
♡恋愛で学ぶ統計学♡(No.10 構造方程式モデリング③モテ要素を探索せよ!)

今回も、構造方程式モデリングをつかって、「モテの構造」を解き明かしていきましょう!
構造方程式モデリングってなに?という方は、ぜひ私の以前かいた記事を読んでください!
構造方程式モデリング
簡単に、構造方程式モデリングを説明すると、「モテるとか、コミュニケーション力とかいうフワッとした概念も含めた関係性を、1度に分析しちゃう統計方法」です。

図で表すと、こんな感じです!
「モテる」状態に影響を与えるのは、「清潔感」や「頭の良さ」や「お金持ちかどうか」や「コミュニケーション力」なのではないか?という仮説をもとにモデルを作り、統計ソフトで処理したものです!
前回の記事の最後にも書きましたが、実はこのモデルは、あまりいいモデルではないのです、、、
右下のRMSEAという数値に注目してください。1.608となっています。
このRMSEAというのは、モデルの出来が良いかを判断する1つの指標になります。そして、その値は0.05以下が望ましいです。つまり、1.608という数値は、かなりまずい状態です(;^ω^)
しかも、このモデルを信じてしまったとします。
上の方にあるモデルの図にある「お金持ち」から「モテる」に刺さった矢印を見てください。(小さく見にくくて、すいません、、、、)
その数値は-0.31となっています。つまり、「お金持ち」であればあるほど、「モテる」状態にマイナスの影響を与えることが示されています。「お金持ち」になればなるほどモテなくなるようです、、、、
本当にそうですかね?(笑)
ということで、モデルを修正していきたいです。しかし、ただやみくもに修正してはいけません。私たちがやっている構造方程式モデリングはとても便利なのですが、よいモデルになるようにモデルを改変しすぎると意味がないのです。
例えば、なにも考えず、「RMSEAの数値をよくしたいからコミュ力の要素を消そう!」と考え、その結果「RMSEAの数値をよくなった!わーい!」と言ったとします。しかし、コミュ力は、感覚的に考えても「モテる」ためには重要な要素のはずです。つまり、モデルの出来の良さにばかり焦点をあて、構造を変えてしまうと、本来あるべき要素まで削ってしまった、別の意味で出来の悪いモデルになるのです、、、、
そんな状況を防ぐため、実は、仮説を立て、データを集めた後、モデルをつくる前にやっておくとよい統計方法があります。それは、
探索的因子分析です!
因子分析
統計方法のなかに「因子分析」というものがあります。
その「因子分析」には大きく2種類あります。「確証的因子分析」と「探索的因子分析」です。
分析をする前に、既に分析に関する理由(先に行われた研究)がある場合は、こうなるはずだ!という「確証」があります。ですので、「確証的因子分析」というものを行います。
じつは、前回の記事で行っていたのは「確証的因子分析」だったんです!でも、全然確固たる確証が得られないまま分析を始めていましたよね(;^ω^)
ということで、本来であれば、さきに集めた因子がどのような関連があるのかを「探索」してから分析するべきだったのです!
もう少し因子分析について説明します。
因子分析はこれまで行ってきた回帰分析と考え方が違います。

