
自然言語処理④~単語の定量化・Word2Vecなど~

前回の内容というか、MeCab とか使う予定なので、必要な時は上記を参照したり、他のバチバチにわかりやすいサイトなどを参照してくださいませ。
今回はやや理論よりですが、高度な数式などは(あまり)でないと思います・
また、自然言語処理のすこし深くに入っていきますので、頑張っていきましょう。
では、よろしくお願いします
・文章の定量化〜one-hot表現〜
前回までは形態素解析で主に単語を分割していくことの処理を学びました。
しかし、実際にコンピュータが機械学習や計算を行うためには単語のままでは処理できないため、ベクトルを用いて数値的に変換し定量的に扱っていく必要があります。
このベクトル的に文章を扱っていくことで単語同士の結びつきや感情、文章要約に繋げていくことができます。
そして、まずはone-hot表現から見ていきます。
機械学習を学んでいる方はOne-Hotエンコーディングで聴き馴染みあるかと思いますが、基本的に同じものです。
ある単語をベクトルで0, 1で表現していきます。
具体例をみていきましょう。

図でほとんど説明しているかと思いますが、簡単に補足を。
まずは形態素解析で必要な単語を取り出したのち、それぞれにラベルを降ります(同じ単語は同じラベル)
それを元にして順番にベクトルで表現したものがone-hot表現です。
・共起行列
このone-hot表現のように定量的に表現しつつ、共起行列というものを理解していきます。
これは単語の意味がその前後や周辺の単語により意味づけができるのではないか?という仮説のもと使われるものです。
共起とあるのですが、単語の前後に当たる単語を数えて行列で表現したものを共起行列と言います。
図で見ていきます。

例えば、「私」という単語は一番初めのため前にはなにもありませんが、後には「浅草駅」があるため、「浅草駅」に個数の「1」をカウントし、残りの単語には0を格納します。
次に、「浅草駅」には前後で「私」と「行く」が共起しているため、それぞれに「1」を格納し、残りを0とします。
これらを全ての種類の単語で適用し、行列で表現します。(行列は対称行列)
しかし、この行列をそのまま使うことはほとんどなく、理由としては
・高頻度に出てくる単語に共起しやすい(「〜する」とか「〜なので」など)
・単語の数だけ次元が増える(計算コストがいかちぃ)
などの観点からそのまま使うにはちょっと、、、ってなります。
これらに対応するために、相互情報量(次に解説します)であったり、次元圧縮(主成分分析など)によってどうにかこうにかしていくアプローチが撮られます。
・相互情報量(PMI)
厳密性を無視して、簡潔に言えば相互の単語に関する相互依存の尺度を表したものをPMIと言います。
いわゆるどのくらい単語が独立から離れちゃっているのか?って感じです。
実際には情報理論でやや複雑な前提があるので、簡素的なものにとどめます
これだけではピンとこないので、数式を先に提示します。
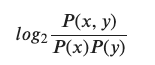
P(x, y)はx、yが同時に生起する確率
P(x)はxが生起する確率(yも同様)
つまり、x, yという単語が高頻度に出てくれば全体として小さい値となるため、それは重要ではない(可能性がある)と言えるよね、という指標となります。
ちなみに、
P(x) = C(x) / N(C(x): xが出てくる個数、N: 全体の文章の単語数)
として、数値ベースで調整することもあります。
反対に片方が大きい場合も全体として小さくなるため、共起行列で大量の個数カウントがなされてたとしても、「いや、実は重要ではないんじゃね?」となるわけです。
「相互情報量を理論的に考慮しなければならない」状態はあまりないと思っているので、いまいちピンとこなくても今は大丈夫です!
