
Pythonの呼吸 壱ノ型 情報時雨・改

21年7月にpandasで仕様変更があったらしくpdr.DataReaderからget_data_yahooへ変更したのを簡単にまとめました
グーグルコラボやpythonのプログラムがある程度分かって
株価データの取得の仕方がわからない人用です
きちんと確認していないけどデータは多分20分遅れです
当日終値を確定で取り込みたい時は注意が必要です
python1年ぐらいしかやってなくてプログラミング10か月ぶり位だけどw

いくつか事前準備と初期設定
グーグルのColaboratoryを使ってます(個人環境に合わせて使って下さい)
ドライブのマウントを行ってください
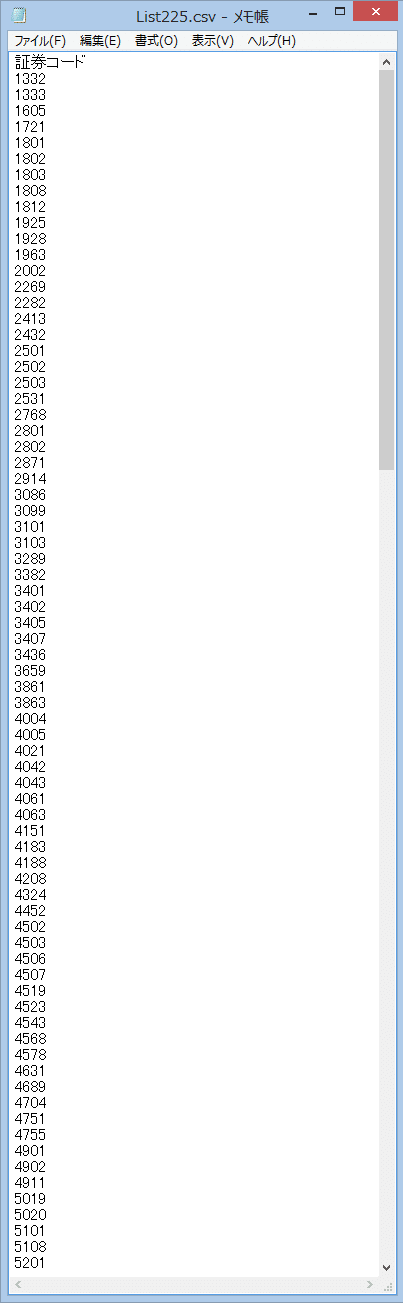
任意の場所にCSVファイルを作成して下さい
今回はColab Notebooks/CSVフォルダに225銘柄のCSVファイルを作成
List225.csv ※エンコードはUTF-8にして下さい
直接プログラム内で証券コードを code_list =(9983,9984)のように
指定する場合は必要ありません
CSVファイルの1行目の証券コードとプログラム10行目の"証券コード"を同じにして下さい、同じにしないと取り込めなくなります
CSVの方をコードにしたら、プログラムの方も"コード"という感じに!
プログラム

