
"OmniGen"テキストと画像を組み合わせた革新的な画像生成AIの導入と実行コードについて

OmniGenは、2024年9月17日に論文が公開され、その後、2024年10月22日にGitHub上でコードが公開された最新技術です。
<概要>
OmniGenは、テキストと画像の両方を条件として受け入れ、多様な画像生成タスクを単一のモデルで実行できる新しい拡散モデルです。
要点は、同じ人物の服装やポーズを自由に変えられるところです。
従来のモデル(例:Stable Diffusion)では、ControlNetやIP-Adapterなどの追加モジュールが必要でしたが、OmniGenはこれらを不要とし、以下の特徴を持っています。
統一性: テキストから画像への生成だけでなく、画像編集、被写体駆動型生成、視覚条件付き生成など、多様なタスクをサポートします。さらに、エッジ検出や人間のポーズ認識などの従来のコンピュータビジョンタスクも、画像生成タスクとして処理できます。
簡潔性: 追加のテキストエンコーダーを必要とせず、シンプルなアーキテクチャを採用しています。これにより、複雑なタスクも追加の前処理なしで指示を通じて実行でき、画像生成のワークフローが大幅に簡素化されます。
知識の転移: 統一された形式での学習を通じて、異なるタスク間での知識の共有が可能となり、未知のタスクやドメインにも対応できる柔軟性を持ち、新たな能力も発現しています。
OmniGenは、汎用的な画像生成モデルへの初の試みであり、関連するリソースはオープンソースとして提供されています。
<導入結果>
正直、思っていたよりうまくいかなかったです。私の実力不足もあると思いますので、これからも入力項目を変更して試してみたいと思います。
ただ、まだV1なので、今後がとても楽しみです。気軽に画像内の修正がテキストから自由にできるので面白いです。
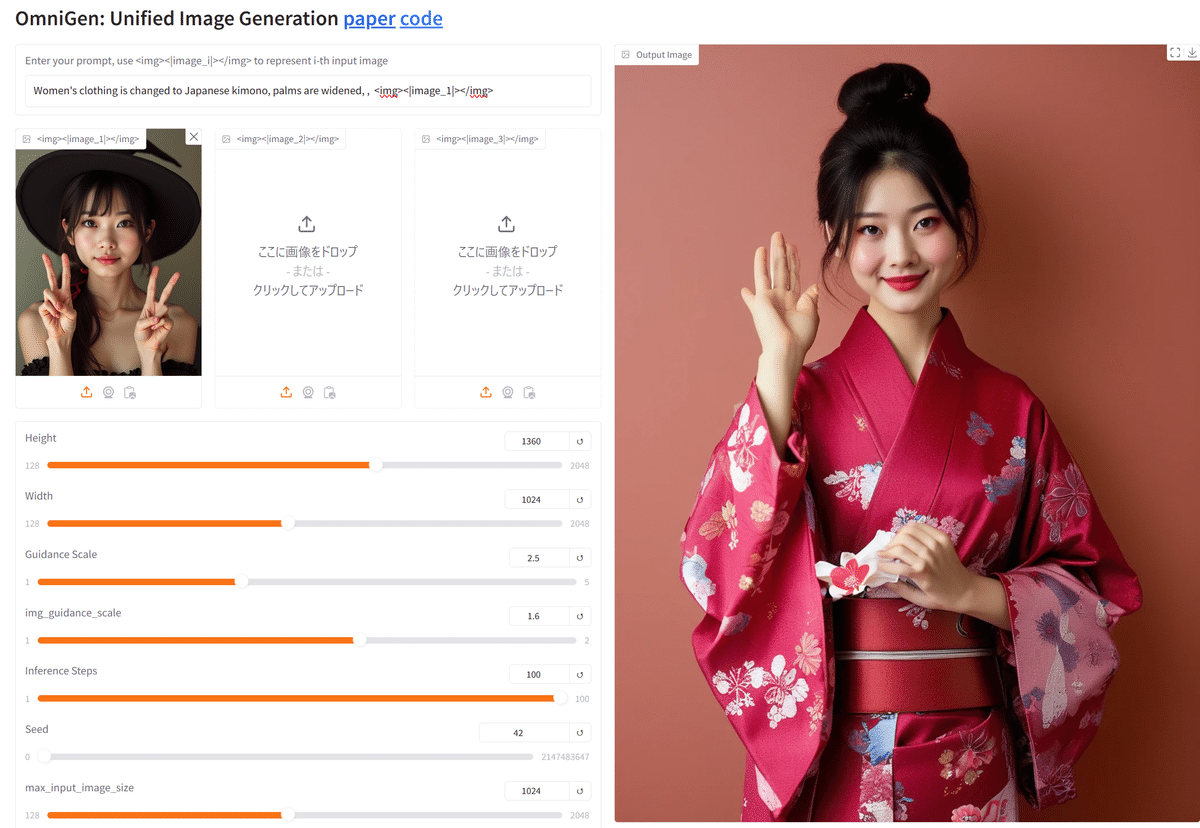
ちなみに、下記が、結果です。一度、FLUXで出した画像を和服に変更して掌を閉じて欲しかったのですが、うまくいきませんでした。
ただ、同じ人に見えるのが凄いです。同一人物といわれると確かにと思うレベルです。
※タイトル画像も、OmniGenで出力したものです。
<導入方法>
ローカルPCではなく、クラウド上でやりたいので、paperspaceでの導入を試行錯誤してやってみましたので、ご説明です。
導入環境
paperspaceのコンテナは前回のFLUXと一緒で大丈夫でした。
インストール
下記のコードで実行しています。
# 必要なパッケージの更新とインストール
%cd /notebooks
!apt update
!apt install -y python3.11 python3.11-distutils python3.11-venv build-essential
# get-pip.pyを使用してpipをインストール
!curl -sS https://bootstrap.pypa.io/get-pip.py -o get-pip.py
!python3.11 get-pip.py
# pipのアップグレード
!python3.11 -m pip install --upgrade pip
# PyTorchのインストール
!python3.11 -m pip install torch==2.4.0+cu124 torchvision==0.19.0+cu124 torchaudio==2.4.0+cu124 --extra-index-url https://download.pytorch.org/whl/cu124
# 必要なパッケージのインストール
!python3.11 -m pip install pickleshare bitsandbytes gradio spaces timm peft transformers matplotlib-inline
# OmniGenのインストール
%cd /notebooks
!git clone https://github.com/staoxiao/OmniGen.git
%cd /notebooks/OmniGen
!python3.11 -m pip install -e .
(app.pyの編集→現在不要)
作成者に連絡したら修正してくださいました。この部分は不要になっているとかと思われます。(11/17時点)
paperspaceだと、シェアリンクが表示されませんでしたので、app.pyスクリプトを以下に修正してください。
GPTのいうとおりに修正したものなので、間違いもあるかもしれません。
※一応動かなくなったら困るので編集前にコピーして保存しておいてください。