・共起行列とPMIをコードで見てみる
実際に共起行列とPMIをpythonで実装してみます。
実装しますが、あまり本質的な実装でもないので、サラリといきます。
word2Vecとかの実践を重視される方は、流し見程度でも問題ありませんし、そのままコピペで使っても大丈夫です。
- 下準備の関数
def text_to_words(text, stop_word_pass='./Japanese.txt'):
"""
to make the stopword list
parameter:
text: text data
stop_word_pass: path that exists stopwords list
"""
stopword_list = []
with open(stop_word_pass, 'r') as f:
stopword_list = f.readlines()
stopword_list = [x.strip() for x in stopword_list if x.strip()]
# 形態素解析を始める
path = "-d /usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd"
m = MeCab.Tagger(path)
# m = MeCab.Tagger('-d /usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd')
m.parse('')
# text = normalize_text(text)
text = mojimoji.zen_to_han(text, kana=False)
m_text = m.parse(text)
basic_words = []
# mecabの出力結果を単語ごとにリスト化
m_text = m_text.split('\n')
for row in m_text:
# Tab区切りで形態素解析、単語部のみ取得
word = row.split('\t')[0]
# 最終業はEOS
if word == 'EOS':
break
else:
pos = row.split('\t')[1]
slice_ = pos.split(',')
# 品詞の取得
parts = slice_[0]
if parts == '記号':
continue
# 活用語の場合は活用指定のない原型を取得
elif slice_[0] in ('形容詞', '動詞') and slice_[-3] not in stopword_list:
basic_words.append(slice_[-3])
elif slice_[0] == '名詞' and word not in stopword_list:
basic_words.append(word)
basic_words = ' '.join(basic_words)
return basic_words長いコードを書いてますが、内容は意外とシンプルです。
特に詳細には説明しませんが、簡単にいうと、文章の名詞・形容詞・動詞を抜き取るものです(stopwordの名詞などは除いて)
- 共起行列
def co_matrix(corpus, sep=' ', window_size=1):
"""
to make the co-matrix
parameter
corpus
sep: str
you can decide what you want to separate by str
window_size: int
you can check before and after the window_size number of words
"""
word_to_id = {}
id_to_word = {}
cnt = 0
# Word にidをフル
for co in corpus:
for c in co.split(sep):
if c not in word_to_id:
word_to_id[c] = cnt
id_to_word[cnt] = c
cnt += 1
vocab_size = len(word_to_id)
# 正方行列作成のため枠組みを作成
co_matrix = np.zeros((vocab_size, vocab_size))
for co in corpus:
corpus_words = co.split(sep)
# count the len of corpus
corpus_size = len(corpus_words)
for idx, c in enumerate(corpus_words):
# get the id of word
center_index = word_to_id[c]
# search between -window_size and +window_size
for diff in range(1, window_size + 1):
# count the before words
if idx - diff >= 0:
left_word = corpus_words[idx - diff]
left_index = word_to_id[left_word]
co_matrix[center_index, left_index] += 1
# count the after words
if idx + diff < corpus_size:
right_word = corpus_words[idx + diff]
right_index = word_to_id[right_word]
co_matrix[center_index, right_index] += 1
return word_to_id, id_to_word, co_matrixこちらも特別難しい関数などはないかと思いますので、説明は省略します。
出力結果は以下のような感じになります。

- PMI
def ppmi(C, delta=1e-8):
"""
C: co-matrix
delta: to avoid the zero increments in log
"""
M = np.zeros_like(C, dtype=np.float32)
N = np.sum(C)
# count each words
S = np.sum(C, axis=0)
for i in range(C.shape[0]):
for j in range(C.shape[1]):
pmi = np.log2(C[i, j] * N / S[i]*S[j] + delta)
M[i, j] = max(0, pmi)
return M今回のPPMIはPMIがマイナスを取る(log2であるため、負の数をとる場合もある)ときは0にして補正している関数です。
このような関数を毎度実装しなければいけないことも現代ではほぼないので、ふ〜んくらいでいきましょうw
・Word2Vecを使う。
では今回の一つの山場に。
名前の通り、word to vector なので単語のベクトル表現を得る方法です。
one-hotでは大量に次元数が生まれてしまう問題を分散表現であわらしていくことで次元数をこちら側で制限ができるようになりました。
簡易的なニューラルネットワークであるものの、発想としては人間の記憶(関連のある単語同士を結びつけるなど)にが基になっているのがword2vec です!