pipでyfinanceとworkdaysをインストールします
workdaysは日付指定で2022-8-23からとか指定する場合は必要ありません
何日前とかの指定で祝日を除きたい場合に使用します
pip install yfinancepip install workdays
import datetime
import os
import pandas as pd
import pandas_datareader.data as pdr
import yfinance as yf
import workdays
os.chdir("/content/drive/My Drive/Colab Notebooks") # ディレクトリ変更(グーグルドライブのマウント必要、読み書きするCSVファイルはここに)
df = pd.read_csv("./CSV/List225.csv", encoding="utf-8-sig", sep=",") # 上記ディレクトリにCSVフォルダの中のCSVファイル読み込み
code_list = df["証券コード"] # CSVデータを各変数リストに代入
# ------------------------------ 休日・祝日、日付設定
holidays = [datetime.date(2022, 7, 18),datetime.date(2022, 8, 11),datetime.date(2022, 9, 19)] # こんな感じで祝日を指定
end = datetime.date.today() # 今日
day26 = workdays.workday(end, -25, holidays) # 26日前からのデータを取得したい場合、祝日を除いた今日から25日前の日付を指定
# ------------------------------ 関数:計算処理
def calc():
for j in range(len(dt[i])): # 取得したデータの index を j に代入して終了までループ
# 何か計算処理したい場合はここで
# 項目を辞書にセット・書き出し
d = {"証券コード":code_list[i],"始値":dt[i]["Open"][j],"高値":dt[i]["High"][j],"安値":dt[i]["Low"][j],"終値":dt[i]["Close"][j],"出来高":dt[i]["Volume"][j]}
d_list.append(d)
print(d) # 画面印刷必要なければコメントアウトで若干処理が速くなる
# ------------------------------ 関数:データ取得
def code_items():
stock = "{}.T".format(code_list[i]) # 日本株銘柄コード yahoo(****.T) stooq(****.jp)米株"GOOG","NVDA"等
yf.pdr_override() # yfオーバーライド
dt[i] = pdr.get_data_yahoo(stock, day26) # データ取得 DataReader('銘柄コード','取得先','開始日','終了日')endなしの場合、最新日まで取得
# dt[i] = pdr.DataReader(stock,"yahoo",day26) # 以前のデータ取得、pdr.DataReaderからget_data_yahooへ変更 2021.7 pandas仕様変更
try:
calc() # 関数:計算処理
except:
print("err2",code_list[i])
# ------------------------------ メイン処理
dt_now = datetime.datetime.now(datetime.timezone(datetime.timedelta(hours=9),'JST')) # 開始日時
print(dt_now.strftime('開始 %Y年%m月%d日 %H:%M:%S'))
dt = {} # 銘柄毎のOHLCVデータ辞書 # 辞書{}・リスト[]を作成
d_list = [] # CSV書き出し用リスト
for i in range(len(code_list)): # 読み込んだコードリストの index を i に代入して終了までループ
try:
code_items() # 関数:データ取得(関数:計算処理)
except:
print("err1",code_list[i])
df = pd.DataFrame(d_list) # リストをデータフレームに代入
df.to_csv("データ取得.csv", index = False, encoding="utf-8-sig") # CSVファイル書き出し
dt_now = datetime.datetime.now(datetime.timezone(datetime.timedelta(hours=9),'JST')) # 終了日時
print(dt_now.strftime('終了 %Y年%m月%d日 %H:%M:%S'))
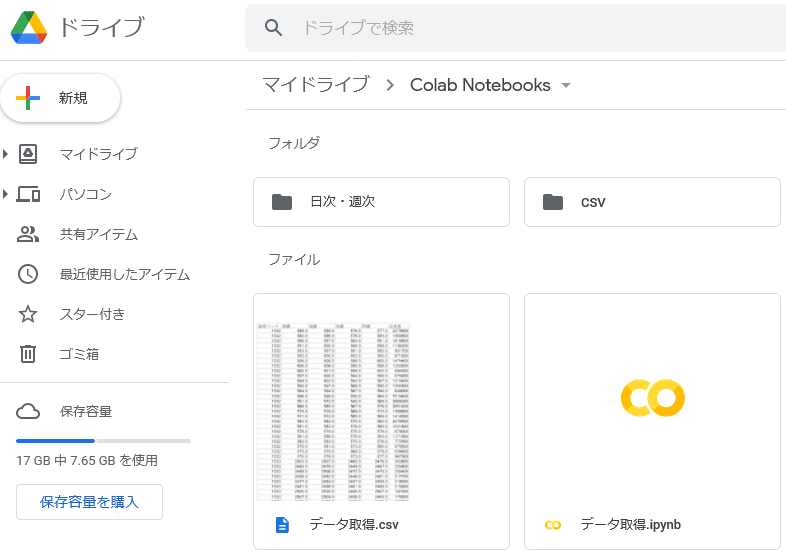

225銘柄毎26日分のOHLCと出来高が取得できています
23.12.12 yfinanceが何か更新されてデータが取得できないというのを見て、自分でも確認したので調べたらpipのアップデートすれば上手くいくというのを見つけたので、やってみたら上手くいきました
pip install yfinance --upgrade yfinance又は
pip install yfinance -Uいいなと思ったら応援しよう!
