
便利なPythonライブラリ①~可視化編~

本記事は、Pythonライブラリを取り上げ、簡単な使用例と共に紹介する連載シリーズ(予定)です。
numpyやpandasなど、書籍やWeb上に情報が広がっている一般的なライブラリではなく、マイナーだけど意外と便利かも!というライブラリを発掘することが目的です。
※本記事で紹介しているライブラリのインストールについては、自己責任でお願いします。
今回は、「探索的データ解析(EDA)」に関するライブラリを簡単な使用例と共に紹介します。
① pandas-profiling
② AutoViz
pandas-profiling
(ライブラリ:github)
データは、お馴染みtitanicのデータセットを利用します。
githubに記載のある主な機能を列挙すると
・変数の型を検出、ユニーク値、欠損値
・最小値や最大値、四分位数、平均値など基本統計量
・ヒストグラム
・変数同士の分布(散布図)や相関関係(ヒートマップ)
・各変数に対するアラート(欠損値の割合や値のユニークさなど)
※今回は確認していませんが、DataFrameに格納されたテキストや画像に対しても出力をしてくれるみたいです。
import pandas as pd
import pandas_profilig as pdp
# 本記事ではほかの可視化ライブラリを比較用に用いるのでimportします。
from matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
# titanicデータの読み込み
titanic = pd.read_csv('train.csv')例えば、titanicデータの目的変数である"Survived"を可視化して、特徴を見ることにしましょう。
まずは、matplotlibを使う場合。
# use matplotlib
summary = titanic.groupby(['Survived'])['Survived'].count()
plt.figure()
plt.bar(summary.index, summary.values)
plt.xticks([0, 1], ['Not survived', 'Survived'])
plt.show()
一番ベーシックなライブラリなだけあって、複数行のコードで設定する必要があります。
次に、matplotlibのwrapperであるseabornを使う場合。
# use seaborn
sns.countplot(x='Survived', data=titanic)
wrapperなだけあって、1行でこれだけの見た目ができるのはありがたいですね。
ついでに、pandasでも同様のグラフを出力できます。