Word2Vecには主に2つの手法があります。(CBOW, skip-gram)
どちらもわかりやすい他サイトがたくさんありますが、簡潔に書いていきます。
1. CBOW(Continuous Bag-of-Words Model)
周辺の単語からその間にある単語を予測するモデル。
図を見ながら説明していきます。

少し文字が小さい。。
まず「パン」という用語がマスキングされた時に前後の単語を入力データをもとに予測するのがCBOWです。
今回、入力で同じような状況で「パン」という用語が関係していたので、出力も「パン」ではないか?と予測されたわけです。
実際にはニューラルネットワークがあるため、先程の図をベクトル表現も加筆すると、
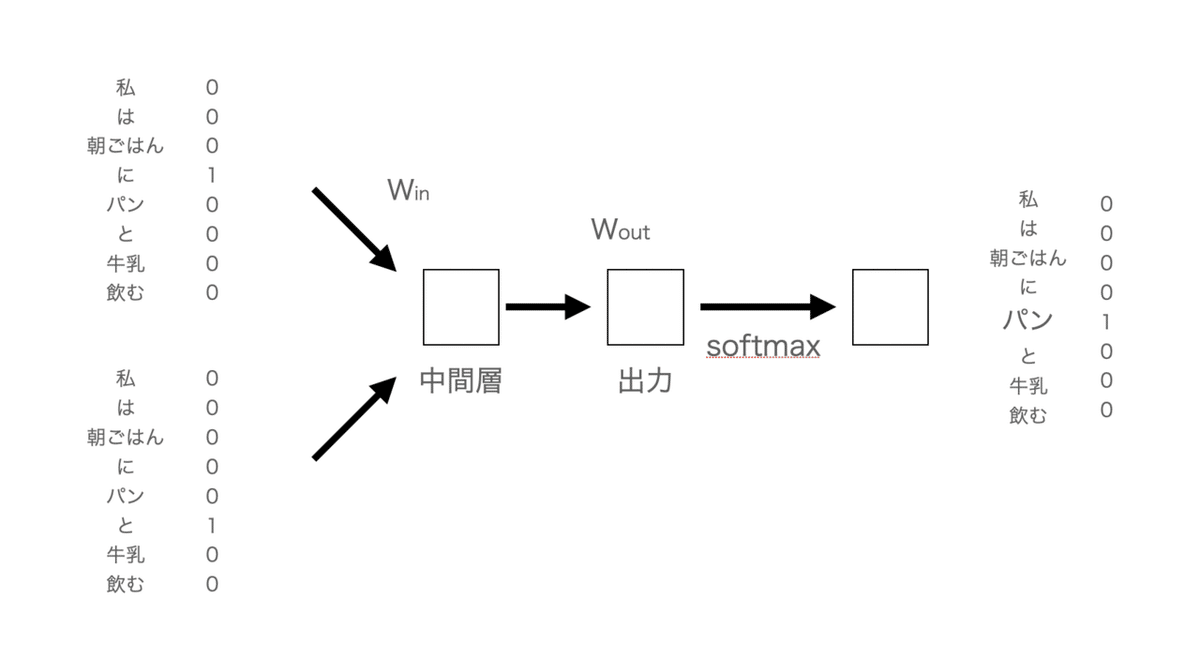
実際はバックプロばゲーション(重みの調整とかもろもろ)があったりするのですが、外観は上記のようになります。
2. skip-gram(Continuous Skip-Gram Model)
CBOWが中間を埋めることに対して、skip-gramはその反対というイメージで大丈夫です。
つまり、中間からその両端を予測するのがskip-gramになります。
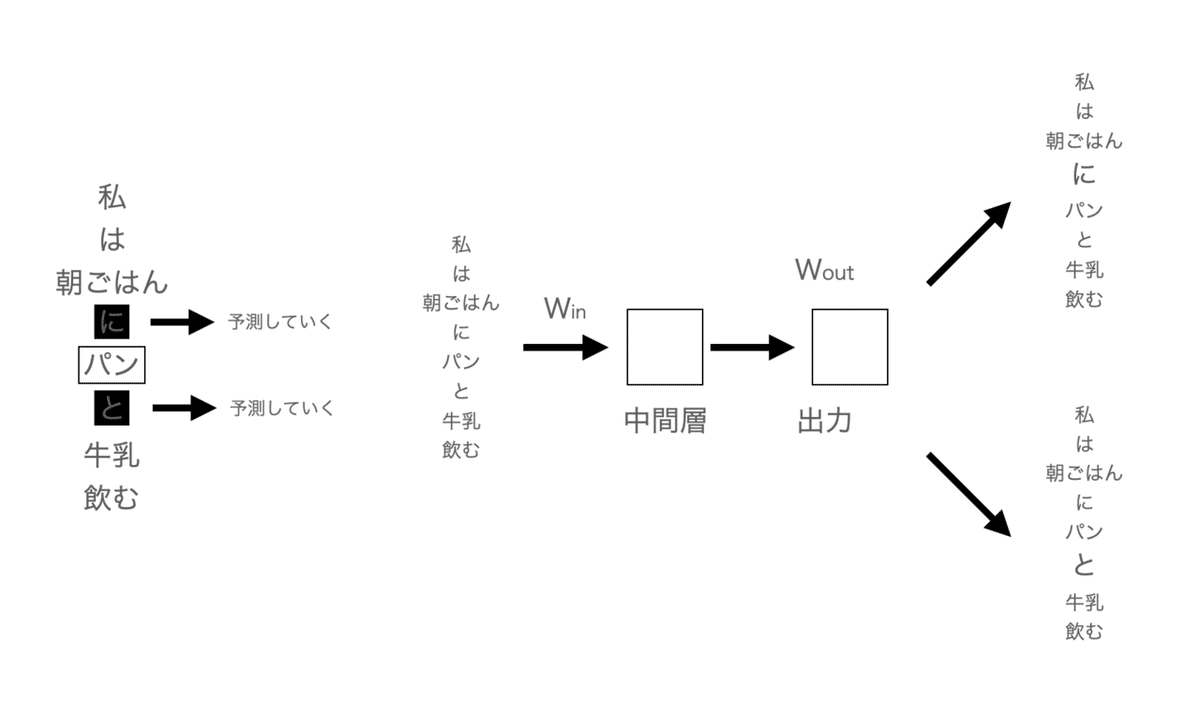
CBOWとよ同じく実際はニューラルネットワークなので、ベクトルで出力されますが、同じなので割愛します。
word2vecではデフォルトはskip-gramが指定されていますが、計算量としてはCBOWの方が速度的に速いですが、精度としてはskip-gramの方が高いです(一般論)。
また、単語の類似度の評価はコサイン類似度が採用されています。
・コサイン類似度
初めましての方もいると思うので、簡単にコサイン類似度について補足します。
単語がベクトルで表現できるということは単語同士の内積を図ることができ、この内積を用いるとなす角θを求めることができます。
このθが小さければ小さいほど単語同士は似ていると言われています。

・Word2Vecに触れてみよう!
では、簡単に実装していきましょう。
gensimというライブラリの中にあるのですが、網羅的に説明しようとすると自分の頭が追いつかないので、ほどほどに。。
