
自然言語処理に歩み寄る#3

前回の記事では、コンピュータに文章を理解させるためのベクトル化(=文字を数値化)する2つの方法のうち、カウントベースの手法を説明し、サンプルデータを使って、コードを動かしてみました。
カウントベースの手法では"計算量の増大"(=$${O(n^3)}$$)や、文書内における"単語の順序などの関連性を考慮できない"という課題があります。今回は、この課題を解決する「推論ベース」の手法について説明します。
推論ベースの手法
推論ベースとは、周囲の単語が与えられたときに対象となる箇所の単語を推論するようなモデルを構築することで、ベクトルを得ることができます。
また、カウントベースでは、データ全体から一度にベクトル化を行いますが、推論ベースでは、データの一部を繰り返し取り出しながらベクトル化を行います。
まずは、代表手法である「word2vec」について説明します。
word2vec
word2vecとは、推論ベースの手法で単語をone-hot表現に変換し、ニューラルネットワークを用いて、単語を推測するモデルです。その推測を行う過程で、単語のベクトルを得られます。
word2vecでは、"CBOWモデル"と"skip-gramモデル"の2モデルを用います。
参考にした書籍の例文を用いて、説明します。
(例) you say goodbye and I say hello .
CBOWモデルでは、周辺の単語(コンテキスト)から中心の単語(ターゲット)を推論します。
※CBOW:Continuous Bag Of Words
例)「you」と「goodbye」に囲まれた単語、1つ目の「say」を推論する

skip-gramモデルでは、中心の単語から周辺の単語を推論します。
例)1つ目の「say」から周辺の単語「you」と「goodbye」を推論する
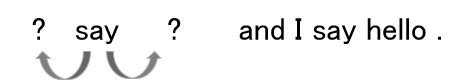
一般的なword2vecでは、ディープラーニングのような多層で構築されず、中間層と出力層の2層で構築されます。

CBOWモデルを例にニューラルネットワークの構造を見ると、入力層では、周辺の単語をone-hot表現に変換して、入力します。中間層で、入力から特徴を抽出して、文章中に出現する単語のスコアをSoftmax関数を用いて、確率として出力します。
損失関数を設定して、正しく予測ができるように"重み"を学習していきます。
これは、一般的なニューラルネットワークモデル(教師あり学習)と同じ学習方法であり、ここで得られた重みが、単語のベクトルとなります。
また、skip-gramモデルでは、入力層と出力層が逆転するイメージです。
仕組みが分かったところで、実際にプログラムで触ってみます。
飛躍的な技術の発展
word2vecは、2013年に登場した考え方ですが、そこから次々と優れた考え方が登場し、自然言語処理を発展させています。
word2vecに考え方が近い手法としては、以下の2つが挙げられます。
■ GloVe
カウントベースの手法と推論ベースの手法の良さを組み合わせた手法です。
カウントベースではデータ群全体からの情報(グローバル)、推論ベースでは一部のデータからの情報(ローカル)を学習して、ベクトル化を行います。
■ fastText
word2vecを考案したMikolov氏が、word2vecを発展させ、学習を圧倒的に高速化させた手法です。10分以内で10億語を学習できるというスピードだそうです。
特徴としては、Negative Samplingと階層的Softmax、ハッシュトリックという3つの工夫により圧倒的な高速化を実現しているそうです。
また、doc2vecという文章や文書をベクトル化する手法も考案されました。これを用いることで、ニュース記事や本の類似度などを求めることができます。
【実践】livedoorニュースのデータで各手法を動かしてみる
今回、メインで説明したword2vecに加えて、発展形であるfastTextとGloVeについても実際にプログラムを動かしてみます。
前回の記事と同様にlivedoorニュースコーパスを使用します。
<動作環境>
Python 3.6.8
Jupyter Notebook 5.6.0
gensim 3.8.3
mecab-python3 1.0.3
データの準備をします。今回は、全てのデータを利用します。
import os
import MeCab
import gensim
import re
# データのダウンロードは前回の記事を参照ください
files = []
categories = os.listdir('data/livedoor/text')
# 各カテゴリのファイルを取得する
for category in categories:
match = re.search('.txt', category)
if not match:
file_list = os.listdir(f'data/livedoor/text/{category}')
files.append(file_list)
parent_path = 'data/livedoor/text'
docs = []
for category, f_list in zip(categories, files):
text = ""
match = re.search('.txt', category)
if match:
continue
for fi in f_list:
with open(f"{parent_path}/{category}/{fi}", 'r', encoding='utf-8') as f:
lines = f.read().splitlines()
url = lines[0]
datetime = lines[1]
subject = lines[2]
body = "¥n".join(lines[3:])
text = subject + "¥n" + body
# ストップワード(文章中で不要な記号などを削除)
stop_chars = "¥n,.、。()()「」【】[]『』!!??-::■・—'"
for stop_char in stop_chars:
text = text.replace(stop_char, " ")
