
tensorflow keras基礎(自然言語処理 番外編Ⅲ)

tensorflow基礎の続きです。
(前回の投稿を書き始めた時点ではバチバチにkerasやりまっせ!っていうスタンスだったんですが、蓋を開ければ導入も導入で終わり散らかすという恥さらしの回でしたw
今回はちゃんとkerasから始まります。)
では、今回もよろしくお願いいたします。
・compileとfit
前回は最後にtrain関数を自作し、手動に近い形で学習を行なってきましたが、実際はそんなことはあまりしません。
実際にはfitメソッドで学習しますが、その前にcompileする必要があります。
==雑談==
コンパイルというと、自分が大学時代にC言語が授業であり、頻繁に聞いたのですが、プログラミングに触れたこともない当時、C言語が壊滅的にわからなかったので、「コンパイル」という用語を聞いただけでちょっとネガティヴな感情になりますw
======
そもそもコンパイルというのは、プログラミング言語を機械語(0と1で表現)に変換することを意味します。
コンパイルする言語をコンパイラ言語とか言いますが、ま、進めます
modelをfitやpredictをするために、.compileを用いてoptimizer(パラメータの更新方法)や損失関数、評価指標を設定しておく必要があるわけですね。
(語弊ある言い方をしますが、compileでtensorflowのモデルが、どうやって学習すれば良いかを宣言(翻訳)しておくって感じです。)
コードも簡潔です。
tf.random.set_seed(1)
model = MyModel()
model.compile(optimizer='sgd', loss=loss_fn, metrics=['mae', 'mse'])sgd: Gradient descent (勾配降下法)のことです。
mae, mse は評価指標です。
ここではそれぞれのロジックなどは一旦割愛して、進めます。
compileができるとfitメソッドを呼び出せるので、前回のtrainと同じ回数で訓練してみます。
num_epoch = 200
batch_size = 1
model.fit(X_train_norm, y_train, epochs=num_epoch, batch_size=batch_size, verbose=1)
ぶぁ〜っと出てくると思いますが、前回とほとんど変わらないです。
fitメソッドのコードをみて行きます。
fit(
x=None, y=None, batch_size=None, epochs=1, verbose='auto',
callbacks=None, validation_split=0.0, validation_data=None, shuffle=True,
class_weight=None, sample_weight=None, initial_epoch=0, steps_per_epoch=None,
validation_steps=None, validation_batch_size=None, validation_freq=1,
max_queue_size=10, workers=1, use_multiprocessing=False
)
部分的に説明します。
validation_~: 指定した数値(split)やデータ(data)により、検証用データとして分割や評価してくれます。
試しに、validation_dataでX_test, y_predを入れてみました。(このy_pred, modelにより生成されたものなので、実際こんなことしませんが、パラメータの確認という意味で今回使っています。)
model.fit(X_train_norm, y_train, epochs=num_epoch, batch_size=batch_size, verbose=1, validation_data=(X_test_norm, y_pred))
小さくてみにくいですが、検証ようデータとしての性能指標も追加されています。
その他は適宜使用するタイミンングで補足して行きます。
・ひと休み
ここまでがtensorflowの基礎やらお作法やらって感じです。
個人的にこれを書くのは2周目に細かく調べたりして書いてるのですが、それでもnumpyやpandasに比べて、まっったく馴染んでないぃ。。
理解はできているものの、実践を積めてなさすぎるので、使えるタイミングやこれからRNNやseq2seqでもtensorflow中心になるので、慣れてくるとは思っていますが、むむむって感じです(どうです??)
しかし、これからようやくkeras.layerに入るので、さらに深くなります。
では、再開します。
・kerasで多層パーセプトロンの構築
ここからkeras.layersでいわゆるNeural Networkを構築することを目指します。
(しかし、以前から先ほどまでのように逐一手動でする部分はあまりなかったりしますし、それが重宝されている部分でもあります。)
ここからはtensorflow-datasetsの中にあるIrisデータを使って、少しずつ理解を深めて行きます。
まずは準備。(ちなみに、tensorflow-datasets は pip install でできます)
import tensorflow_datasets as tfds
iris, iris_info = tfds.load('iris', with_info=True)
print(iris_info)
infoの詳細な中身を理解しておく必要はあまりないですが、train-dataとして150ssしかなかったり、特徴量は4つ、labelは3つあるんだな〜くらいで先に進みます。
・(脱線)単層NLと多層パーセプトロンをざっくりと
いつもながら脱線します。(Neural Netに関して理解している方はかったるい説明をしていると思うので、飛ばしましょう。)
ここではニューラルネットワークに関してはまだちゃんと触れていないので、単層Neural Networkとこれからする多層パーセプトロンのほんとに座っっくりとした外観くらいの説明をしておきます。
- パーセプトロン(とADALINE)
パーセプトロンをまず図でみると以下。