# use pandas
titanic['Survived'].value_counts().plot.bar()
こちらも1行で出力できますが、seabornと比較すると物足りない気がしますね。
それでは、本題のpandas-profilingで同様の結果を出してもらいましょう。
profile = pdp.ProfileReport(titanic)
profile
# 出力を外部ファイルとして出力したい場合。
#profile.to_file(outputfile='titanic_eda.html')
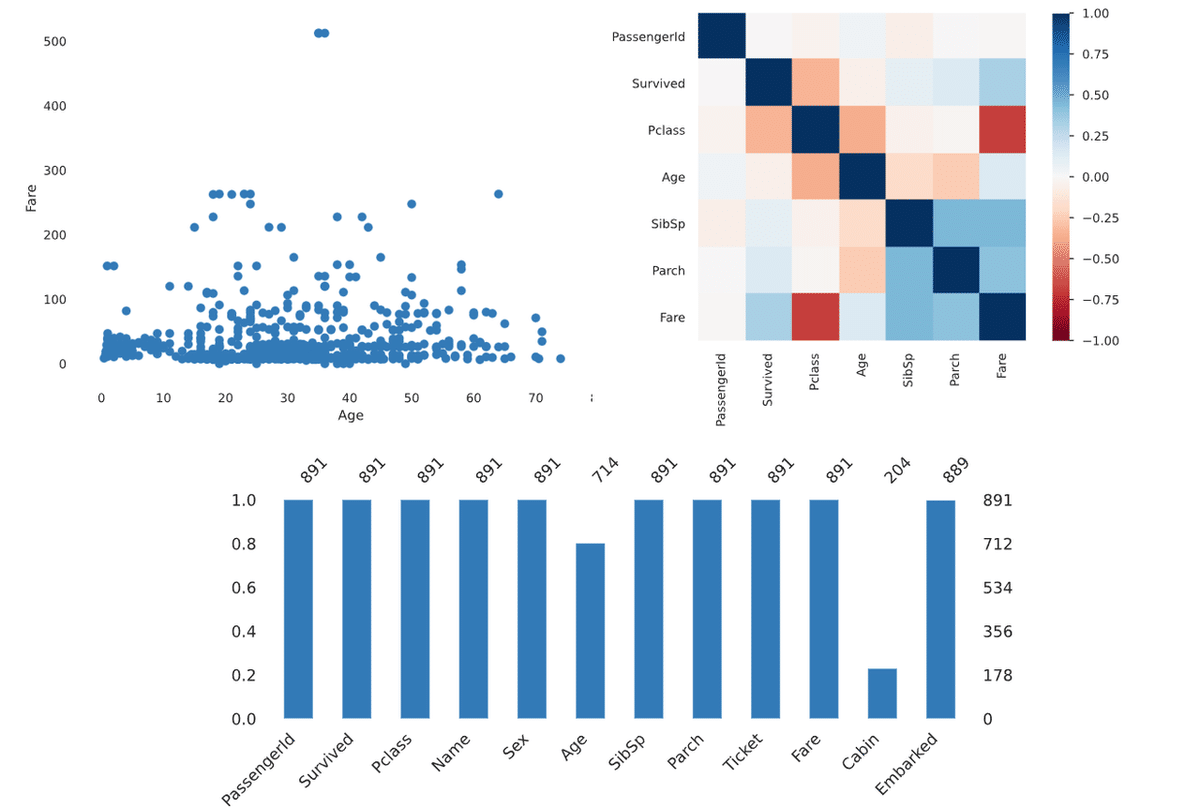
なんと画像右上のグラフだけではなく、各変数に対する定量的なサマリなども併せて出力されます。
画像は"Survived"だけですが、他の変数についても一度に出力をしてくれます。
記事冒頭に挙げたように、散布図やヒートマップ、欠損値に関する情報も可視化してくれます(出力の一部を切り貼りしています)
とりあえず、各変数単体での特徴を把握したい場合は下記のように
minimal=Trueというオプションを有効にしてください。
profile_minimal = pdp.ProfileReport(titanic, minimal=True)
profile_minimal実際にpandas-profilingから出力されたレポートを公式が公開しており、見ることができます(Link)
本来、pandasで統計量を確認して、matplotlibやseabornではDataFrameから各変数名を指定して、適したグラフ形式で少しずつ見ていくかと思いますが、pandas-profilingを使うと、特に特別な処理も必要なく、変数ごとや変数間の関係含めて、データ全体の特徴を把握することができるようです。
AutoViz
(ライブラリ:github)
ライブラリ名通り、探索データ解析(EDA)が楽になりそうです。
こちらのライブラリはseabornをベースとして可視化しているようです。
titanicのデータで、早速使ってみましょう。
from autoviz.AutoViz_Class import AutoViz_Class
aviz = AutoViz_Class()
dft = aviz.AutoViz('train.csv')AutoVizのインスタンスを定義し、可視化したいデータのファイルパスを渡してあげるだけで下のような結果が得られます。
Shape of your Data Set loaded: (891, 12)
############## C L A S S I F Y I N G V A R I A B L E S ####################
Classifying variables in data set...
