
pred = model(X)
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
run["valid/acc"] = correct / len(trainloader.dataset)
run.stop()サンプルコードの説明を少しだけ。
import neptune
neptune.aiを使うために必要なライブラリのインポートrun=neptune.init_run()
記録開始時に記述。プロジェクト名とapi tokenはプロジェクトごとに変わるので間違えないようにする必要。辞書型配列"params"
neptune.ai に記録したいハイパーパラメータをまとめたもの。params["変数名"]をコード内で変数の代わりに使うことで一貫性のある記録がとれます。(run["parameters"] = paramsでツールへの記録を実行している)run[〇〇].append()
随時記録する変数をその都度ツールに記録する。
リストを一気にツールへ記録したい場合、学習後にrun["train/val_loss"].log(model.val_loss_list[:])
の形で記述することで記録可能。run.stop()
記録終了するときに書く。
結果の可視化
[charts]をクリックすると、記録したデータが自動でグラフ化されます。
また、x軸はstep、time等、y軸はlinear、logを選択できます。
また、複数回の学習を行ったあとに画像の左側、帯部分にある目のマークをクリックすることで、複数の学習結果を重ねて表示可能です。
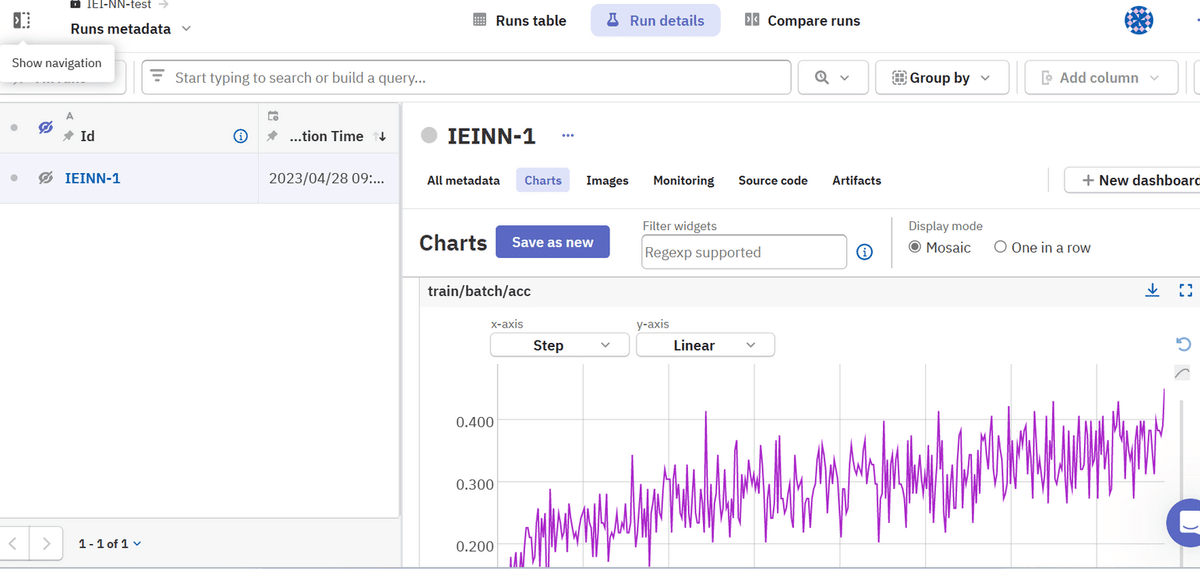
グラフ右上部分にある「↓」をクリックすることで、csvまたはpdf形式でグラフのデータを保存可能です。
更に、設定すればコードも記録でき、バージョン情報も保持できそうです。

感想
一言で、非常に使いやすいツールでした!
一貫性のある記録を行う必要はありますが、ルール等をうまく決めて活用すれば、実験記録の管理コストはかなりおさえられそうだと感じました。
今後、記録容量がどのくらい必要になるか分かりませんが、必要になれば複数のアカウントを持つなり、有料版にアップグレードするなりしたいと思います。
大量に実験を回したい方はぜひ使ってみてください。
最後まで読んでいただきありがとうございました!