text = text.replace('\u3000', "")
docs.append(text)また、日本語の形態素解析にはMecabを使います。
# 形態素解析の処理を定義
mecab = MeCab.Tagger()
def tokenize(text):
node = mecab.parseToNode(text)
lists = []
while node:
if node.feature.split(',')[0] in ['名詞', '動詞', '形容詞', '形容動詞']:
lists.append(node.surface)
node = node.next
return lists各文書ごとに得られる形態素の集合をリストにします。
# 単語のトークナイズ/リスト化
words = []
words_separate = []
for doc in docs:
res = tokenize(doc)
words_separate.append(res)
words.append(res)これで、推論ベースの手法に入力する準備は完了です。
早速、ベクトルを獲得するためのモデルを作成します。
word2vecは自然言語処理ライブラリであるgensimから、下記1行で利用でき、word2vecモデルの学習が実行できます。
# word2vec
from gensim.models import word2vec
"""
Word2Vec(words, sg=1, size=1000, window=5, min_count=20)
words:
文書ごとの単語リスト
sg:
学習方法(sg=0であれば、CBOWモデル。sg=1であれば、skip-gramモデル)
size:
ベクトルの次元数
window:
周辺の単語数
min_count:
指定した出現頻度以下の単語を辞書から除く
"""
model = word2vec.Word2Vec(words, sg=1, size=1000, window=5, min_count=20)学習完了後、most_similar()を使って指定した単語に類似した単語とその類似度(コサイン類似度, 1に近いほど類似)を参照します。ただし、指定できる単語と参照される単語は、学習で使用した単語のみです。
print(model.wv.most_similar(positive=["パソコン"]))Output(「パソコン」と似ている単語、上位10件が得られる)
[('ノート', 0.5892500877380371),
('nPC', 0.5845528841018677),
('デスクトップ', 0.5827609300613403),
('PC', 0.5738839507102966),
('Kies', 0.5700550079345703),
('DisplayDock', 0.5517295598983765),
('使い勝手', 0.54859459400177),
('持ち歩い', 0.544645369052887),
('マカフィー', 0.5434904098510742),
('nUltrabook', 0.543280839920044)]指定した単語同士の類似度も算出することができます。
# word2vecにおける単語同士の類似度
print(model.wv.similarity(w1='パソコン', w2='PC'))
# => 0.5738839
print(model.wv.similarity(w1='パソコン', w2='おにぎり'))
# => 0.22363046パソコンとPCは、同義語ですので学習した文書では同じような単語が周りに現れていたと予想できます。パソコンとおにぎりは、類似度が低いことがわかります。
次に、fastTextモデルを作成してみます。こちらもgensimを使うと、簡単に学習を実行することができます。
# fastText
from gensim.models import FastText
# 引数はword2vecと同様
model_ft = FastText(words, sg=1, size=1000, window=5, min_count=20)学習で得られたベクトルをもとに、類似した単語上位10件や単語の類似度を確認します。
print(model_ft.wv.most_similar("パソコン", topn=10))Output(類似した単語上位10件)
[('PC', 0.5918903946876526),
('デスクトップ', 0.5841162800788879),
('ノート', 0.5705883502960205),
('持ち歩い', 0.5513677597045898),
('DisplayDock', 0.537821888923645),
('デバイス', 0.5321115255355835),
('ノートン', 0.5276472568511963),
('持ち歩く', 0.5224004983901978),
('マカフィー', 0.5204453468322754),
('ガラケー', 0.5187785625457764)]学習の仕方が異なるためword2vecの結果と多少異なりますが単語の特徴は捉えられているようです。正確な精度はこの結果からは比較できないので、本記事では触れません。
# fastTextにおける単語同士の類似度
print(model_ft.wv.similarity(w1='パソコン', w2='PC'))
# => 0.5918904
print(model_ft.wv.similarity(w1='パソコン', w2='おにぎり'))
# => 0.2208773次に、GloVeを動かしてみますが、gensimでは動かせないので環境構築をします。(詳細はこちらを参照ください)
GloVeへの入力形式に合わせるため、文書ごとの単語リストをテキストファイルに書き込みます。
with open('./input.txt', 'w', encoding='utf-8') as f:
for doc in words:
f.write(' '.join(doc))
f.write('\n')GloVeのモデル作成は、コマンドラインで実行していきます。
引数は、word2vecやfastTextと同様の条件で進めます。
