
ControlNet v1.1を用いた表情制御について

こんにちは!Hi君です。
AI画像生成において不可欠な技術である「ControlNet」。今回は、その新バージョンである「ControlNet v1.1」について色々と試してみてわかったことをまとめました!
■調べてみてわかったこと
・ControlNet v1.1ではMediaPipeFaceモード、mediapipeを用いた顔認識 + 表情制御用ガイダンス情報を付与しながら画像生成するような拡張機能が追加された。
▶今までは表情制御用の拡張機能は無く、Cannyエッジモードである程度のラフな線画書き込みをガイダンスにする必要だった。
・MediaPipeFaceモードの抽象的な顔輪郭のガイド情報を用いる + 編集することで一定の表情制御ができる事を確認。
・また、写実的な画像・アニメ絵的画風の画像、共にガイダンス付きで画像生成できる事も確認した。
関連リンク
■概要等
・Mikubill/sd-webui-controlnet/pull/688: (Add MediaPipe Face Control)
・https://github.com/lllyasviel/ControlNet-v1-1-nightly
・新たに6モデルを追加したControlNet1.1が公開
・2023/04/21/画像生成をよりコントロール可能なものとする-controlnet
・New ControlNet Face Model
■ControlNet MediaPipeFaceのインストール・設定手順
キャラクターの表情を制御できる「MediaPipeFace」の使い方【ControlNet】
MediaPipeFaceモードでの表情制御
・MediaPipeFaceマスクを何かしらの形で用意する事で以下のような表情制御 (口部分のガイダンス画像を併用したimage inpainting) が出来る事を確認した。
・また、手書きで編集したガイダンス画像を利用しても正常に画像生成ができる事も確認。

Controlnet v1.1 + MediaPipeFaceモードを使用しない場合の結果について

プロンプト・設定
a woman with long black hair and a red shirt, looking at the camera, long black hair, aestheticism, 4K, 8K, ((open mouth))
Negative prompt: EasyNegative
Steps: 20, Sampler: DPM++ 2M Karras, CFG scale: 7,
Size: 512x512, Model hash: e6415c4892, Model: realisticVisionV20_v20
Denoising strength: 0.7, Mask blur: 4・プロンプトのみだと意図した画像を生成するためのseed選定が比較的タフ。
・denoising strengthが小さい場合は、プロンプトの意図に沿わない形で画像生成する事がある。
▶上の例だとプロンプト文章に((open mouth))と行った形で強調した指示語を付け加えているのにも関わらず、口が開いた形で画像生成されない等。
・大きく口を開く等、元画像に対して大きな変形を加えたい場合にはdenoising strengthを大きめに設定する必要がある。
▶そうするとパースや形状、色味に破綻が生じる場合がある。
・つまり、以下の難点が存在する。
▶Seed選定とパラメタチューニングの2つに労力を割く必要がある。
▶画像生成能力の対象不変性や制御可能性が薄い。適用対象を選ばずに意図したアクションを細かく指定指定しながら画像生成を行う事が難しい。
└MediaPipeFaceモードを利用することでこの部分のコントロールが比較的効率良くできる点が利点。
Controlnet v1.1 + MediaPipeFaceモードを使用する場合の処理フロー
1. 元画像を用いて顔認識 + ガイダンス画像生成する
・Controlnet設定はModuleはcanny、Modelはcontrol_v2p_sd15_mediapipe_faceを指定する。
・Denoising strengthを0.0で指定すると、ガイダンス画像生成のみがWebUI上で高速に行われる。
プロンプト
a woman with long black hair and a red shirt, looking at the camera, long black hair, aestheticism, 4K, 8K
Negative prompt: EasyNegativeSteps: 20, Sampler: DPM++ 2M Karras, CFG scale: 7, Seed: 4128184844,
size: 512x512, Model hash: e6415c4892, Model: realisticVisionV20_v20, Denoising strength: 0.0, ControlNet-0 Enabled: True, ControlNet-0 Module: canny, ControlNet-0 Model: control_v11p_sd15_canny [d14c016b], ControlNet-0 Weight: 1, ControlNet-0 Guidance Start: 0, ControlNet-0 Guidance End: 1.0
2. 適用対象のガイダンス画像を用意する

・今回はKritaを用いて以下のような手順で生成した。
▶他の生成画像を用いてガイダンス画像を生成する。
▶口部分について、目的のガイダンス画像に新しいレイヤー上にコピペする。
▶元画像を背景画像にしながら、簡単な変形(回転・格子点ベース変形)・位置合わせを行う。
▶変形によって線がボヤケるのでアンチエイリアス無しのベジエ曲線描画で口部分についてなぞる (ただ、ある程度ぼやけてても動作はする)。
▶画像をExportして完了。
・顔認識後自動生成されるガイダンス画像について、各顔部位毎の色情報についてはリンク先を参照。