これが全体像です。
特に説明もいらないとは思いますが、要はこの一連が「パーセプトロン」と言われています。
この出力から正解の値との誤差を計算して重みやバイアスの更新がされています。
ADALINEはこれを改良したもの、ただそれだけです。
図で見て行きいます。

(上の図のj(w)に二乗するの忘れている。。)
ちょっとだけ補足すると、先程のパーセプトロンでは、単位ステップ関数を用いていたために1 or -1 が出力されるので、w, bでの微分ができなかったです。
(つまり、パーセプトロンは線形問題のみにとどまります。なぜなら、二値にしか分類しないので。。)
しかし、ADALINEにより、コスト関数(w* x + b - y)**2となるので、w, bで偏微分ができるようになり、学習率ηをかけたものを元のw, bに引いて更新ができるわけです。(お気づきの人もいるかもですが、これ、勾配降下法です)
- ニューラルネットワーク
では、ニューラルネットワークはパーセプトロンとどう違うのかと言われれば、活性化関数にstep関数以外を使っているものをニューラルネットワークといいます(これ、厳密な定義でない可能性もありますが、特に数学的流派に属しているわけではないので、個人にお任せします)
例えば、sigmoidやReLUとかです。
- 多層パーセプトロン
シンプルに言えば、先程のニューラルネットワークとかに隠れ層をいくつか追加したものが多層パーセプトロンです。
今回は理論を細かく扱わないので、簡単に図でみて行きます。