とりあえず何か扱うデータが必要になりますが、せっかくなのでスクレイピングでもして取得してきましょうかしら、なんて思ったので取得してみます(流石にスクレイピングのコード説明をしちゃうとなっがくなるので割愛させてください。。。)
いちおう複雑な構造のニュースサイトから取るのも面倒ですし、気楽にyahooニュースサイトから。。
では、データの準備は私が担当することにしますため、みなさんはとりあえずコピペでおけです。
変に時間を使わない方がいいですw
import requests
from bs4 import BeautifulSoup
url = 'https://news.yahoo.co.jp/articles/e26d81ca6a4bb0097f55c0c9add67dd216488bf5'
response = requests.get(url)
response.status_code
>>>200soup = BeautifulSoup(response.content, 'html.parser')
class_body = 'div.article_body p'
contents = soup.select(class_body)import re
raw_corpus = [co.text for co in contents]
re_corpus = []
for co in raw_corpus:
co = re.sub('(\/\**)|(.*\*)|(.*;})', '', co)
re_corpus.append(co.strip())
re_corpussplit_co = []
for re_co in re_corpus:
re_coes = re_co.split('\n\u3000')
for re_co in re_coes:
# re_co = re_co.replace('\n', '')
if len(re_co) > 2:
split_co.append(re_co.replace('\n', ''))
split_co
import pandas as pd
df = pd.DataFrame(split_co, columns=['text'])
df
全部で21行分のコーパスを取得しました!