3. img2img(Inpaintingモード) + ControlNet v1.1(MediaPipeFaceモード)で画像生成を行う
・Denoising strengthは大きめ(0.7程度)に指定した。
・また、ここの時点では今回はMediaPipeFaceモードのガイダンス能力を図るため、プロンプト中の"((open mouth))"は省いている。
・Seedや対象によってはこの手順で意図した画像が生成される事もあるが、denoising strengthが大きい場合は色や細部の形状が意図した生成結果から離れる事がある。
▶例えば、下の例だと唇・歯の形状や色が多少破綻している。
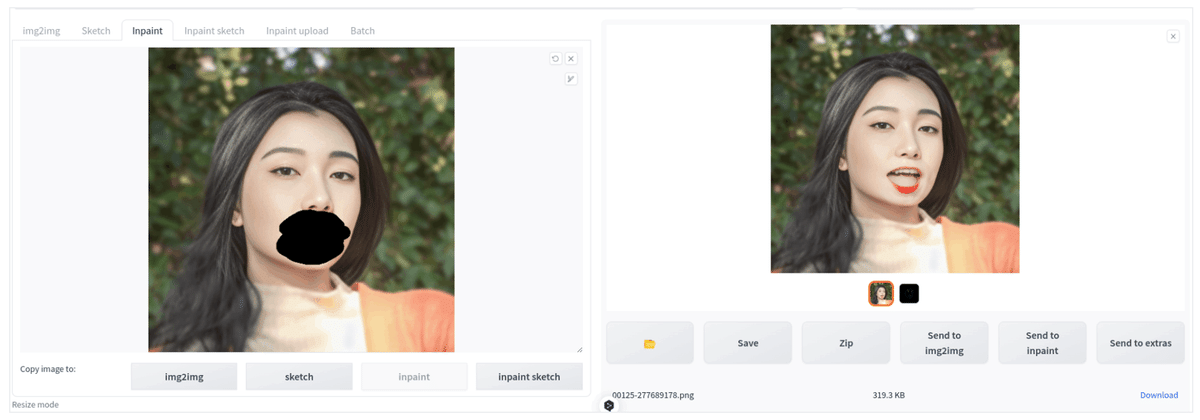
プロンプト
a woman with long black hair and a red shirt, looking at the camera, long black hair, aestheticism, 4K, 8K
Negative prompt: EasyNegative
Steps: 20, Sampler: DPM++ 2M Karras, CFG scale: 7, Seed: 277689178, Size: 512x512, Model hash: e6415c4892, Model: realisticVisionV20_v20, Denoising strength: 0.7, Mask blur: 4,
ControlNet-0 Enabled: True, ControlNet-0 Module: none, ControlNet-0 Model: control_v2p_sd15_mediapipe_face [9c7784a9], ControlNet-0 Weight: 1.55, ControlNet-0 Guidance Start: 0, ControlNet-0 Guidance End: 0.354. img2img(Inpaintingモード) + ControlNet v1.1(Canny + Inpaintingモード)での仕上げ(色味・質感の改善)
・ControlNet v1.1(Cannyモード)はGuidance Endを0.5とした(≒画像生成の始め50%ステップのみ使用)
▶大体の輪郭は元画像の情報を利用しつつ、過度にガイダンス画像に情報を依存しない事で非マスク領域との色味や質感等の親和性を取る形。
・実写画像が対象だと下の生成画像のようにInpaint部分についてちょっと色味が変わってしまったり、その人には無いシワが出てくる等、多少の不自然さが出てくる可能性もあるので、そこは何かしらの後処理が必要な可能性はある。

データ素材について
・下記のリンクの画像を利用した。
[フリー写真] 柵に肘をつけて寄りかかる台湾人女性
・ただし、元画像は低画質なのでCodeFormerによる顔部分の高画質化処理を施した。
アニメ絵への適用
・写実的な人物の画像写実的な人物の画像ではなくアニメ絵的な画風の対象に対してMediaPipeFaceモードを適用し画像生成した場合の結果を示す。
・写実的な対象と違い、アニメ絵の方は質感やパースが崩れても比較的不自然さは少ない形で画像生成が可能である。
▶ただし、ControlNetのPoseモード同様、img2img + ControlNet (MediaPipeFaceモード) についてキャラクターの同一性を保った形で画像生成ができる訳ではない点には注意(一定の工夫は要する)。
▶例えば、下に示す例の"close mouse, smiling"設定・"open mouse, smiling"設定・"close mouth, crying"設定で生成したキャラクターについては、生成設定にそれぞれ同一的な部分も多い一方で服装や瞳、唇等の画風が異なっている事が確認できる。
■MediaPipeFaceモードを利用した画像生成例
"close mouth, smiling"

"open mouth, smiling"

"close mouth, crying"設定

Note
・Controlnet v1.1にはOpenPoseFaceコントロールモードも表情制御用の拡張機能が存在する。
▶こちらはスケルトン情報と併せた一貫性のある認識 + ガイダンス情報の生成を行いたい場合に有用。
▶ただし、顔情報についてはあくまでランドマーク点群から構成されるため、人手でのガイダンス情報編集には向かない。
以上です!
「ControlNet v1.1」は今はさらにバージョン上がってますので、どこかでそれもまとめたいと思います。
次回の投稿もお楽しみに!
文:Hi君
協力:inaho株式会社