ちょっと見にくいかもですが、厳密性を気にせず理解するくらいならこれくらいでいいと思っています。
補足するのであれば、この後にも出てきますが、入力の次元(ユニット数)とバイアスのための1が必ず入力されるため、次元数は入力層、中間層で必ず+1されます
また、隠れ層において総和を入力とし、次の層へ入力される時にはそのまま吐き出されるのではなく、活性化関数などで変換されたりします。
・keras再開
では、再開して、irisのtrainデータやらテストデータを作って行きます。
しかし、先ほども書きましたが、今回irisには150ssのtrainデータしかないため、検証用のデータはこの中で作る必要があります。
そもそもdatasetsにsplitというパラメータがありますので、それを見てみましょう。
iris_train, iris_valid = tfds.load('iris', split='train[:75%]'), tfds.load('iris', split='train[75%:]')
print(len(iris_train))
print(len(iris_valid))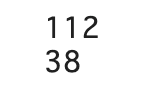
今回trainのみのため、スライスでtrainの上から75%を取得しています。
他にはtake slipメソッドがあるので、そちらもみて行きます。
ds_orig = iris['train']
ds_orig = ds_orig.shuffle(150, reshuffle_each_iteration=False)
ds_train_orig = ds_orig.take(100)
ds_test_orig = ds_orig.skip(100)shuffleのreshuffle_each_iterationを指定すると、それぞれのエポック(訓練データの訓練回数)によってシャッフルをするかどうかコントロールできます。(今回Falseにしているため、take時、skip時にシャッフルが行われないため、データの重複を防ぐことができます。)
公式チュートリアルの例を見ておきます。
dataset = tf.data.Dataset.range(3)
dataset = dataset.shuffle(3, reshuffle_each_iteration=True)
dataset = dataset.repeat(2)
# [1, 0, 2, 1, 2, 0]
dataset = tf.data.Dataset.range(3)
dataset = dataset.shuffle(3, reshuffle_each_iteration=False)
dataset = dataset.repeat(2)
# [1, 0, 2, 1, 0, 2]上はTrueにしているため、一度シャッフルされた後、repeat呼び出し時に生成されるデータもシャッフルされています。
下はFalseにすることで、repeat時にはshuffleされることなく繰り返されています(ご自身でも触ってみた方が理解しやすいかも)
今回、train, testのデータの中身はdict型であるため、訓練をする際にはtuppleに変換してアクセスできるようにする必要があります。
要素に対して変換する場合はmapメソッドで対応します。
ds_train_orig = ds_train_orig.map(lambda x: (x['features'], x['label']))
ds_test_orig = ds_test_orig.map(lambda x: (x['features'], x['label']))では、実際に層を積み上げて学習にいきます!
今回はkeras.Sequentialモデルを使うのですが、実はkerasには層の重ね方にいくつか種類があります。
いわゆる一直線(※)はSequentialの中にDenseなどを入れて行えます。
(そもそもSequentialが「一連の」という意味)
(※入力があり隠れ層でぶぁ〜〜って学習してもらい、出力を出して終わり!ってやつ)
その他にもSequentialでインスタンス化してから、.addメソッドで追加したりもありますし、ほんといろいろ。(これに関しては今後書く予定ではある)
このIrisに関しては、入力一つに対しての出力はラベルの予測ですので、シンプルな方法になります。
では、コードをみます。
iris_model = tf.keras.Sequential([
tf.keras.layers.Dense(16, activation='sigmoid', name='fc1', input_shape=(4, )),
tf.keras.layers.Dense(3, activation='softmax', name='fc2')
])
iris_model.summary()
Denseの説明の前に、出力されたsummaryのParamだけ確認しておきます。
この80とか、51ってなに?ってなりますが、先程の脱線の時に図で書いていたように、
{ (入力)4 + (bias)1 }* (中間層のユニット数)16 = 5 * 16 = 80
{ (入力)16 + (bias)1 }* (出力層のユニット数)3 = 17 * 3 = 51
で計算されています。
では、Denseをみて行きます。
tf.keras.layers.Dense(
units, activation=None, use_bias=True,
kernel_initializer='glorot_uniform',
bias_initializer='zeros', kernel_regularizer=None,
bias_regularizer=None, activity_regularizer=None, kernel_constraint=None,
bias_constraint=None, **kwargs
)
では、部分的にみて行きます。
units: まずは作りたい層のunit(先程の脱線の中にある丸の数)
activation: 活性化関数の指定
use_bias: 層がbiasベクトルを使うかどうか
~_initializer, regularizer: ~の初期化, 正則化を適用する関数
(その他割愛)
少ない記述ながらも、「どういう活性化関数を持っていて、ユニット数は〜です」ということが読み取れます。
注意点として、入力のinput_shape, 出力層のunits数はそれぞれ決まっています。(input_shapeは4, 出力層はlabel数が3である)
しかし、その他のunitsに関しては自由に決めることができます
(たぶん。というのも、調べた限りは法則やお決まりもなく、実際に自由に設定できますというサイトを見たりしたため。)
では、ニューラルネットワークが作れたので、compile fitをしてみます
iris_model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])num_epochs = 100
training_size = 100
batch_size = 2
steps_per_epoch = np.ceil(training_size / batch_size)
ds_train = ds_train_orig.shuffle(buffer_size=training_size)
ds_train = ds_train.repeat()
ds_train = ds_train.batch(batch_size=batch_size)
ds_train = ds_train.prefetch(buffer_size=1000)
history = iris_model.fit(ds_train, epochs=num_epochs, steps_per_epoch=steps_per_epoch, verbose=0)急に色々出てきましたが、一旦先に描画までしてしまいます。
hist = history.history
fig = plt.figure(figsize=(12, 5))
ax = fig.add_subplot(1, 2, 1)