さて、こちらを今から形態素解析した上で、Word2Vecに処理してもらいます。
まずは、先ほど準備した'text_to_words'をこのdfに適用し、list形式に変換します。
df['text'] = df['text'].apply(text_to_words)
_corpus_yahoo = df_input['text'].values.tolist()ちなみに、この'text_to_words'はmecabを使っているので、セットアップが難しい場合はjanomeでもcabochaでも十分できます。
ちなみにたくさんのデータを使ってみたい方は、日本の国会のデータがオープンソースであったりします。
一応こちらで作成したデータも添付していますので、練習がてら使いたい方はどうぞ(30MBあるのでご注意を。。)
では、準備がひとしきりできたので、word2vecをインポートして使ってみます。
from gensim.models import Word2Vec
model_ = Word2Vec(corpus_yahoo, size=200, min_count=3, window=5, sg=1)word2vecの公式ドキュメントにはなんかそれらしい説明がなかったので、help関数でみてみました。。
主要(っぽい)ものだけ説明します。
Word2Vec(sentences=None, corpus_file=None, size=100, alpha=0.025, window=5, min_count=5, max_vocab_size=None, sample=0.001, seed=1, workers=3, min_alpha=0.0001, sg=0, hs=0, negative=5, ns_exponent=0.75, cbow_mean=1, hashfxn=<built-in function hash>, iter=5, null_word=0, trim_rule=None, sorted_vocab=1, batch_words=10000, compute_loss=False, callbacks=(), max_final_vocab=None)
sentences: コーパスを格納
window: 参照する前後の単語数を確認
min_count: 最低n個以上ない単語は無視する
sg: 1のときCBOWで学習
他にもたくさんあるのですが、いまいち使い所を学習できてないので、新しく使う時がきたら、都度調べようと思います。
どのようなことができるのかを次に見ていきましょう。
# 次元の確認
model_.wv['段差'].shape
>>> (200,)# 関連するwordのtop10を出力
model.wv.most_similar(positive=['警察'], topn=10)
# 関連する用語から指定した単語を擬似的に引き算したときのtop10の関連ワード
model.wv.most_similar(positive=['警察'], negative=['消防'], topn=10)
単語の引き算というのはなんかよくわかんないって方もいらっしゃると思いますが、
代表的な例を言えば、王様 - 男性 + 女性 = 女王
みたいなイメージをふわっと持っておくくらいで十分です。
# 単語がどのくらい似ているのかを数値的に算出
model.wv.similarity('警察', '消防')
これらの数値は基本的にはコサイン類似度であるそうです。
高いほどより似ている(つまりθが0に近い)と言えます。
このmodel.wvにはいろんなメソッドがあるのですが、
most_similar(self, positive=None, negative=None, topn=10, restrict_vocab=None, indexer=None)
similarity(self, cl1, cl2)
とかを筆頭に、そのほかは都度調べながら使う感じかと思います。
何かしら単語のラベルなどでリコメンデーションをしたい時などは結構友好的に使えるのかな?と思ったり。。
・100本ノック第3章
では、今回は第3章を
個人的に正規表現がむずいというより、最初のJSONファイルの読み取りをDataFrameに格納してしまい、全くうまくいかなかったです。。(ちゃんと読み込めてないので、設問文が意味不明になった)
なので、読み込んだ後でもう一度練習しました。。。(つらい)
正規表現は先程のスクレイピングでも少し使ったのですが、自然言語処理以外でもまぁ避けて通れない分野だとは思います。
しかし、正規表現を丸暗記なんていう神仕様の脳を持ってる人は少ないので、正規表現を覚えるというより「感覚を掴む」のとpython のre ライブラリで何ができるか?くらいをさらりと学ぶくらいでいいと思います。
100本ノックの問題自体は「正しい正規表現を設定してそれを適用」の繰り返しだったのですが、正規表現は記号だらけになるので、一つの設問だけpickupして「どういうことを指定しているのか」を解説します。
では、いきましょう。(解答にあたり、以下のURLのコードを使用させていただいております。)
27. 内部リンクの除去
26の処理に加えて,テンプレートの値からMediaWikiの内部リンクマークアップを除去し,テキストに変換せよ.