Number of Numeric Columns = 2
Number of Integer-Categorical Columns = 3
Number of String-Categorical Columns = 1
Number of Factor-Categorical Columns = 0
Number of String-Boolean Columns = 1
Number of Numeric-Boolean Columns = 1
Number of Discrete String Columns = 2
Number of NLP String Columns = 0
Number of Date Time Columns = 0
Number of ID Columns = 2
Number of Columns to Delete = 0
12 Predictors classified...
This does not include the Target column(s)
4 variables removed since they were ID or low-information variables
Number of All Scatter Plots = 3
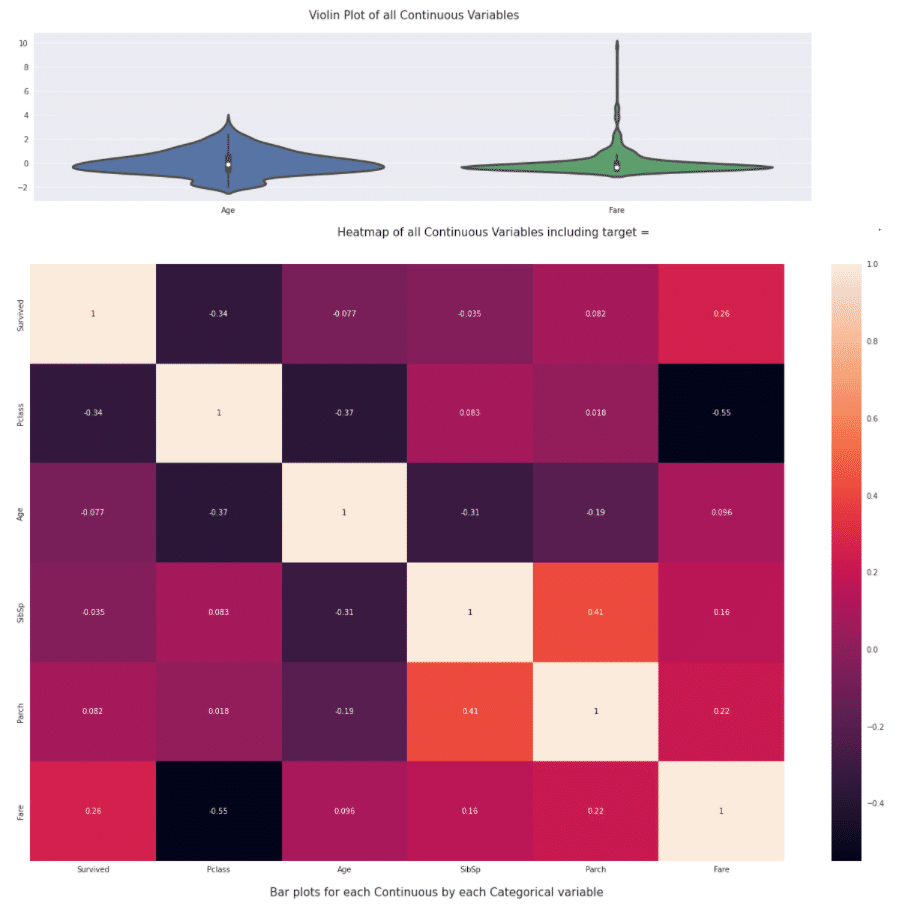

内部処理(決められた基準)で、変数ごとの型を判定しそれに応じて様々なグラフが出力されています。
例えば、Fare(運賃)とAge(年齢)が数値型と判定されているので、2変数の散布図や分布が出力されています。
また、目的変数を指定して、目的変数との関係に注目した結果を出すこともできるようです。(depvarに変数名を指定します。)
先ほどは、ファイルパスを渡しましたが、DataFrameで読み込んでいるデータを代わりに渡すこともできます。
# depVarはターゲット変数を表し、指定するとdepVarに従ったグラフが表示される
# filenameは必須引数で、すでにpandasで読み込んだDataFrameを引数として入れる場合は、''を指定する。
aviz.AutoViz('', dfte=titanic, depVar='Survived')

画像例のように、目的変数であるSurvivedを軸として、他の変数との関係性をグラフ化してくれています。データを使って解くタスクが、分類か回帰かでグラフの読み取り方や有用性も変わってきそうです。
※デフォルトの処理ですが、カテゴリ変数の値別にSurvivedを平均化して、可視化すると読み取りにくくなりそうです。
pandas-profilingと比較すると、"可視化"が主な機能であるため、変数の定量的な統計量は別で把握する必要がありますが、変数間の関係性を把握するには簡単に出力できるので便利そうですね。
まとめ
主に探索的データ分析(EDA)を楽にするライブラリ2つ取り上げました。
どちらも様々な情報を楽に出力してくれているので、コードや可視化するグラフで悩む時間が大幅に削減できます。
ただ、変数の特徴を詳細に把握する必要がある場合には、やはり原点であるmatplotlibなどを使う必要があります。目的や状況に応じて、ライブラリも使い分けられるとベストですね。
「こんなライブラリありますよ」「あんなライブラリあったら便利ですよね」などお気軽にコメントお寄せください!
読んでいただきありがとうございました。