ax.plot(hist['loss'], lw=3)
ax.set_title('Training loss', size=15)
ax.set_xlabel('Epoch', size=15)
ax.tick_params(axis='both', which='major', labelsize=15)
ax = fig.add_subplot(1, 2, 2)
ax.plot(hist['accuracy'], lw=3)
ax.set_title('Training accuracy', size=15)
ax.set_xlabel('Epoch', size=15)
ax.tick_params(axis='both', which='major', labelsize=15)
plt.tight_layout()
plt.show()
では、コードをみていきます。
まずは回数などを諸々設定しています。
====
個人的にsteps_per_epochが
なぜこうなっているのか?決まりでもあるのか?
気になったのですが、自分がサラッと調べた限りでは特に決まってないっぽいというのが結論でした。
デフォルトがデータ数 / バッチサイズらしいので、今回の設定になったのかなと。
====
そして、trainデータをシャッフルし、無限回に繰り返しバッチサイズ2つに取り出します。
で、prefetch。
そもそも「prefetch」というのは、CPUがデータをキャッシュメモリに読み込んでおいて、処理を早めるということです。
==以下、このprefetchの(正しくない)例え==
(私含めて、)いまいちこれだけではピンとこないよ!という方は、PCを料理に例えると少しわかりやすいかもです。
CPUとは処理能力なので、シェフ。
キャッシュメモリはまな板。(ストレージは冷蔵庫)
つまり、CPUがデータをキャッシュメモリに読み込むということは、あらかじめ作りたい料理に必要な食材をすべてまな板の上に並べることで、
その都度、冷蔵庫から食材を取り出すより作業効率は上がるよね!って感じ。
(反対に、手の込んだ料理の時はまな板に一斉に食材を置いても、逆に効率が下がる時もある)
厳密性を無視した例え、終わり。
========
.prefetchをしても要素の中身は変わりませんが、型?が変わります
(BatchDataset -> PrefetchDatasetになっている)
(この.prefetchですが、いつ使うべきなのかというポイントが現時点ではわからなかったので、また出てきたときにみてみます。)
で、historyという変数にfitで学習した処理結果を格納しています。
このhistoryはdict型で、.keys()で確認してみますと、以下。
hist.keys()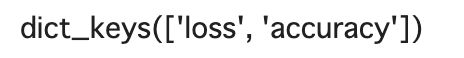
なので、グラフプロットではdict型のアクセスが可能となります。
とくにplotの関数に関しては特筆することもないので、結果はグラフの参照にとどめます。(個人的に描画のライブラリを学びたいので、なんかあれば書きます。)
・テストデータで評価
では、テストデータで評価してみます。
results = iris_model.evaluate(ds_test_orig.batch(50), verbose=0)
print(f'Test loss {results[0]}, Acc {results[1]}')![]()
evaluate関数だけ見ておきます。
evaluate(
x=None, y=None, batch_size=None, verbose=1, sample_weight=None, steps=None,
callbacks=None, max_queue_size=10, workers=1, use_multiprocessing=False,
return_dict=False, **kwargs
)
特筆すべきパラメータがない(チュートリアルにも特にいい例がなく。。)ので、参照にとどめますが、普通に評価しているものです。
・モデルの保存
モデル保存は.save関数でできます。
iris_model.save('iris-classifier.h5', overwrite=True, include_optimizer=True, save_format='h5')tf.keras.models.save_model(
model, filepath, overwrite=True, include_optimizer=True, save_format=None,
signatures=None, options=None, save_traces=True
)
overwrite: 既にあるモデルの上書きをするかどうか
include_optimizer: 最適化の状態も保存するかどうか
save_format: 'tf' or 'h5'で指定。
このh5(HDF5)って何ですか?ってなったのですが、modelのconfig(何らかの設定)とか、重み、optimizerを保存する形式だそうです。
pickleのような軽さほどはないにせよ、比較的軽く階層の高いTensorが扱えるなど、tensorflowを扱う上ではこれからでてきそう。。
(その他のパラメータは一旦割愛。)
ちなみに、この保存したmodelは .load_modelで読み込めます。
・一旦終わり
ほんとは活性化関数のそれぞれを解説する予定でしたが、この辺でtensorflowの基礎の基礎くらいはサラっといけたので、次回から自然言語処理に戻ってみます。
tensorflowは終わりなき道なので、適宜検索は怠らずに進めて行きます
・(不定期更新な)おまけ
ここでは、本格的に扱わないけど、python やデータサイエンス、その他純粋教養で知識の復習・深化を(自分が)できるように不定期で何かしら扱います。
今回はiteratorについて。
generator とかiteratorとかってなんか聞いたし出てきたことあるけど、なんかテキストのコード書いてるだけで終わっているって方もいると思います。(私です。)
では、少しばかり始めます。
iterator の前にiterableというものを扱います。
iterableとは、ここでもよく出てくるイテレーション(反復)のことで、反復処理ができるかどうか?を意味します。
代表的なものはfor 文で馴染みあるかと思います。
逆にfor 文が使えないものはそれはiterableではないということです
本当に簡単な例を二つほど。
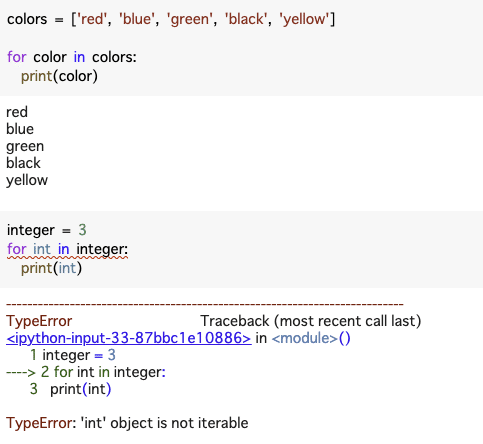
まずはlist形式はお馴染みのようにfor文が使えるわけで、iterable.
しかし、もちろん数値はfor文で使えませんので、not iterable
となりますね。
(ちなみに、intはダメですが、stringはfor文使えます。)
これをちゃんと書くと、iter()関数でiteratorを返すオブジェクトをiterableと言います。
実際にさっきの例をもう一度。

では、iteratorとはちゃんと言えばnext()関数でiterationできるオブジェクトです。
・・・??
まずコードを見てみます。

つまり、iterableをnext関数で順に要素を取り出せることができています。
実はfor文の元はこれです。
もう少し別の例として簡単にnp.arangeで見てみましょう


next関数で順番に取り出せました
まぁ、これだけっちゃこれだけ。
(iterator自体もiterableであります。試しにiter_rをiter関数に入れてもiteratorがでてきます)
以前、iterとnext関数を実際にtensorflowで出てきたことを覚えておりますでしょうか。
おさらいしておきます。

このように、iter関数を定義し、順にnextを取ると、batch_size=3(つまりsize=3のデータセット)がとりだされ、4回目(for文の中)のiter_tensorには0~8まで要素が抜き出された残りの9が出てくるわけです。
具体例ではわかりやすいのですが、場合によってはiteratorを返すような関数もあったりします。。