def remove_markup(text):
# 強調マークアップの除去
pattern = r'\'{2,5}'
text = re.sub(pattern, '', text)
# 内部リンクマークアップの除去
pattern = r'\[\[(?:[^|]*?\|)??([^|]*?)\]\]'
text = re.sub(pattern, r'\1', text)
return text
result_rm = {k: remove_markup(v) for k, v in result.items()}
for k, v in result_rm.items():
print(k + ': ' + v)まずは「r'\'{2,5}'」ですが、「\」単体で扱う時、その次の文字(今回なら「'」)を文字として扱いますよ〜ということを宣言しています。
たとえば、「*」というのは正規表現上「直前の文字の0回以上の繰り返し」という表現ですが、記号として「*」を判定したい時に「\*」とすることで、
今回の「*」は正規表現じゃないよ!記号の「*」だよ!
という宣言をしています。
次の「{2,5}」ですが、これは直前の文字を2回以上5回以下繰り返している(ものにマッチする)ものを検索します。
今回、強調のマークアップが「''文字''」のように「'」が2~5回用いられていますので、「r'\'{2,5}'」を指定することで、「『'』が2~5回あればみつけて!」ということを指示しています。
次に。
pattern = r'\[\[(?:[^|]*?\|)??([^|]*?)\]\]'
こういうのをみると、文字化けかなんかかね?って思いたくなりますが、ちゃんと見れば正規表現なんですよね。(つら。。)
一個ずつ見ていきましょう。
まず「 \[\[ 」に関してはさきほど解説したように「[」を記号の「[」として認識するようにエスケープしています。
次に「 (?:[^|]*?\|) 」。
「記号?」で直前の記号が0回もしくは1回マッチするときに検出します。
「:」は記号の「:」
「[^|]」は[正規表現]でorの表現に近いです。たとえば、[ab]とすると、a or bという記号を検出してください、という意味になります。
今回なら[]の中に「^|」が入っているので、先頭に「|」の文字があるかどうかを検出してくださいとなります
「*?」にかんしては、非貪欲というもので、例えば、'<a>b<c>'という文字列があり、'<a>'だけを検出したいとします。
正規表現で「'<.*>'」ように定義した場合は、一見正しそうですが、結果は'<a>b<c>'全てが返ってきます
これは貪欲と言われるもので、なるべくながく検出するというのが正規表現のスタンスであり、
「いやいや、適している中で一番小さい範囲だけでいいのよ」って時に「*?」(??や+?などもある)を使うこと(<.*?>)で、'<a>' だけを検出できるようになります。
今回なら[^|]*?とあるので、先頭に|があるなかでそれを最小(非貪欲)にとってきた状態で返してね、となります。
「\|」は「|」を記号として扱ってね、ということ。
ラスト。ここまでくればようやく。。
??([^|]*?)\]\]
??は先程の非貪欲と同じ
([^|]*?) は既出
\]\] も同じ
------------------
これを踏まえて、再度 r'\[\[(?:[^|]*?\|)??([^|]*?)\]\]' を見てみるとさっきよりかは抵抗がなくなったかもしれません。
言葉で表せば、
\[\[ →「[[ 」
(?:[^|]*?\|)?? →「文字(なくてもいい):|(「|」はなくてもいい )|」を非貪欲にくりかえされたもの
([^|]*?) →「|」が非貪欲にくりかえされたもの
「]]」
となります。
まぁ、伝わっているかはさておき、こんな感じです。
ここまで複雑なものをさらさらとかければまぁ困らないと思いますが、むずいですよね。。(ちなみに自分は毎回検索してます。)
・終わり
今回は文章の定量表現からword2vecまでを解説しました。
次回はDoc2Vecにしようかなとは思っていますが、他の形態素解析のライブラリginza sPacyによる固有表現抽出とかにしようか、あと個人都合でNLも勉強し始めないといけないので、そちらにしようかな、と。。
ま、Doc2Vec 、、かな、、