# jupyter上での実行ですので、行頭に ! をつけています
!./glove/build/vocab_count -min-count 20 -verbose 2 < input.txt > vocab.txt
!./glove/build/cooccur -memory 4 -vocab-file vocab.txt -verbose 2 -window-size 5 < input.txt > cooccurrence.txt
!./glove/build/shuffle -memory 4 -verbose 2 < cooccurrence.txt > cooccurrence_shuffle
!./glove/build/glove -save-file vectors -threads 2 -input-file cooccurrence_shuffle -x-max 10 -iter 5 -vector-size 1000 -binary 2 -write_header 1 -vocab-file vocab.txt -verbose 2上記実行完了後、vectors.txtというファイルが出力されます。これが学習で得られた単語のベクトルになります。
こちらをgensimで読み込み、類似度などを算出できるようにします。
import pandas as pd
from gensim.models import KeyedVectors
vectors = pd.read_csv('./vectors.txt', delimiter=' ', index_col=0, header=None)
# GloVeで出力されるテキストファイルの先頭に必要な情報を追記
with open('./vectors.txt', 'r', encoding='utf-8') as vec, open('./gensim_vectors.txt', 'w', encoding='utf-8') as output:
vocab_count = vectors.shape[0]
size = vectors.shape[1]
output.write(f'{vocab_count} {size}\n')
output.write(vec.read())
# 単語のベクトルをgensimで読み込む
glove_vectors = KeyedVectors.load_word2vec_format('./gensim_vectors.txt', binary=False)GloVeのモデル作成はgensimでは不可能ですが、単語の類似度は他の手法と同様に算出できます。
print(glove_vectors.wv.most_similar("パソコン", topn=10))[('PC', 0.8186936378479004),
('ノート', 0.7408326268196106),
('使う', 0.7176207900047302),
('快適', 0.6982277631759644),
('接続', 0.6888411045074463),
('古い', 0.6739621758460999),
('デバイス', 0.6720364093780518),
('使え', 0.6583031415939331),
('デスクトップ', 0.6570156812667847),
('タブレット', 0.656435489654541)]"パソコン"という単語に対して、GloVeで得られる類似単語上位10件ですが、"快適"や"古い"など、他の2手法と異なる単語が挙げられています。GloVeのロジックとして、文書中のデータ一部だけではなく、データ全体における単語の特徴が学習に反映されていることが伺えます。
# GloVeにおける単語同士の類似度
print(glove_vectors.wv.similarity(w1='パソコン', w2='PC'))
# => 0.81869376
print(glove_vectors.wv.similarity(w1='パソコン', w2='おにぎり'))
# => -0.45428166最後に、筆者の環境で学習に要した時間をまとめます。
word2vecを改良し、高速化した手法のはずであるfastTextとGloVeの学習に時間がかかっていることが疑問です。(iterationなど学習条件は揃えたはずですが・・・)原因が分かったら、追記します。
$$
\begin{array}{l:r}
\textbf{手法} & \textbf{学習時間(s)} \\ \hline
word2vec & 84.1 \\
fastText & 547.6 \\
GloVe & 120.0
\end{array}
$$
このように単語をベクトル化することで単語同士を比較し、類似度を算出できるため、様々なテキスト入力のあるエンジンでのレコメンドに活用することができます。
また、各手法で得られる単語のベクトルを特徴量(入力)として、機械学習アルゴリズムに適用して、分類問題などもできます。
挙げられる問題
本記事で取り上げた手法は、文脈を考慮しない手法と言われています。文脈を考慮しない、とは、例えば「松本」という単語の場合、人名を表す「松本」なのか、地名(長野県にある市)を表す「松本」なのかを区別できない、同じベクトルとして扱ってしまう、という問題があります。
この問題を解決した手法、つまり文脈を考慮してベクトル化を行える手法がBERTです。
まとめ
今回、推論ベースの手法であるword2vecと発展形であるfastTextとGloveをプログラム上でモデル構築、つまりベクトル獲得できる状態まで行いました。
自然言語処理のモデルは、約10年前に考案されたword2vecから現在のBERTやGPT-3に代表されるようなモデルまで、急速に進歩を遂げています。技術のキャッチアップを続けないと、どんどん置いてけぼりにされてしまうことが怖いですね。
次回は、RNNやLSTM、BERTについて記事にする予定です。
最後まで読んでいただきありがとうございました。
<参考文献>
・斎藤 康毅「ゼロから作るDeep Learning② 自然言語処理編」, O'Reilly Japan, 2018年7月(Link)
この記事が気に入ったらサポートをしてみませんか?