import os
import argparse
import gradio as gr
from PIL import Image
from OmniGen import OmniGenPipeline
# モデルとパイプラインの初期化
pipe = OmniGenPipeline.from_pretrained(
"Shitao/OmniGen-v1"
)
def generate_image(text, img1, img2, img3, height, width, guidance_scale, img_guidance_scale,
inference_steps, seed, separate_cfg_infer, offload_model,
use_input_image_size_as_output, max_input_image_size):
input_images = [img1, img2, img3]
# Noneを除外
input_images = [img for img in input_images if img is not None]
if len(input_images) == 0:
input_images = None
output = pipe(
prompt=text,
input_images=input_images,
height=height,
width=width,
guidance_scale=guidance_scale,
img_guidance_scale=img_guidance_scale,
num_inference_steps=inference_steps,
separate_cfg_infer=separate_cfg_infer,
use_kv_cache=True,
offload_kv_cache=True,
offload_model=offload_model,
use_input_image_size_as_output=use_input_image_size_as_output,
seed=seed,
max_input_image_size=max_input_image_size,
)
img = output[0]
return img
def get_example():
# ここに例のデータを挿入します
case = [
# 例のデータを省略
]
return case
def run_for_examples(text, img1, img2, img3, height, width, guidance_scale, img_guidance_scale,
inference_steps, seed, separate_cfg_infer, offload_model,
use_input_image_size_as_output, max_input_image_size):
return generate_image(text, img1, img2, img3, height, width, guidance_scale, img_guidance_scale,
inference_steps, seed, separate_cfg_infer, offload_model,
use_input_image_size_as_output, max_input_image_size)
# コマンドライン引数の処理
parser = argparse.ArgumentParser()
parser.add_argument('--share', action='store_true', help='Make the Gradio interface accessible publicly')
args = parser.parse_args()
# Gradioインターフェースの構築
with gr.Blocks() as demo:
gr.Markdown("# OmniGen: Unified Image Generation [paper](https://arxiv.org/abs/2409.11340) [code](https://github.com/VectorSpaceLab/OmniGen)")
with gr.Row():
with gr.Column():
# テキストプロンプト
prompt_input = gr.Textbox(
label="Enter your prompt, use <img><|image_i|></img> to represent i-th input image", placeholder="Type your prompt here..."
