
Sapiens で完璧なキャラクター修復と背景置き換えを実現

Facebook AI Research の Sapiens ビジュアル トランスフォーマー モデルを使用してビジュアル コンテンツを強化および変換する方法を学びます。このステップ バイ ステップのチュートリアルでは、モデルのインストール、ワークフローの設定、高品質な結果を簡単に生成する方法について説明します。

導入
Sapiens ビジュアル トランスフォーマー モデルを利用してビジュアル コンテンツを強化および変換する包括的なチュートリアルへようこそ。Facebook AI Research によって開発された Sapiens は、コンピューター ビジョン テクノロジーの最先端にあり、高度なトランスフォーマー アーキテクチャを活用して、画像分類、オブジェクト検出、セグメンテーションなどのタスクで優れた性能を発揮します。コンピューター ビジョン分野の研究者、開発者、または愛好家であれば、このワークフローは Sapiens のパワーを効果的に活用するために必要なツールと洞察を提供します。
サピエンスモデルの概要
Sapiens は、Facebook AI Research が開発したビジュアル トランスフォーマー モデルです。コンピューター ビジョンのタスク向けに設計されており、トランスフォーマー アーキテクチャを活用して、視覚データをより効率的に処理および理解します。
Sapiens には、視覚理解の分野で強力なツールとなるいくつかの重要な機能があります。まず、画像の解釈に優れており、画像分類、オブジェクト検出、セグメンテーションなどのさまざまな領域に適用できます。(例: 2D ポーズ、パーツ セグメンテーション、深度、法線など)。トランスフォーマー ベースのアーキテクチャを利用することで、Sapiens は視覚データの長距離依存関係を効果的に管理し、従来の畳み込みニューラル ネットワーク (CNN) よりも優れたパフォーマンスを発揮します。

このモデルのスケーラビリティにより、より大きなデータセットを処理し、特定のタスクやアプリケーションに合わせて微調整することができます。さらに、Sapiens には事前トレーニング済みの重みが装備されているため、ユーザーは最初から大規模なトレーニングを行うことなくプロジェクトを開始できます。最終的に、Sapiens は視覚的理解の限界を押し広げ、コンピューター ビジョンの研究者や開発者にとって貴重なリソースとなることを目指しています。

サピエンスによるビジュアルコンテンツの変換ガイド
次のワークフロー ガイドでは、必要なモデルとチェックポイントをインストールする場所から始めて、プロセス全体を順を追って説明します。次に、ワークフローを段階的に設定する方法を説明し、各フェーズを明確に理解できるようにします。最後に、最終的な出力を紹介し、この設定で達成できる素晴らしい結果を示します。
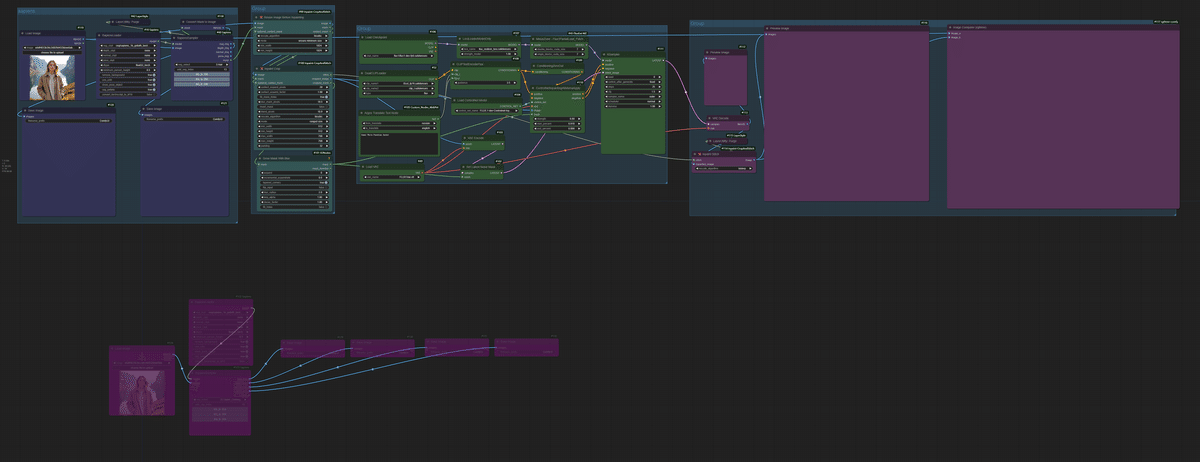
このワークフローを今すぐ実行する
すべてのノードとモデルの準備が整いました。
手動設定は必要ありません。
エラーなし - クリックして実行するだけ!
ステップ1: モデルとノードのインストール
このワークフローでは、上記の Sapiens モデルを使用します。このモデルは Hugging Face からダウンロードできます。パフォーマンスとコスト効率のバランスが取れているため、下の画像で強調表示されている 1b モデルを使用することをお勧めします。1b モデルを搭載した MimicPC でこのワークフローを実行すると、ハードウェア仕様が低くても印象的な結果が得られます。