この図を見てください。
まず大きな違いは、矢印の方向ですね。因子分析では、実際に測れるものに、何か隠れた共通の因子があるのではないか?それを見つけたい!という思いで分析をします。一方回帰分析は、集めた実際の数値をもとにそれらの関係性を予測するため、知りたい1つのものにいくつかのものがどれだけ影響を与えるのか?というのを知りたくて分析します。
では、まず「探索的因子分析」について、考えていきましょう!
探索的因子分析
探索的因子分析は、その名の通り、「探索」するのが目的です。集めたデータには、どんな共通の隠れた因子があるのかを探します!
では、具体的に、私たちが考えるモテの構造をもとに考えていきましょう!
まずは、前回の記事で作ったアンケート項目を確認します。
1.月収はいくらか?
2.ブランドものをいくつ持っているか?
3.最終学歴の学校の偏差値は?
4.1か月に何冊の本を読むか?
5.1か月に髪型や服に払う代金は?
6.もっているファッション雑誌の数は?
7.一日に、鏡などで自分の姿を何回みる?
8.SNSでのフォロワーや友達の数は?
9.人と話すことが好きか(7段階評価)
10.人の話を聞くことが好きか(7段階評価)
11.何人と付き合ったことがある?
12.今年のバレンタインで異性から何個チョコをもらった?
でした。では、このアンケート結果を探索的因子分析しましょう!
まず、「モテる」という因子が影響して、付き合ったことがある人数や異性からもらうチョコの数が変わると想定し、質問11と12の結果が1因子で説明できるかどうかを調べます!図にすると
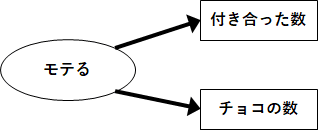
こうなるかを調べるということです!
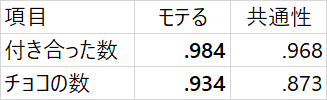
となりました。両方とも、0.9以上という、かなり高い数値が出ていますね!(ちなみに、1に近い値ほど、影響があると考えます。)
また、ω係数という、この因子の構成の信頼度を示す値も調べました。すると0.922という、これまた高い数値が得られました。よって、この「モテる」という因子はOKです!
では、つぎに質問1から9までの質問がどんな因子から影響を受けているのかを分析しましょう。まずは、、、、1因子で説明できるかを考えます!
つまり、こんな図になるかも、、、という仮定で分析します。
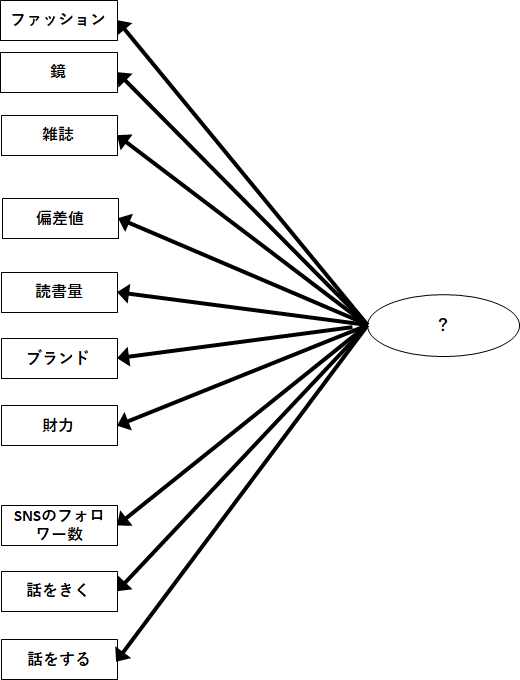
その結果は、、
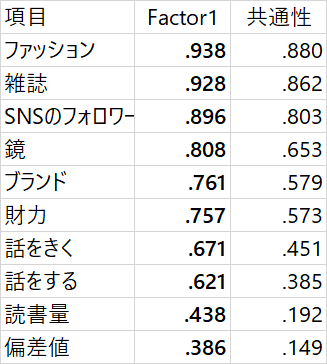
こんな感じです。ちなみにω係数は0.74でした。うーん、やはり項目が多いものを1つに集めようと知ると、少し無理がでてきました。例えば、偏差値や読書量が少し仲間はずれな感じがしますね、、、
では、2因子で分析してみました。すると
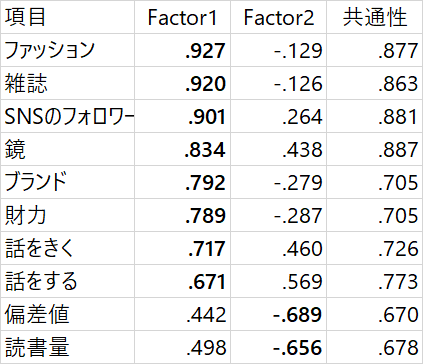
こんな感じに、やはり偏差値と読書量は、別の因子として扱ったほうがいいようです。ω係数も0.823と高まりました。
では、ここで、因子に名前を付けようと思います。この名前は、統計処理ソフトが提案をしてくれないので人間が作ります。Factor1は、ファッションにお金をかけ、しかもSNSのフォロワー数も多くなって、ブランドを着こなし、人と交流するのが好きな人を表すような因子です、、、ということで「陽キャ度」ですね。
そして、偏差値と読書量は合わせて「知性」という因子の名前にします。
では、この探索的因子分析をもとに、もう一度構造方程式モデリングを行いたいと思います!
構造方程式モデリングを再挑戦

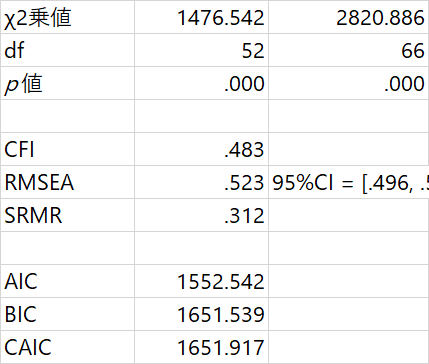
うーん、、、、まだRMSEAが0.05以下になっていませんね、、、
原因として考えられるのは、「陽キャ度」という因子にたくさん詰め込みすぎているからですね、、、
このように探索的因子分析を行って因子を分け、そのまま構造方程式モデリングをおこなっても上手くいかないことがあります、、、
いくつかの因子を調整してみましたが、やはりモデルの出来のよさは変わりませんね、、、
つまり、ここから言えるのは、調べる項目の仮説が間違っていたか、調査がうまく行えていなかったか、、、、
もう少しデータ数を増やして再度実行してみる価値はあるかもしれません、、、じつは、今回は100人分のデータで分析をしています。
構造方程式モデリングをおこなう際に、何人分のデータがあるといいのかという問題は、昔から議論されていますが、はっきりした答えはありません。
しかし、一般にはできる限り大きいサンプルサイズである方がよいです。例えば、最低200のサンプルが欲しいという学者もいます。
ですので、データ数が足りていないため十分なモデルが作れないという可能性もあります。
やはり、「人間」や「世の中」の構造を解き明かすのは難しいですね、、、
でも、あきらめません!
データを増やして、再挑戦します!
では、また!