)
with gr.Row(equal_height=True):
# 入力画像
image_input_1 = gr.Image(label="<img><|image_1|></img>", type="filepath")
image_input_2 = gr.Image(label="<img><|image_2|></img>", type="filepath")
image_input_3 = gr.Image(label="<img><|image_3|></img>", type="filepath")
# スライダーやチェックボックスなどの入力
height_input = gr.Slider(
label="Height", minimum=128, maximum=2048, value=1024, step=16
)
width_input = gr.Slider(
label="Width", minimum=128, maximum=2048, value=1024, step=16
)
guidance_scale_input = gr.Slider(
label="Guidance Scale", minimum=1.0, maximum=5.0, value=2.5, step=0.1
)
img_guidance_scale_input = gr.Slider(
label="img_guidance_scale", minimum=1.0, maximum=2.0, value=1.6, step=0.1
)
num_inference_steps = gr.Slider(
label="Inference Steps", minimum=1, maximum=100, value=50, step=1
)
seed_input = gr.Slider(
label="Seed", minimum=0, maximum=2147483647, value=42, step=1
)
max_input_image_size = gr.Slider(
label="max_input_image_size", minimum=128, maximum=2048, value=1024, step=16
)
separate_cfg_infer = gr.Checkbox(
label="separate_cfg_infer", info="メモリ使用量を削減します。", value=True,
)
offload_model = gr.Checkbox(
label="offload_model", info="モデルをCPUにオフロードします。", value=False,
)
use_input_image_size_as_output = gr.Checkbox(
label="use_input_image_size_as_output", info="入力画像と同じサイズで出力します。", value=False,
)
# 画像生成ボタン
generate_button = gr.Button("Generate Image")
with gr.Column():
# 出力画像
output_image = gr.Image(label="Output Image")
# ボタンがクリックされたときの動作を定義
generate_button.click(
generate_image,
inputs=[
prompt_input,
image_input_1,
image_input_2,
image_input_3,
height_input,
width_input,
guidance_scale_input,
img_guidance_scale_input,
num_inference_steps,
seed_input,
separate_cfg_infer,
offload_model,
use_input_image_size_as_output,
max_input_image_size,
],
outputs=output_image,
)
# インターフェースの起動
demo.launch(share=args.share)
実行コード
下記で実行します。
# Python関係パッケージの導入
!apt update
!apt -y install python3.11 python3.11-distutils python3.11-venv libpython3.11-dev build-essential
# pipのインストール
!curl -sS https://bootstrap.pypa.io/get-pip.py -o get-pip.py
!python3.11 get-pip.py
# pipのアップグレード
!python3.11 -m pip install --upgrade pip
# 必要なパッケージのインストール
!python3.11 -m pip install pickleshare
!python3.11 -m pip install torch==2.4.0+cu124 torchvision==0.19.0+cu124 torchaudio==2.4.0+cu124 --extra-index-url https://download.pytorch.org/whl/cu124
!python3.11 -m pip install bitsandbytes
!python3.11 -m pip install gradio
!python3.11 -m pip install spaces
!python3.11 -m pip install timm
!python3.11 -m pip install peft
!python3.11 -m pip install transformers
!python3.11 -m pip install matplotlib-inline
# OmniGenのインストール
%cd /notebooks/OmniGen
!python3.11 -m pip install -e .
# 環境変数の設定
import os
os.environ['BNB_CUDA_VERSION'] = '124'
os.environ['LD_LIBRARY_PATH'] = os.environ.get('LD_LIBRARY_PATH', '') + ':/usr/local/cuda/lib64'
os.environ['MPLBACKEND'] = 'Agg'
# シンボリックリンク作成(上書き)
!ln -sf /usr/local/cuda/lib64/libcudart.so /usr/local/cuda/lib64/libcudart.so.11.0
!ln -sf /usr/local/cuda/lib64/libcudart.so /usr/local/cuda/lib64/libcudart.so.12.0
# スクリプト実行
%cd /notebooks/OmniGen
!python3.11 app.py --share
<画像生成>
上の方にでる欄にプロンプトを入れてください。
注意点は、どの画像を使用するか”<img><|image_1|></img>”のように 入れる必要があることです。
番号は左から1,2,3です。

<img><|image_1|></img> Women's clothing is changed to swimsuit , ・STEP数は、50だと少ないように見えますので、増やした方が良いと思います。
・入力画像と同じサイズで出力すると綺麗にでます。
use_input_image_size_as_outputにチェックしてください。
・変更が終了したら、一番下の"Generae Image "をクリックしてください。
・待っていると、画像が右側に表示されます。

<デモと詳細>
色々なことができますので、詳細はHPから確認してみてください。デモもできますので、試してみてください。
<最後に>
最新のAI技術はやっぱり楽しいと思います。
皆様にもこれをきっかけに触れていただけると嬉しいです。
何か間違いなどありましたら、教えてください。