各モデルの機能:
sapiens-pretrain-1b : 事前トレーニング済みの 1B モデルは、特徴抽出、微調整、または新しいモデルのトレーニングの開始点として使用できます。
sapiens-pose-1b : Pose 1B モデルは、1 つの画像で308 個のキーポイント(体 + 顔 + 手 + 足)を推定するために使用できます。
sapiens-seg-1b : Seg 1B モデルは、人間の画像に対して 28 クラスの身体部位セグメンテーションを実行するために使用できます。
sapiens-depth-1b : 深度 1B モデルは、人間の画像の相対的な深度を推定するために使用できます。
sapiens-normal-1b : Normal 1B モデルは、人間の画像の表面法線(XYZ)を推定するために使用できます。
これらのモデルは次のリンクからダウンロードできます: https://huggingface.co/facebook/sapiens。
ダウンロード後、ファイルを次のディレクトリに保存してください: Storage > models > sapiens > depth。

ステップ2: ワークフローの設定
まず、補正したいポートレート/キャラクター画像を準備します。たとえば、特定の服装や髪型のスタイルに満足していない画像を選択します。アップロードが完了したら、 SapiensLoader セクションで、パーツ分割用にダウンロードした「 sapiens-seg-1b」モデルを選択します。

次に、SapiensSample セクションで、キャラクターの体の特定の部分または背景を、置き換えたり変更したりしたい部分として選択します。このsapiens-seg-1bモデルを使用すると、髪型、服装、その他の特徴的な体の部分など、キャラクターの体のさまざまな特徴を正確にターゲットにして選択することができます。このモデルはきめ細かな制御が可能で、下の画像に示すように、個々の要素を調整できます。
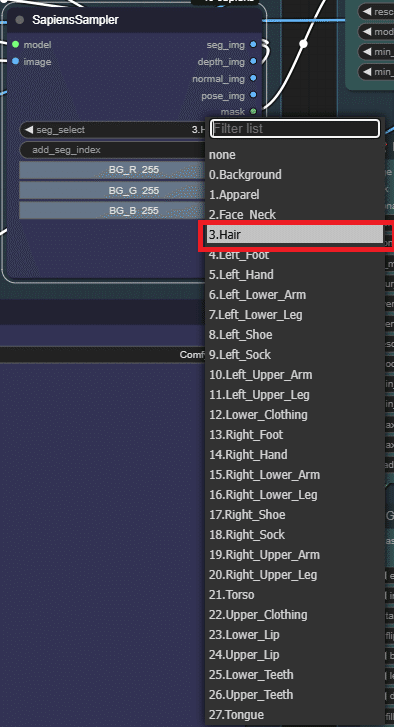
このセクションでは、マスクされた画像を生成し、インパンする前にパラメータを調整して画像のサイズを変更することに焦点を当てます。考慮すべきパラメータは多数あり、画像や目的の結果によって異なる可能性があるため、このワークフロー テンプレートで提供されているデフォルト設定を使用することをお勧めします。これらのデフォルト設定は、シンプルさと効果を確保するために慎重に選択されており、複雑な調整を必要とせずに最高の結果を得ることができます。

CLIPTextEnodeガイダンスの値は3.5 に設定されています。値が高いほど、モデルはテキスト入力に基づいてより複雑または具体的な詳細を生成するようになり、プロンプトとより密接に一致する出力が生成されます。最後に、プロンプト セクションに対応するスタイルを入力します。たとえば、ジャケット スタイルを変換する場合は、「キャメル ホワイト パンチング ジャケット」と入力します。ヘアスタイルを変更する場合は、「自然なウェーブの黒のテクスチャのある乱れた髪」と入力します。

このワークフローを使用する唯一の目的が、キャラクターのスタイルや背景の特定の部分を変更することである場合は、エラーのリスクを最小限に抑えるために、このワークフローのデフォルトのパラメータと値を使用することをお勧めします。
ステップ3:最終結果の発表
髪型を変える
プロンプト: 黒髪

この比較では、元の画像 (左) では、ゆるやかなウェーブのある明るいブロンドの髪のキャラクターが示されていますが、変換された画像 (右) では、ボリュームが加わり色が濃くなった、新しい質感のあるヘアスタイルが強調されています。
上着の着替え
プロンプト: ピンクのドレス

Sapiens モデルを適用した後の出力画像では、花柄のピンクのドレスを着た彼女が表示され、質感と色が追加され、無地の白いドレスに比べて、より鮮やかでロマンチックな雰囲気が生まれます。
背景を変更
プロンプト: 床から天井まで届く窓と温かみのある木製家具を備えた、太陽の光が差し込む居心地の良いカフェ。緑の植物と小さな花瓶が魅力を添え、柔らかな音楽と淹れたてのコーヒーの香りが空気を満たします。

その結果、キャラクターのアイデンティティを損なうことなく背景を強調するシームレスでリアルな変換が実現し、部分的な再描画におけるサピエンスの精度が示されました。
結論
このチュートリアルでは、Sapiens ビジュアル トランスフォーマー モデルの機能と、プロジェクトで効果的に実装する方法について説明しました。必要なチェックポイントのダウンロードからワークフローの設定まで、シームレスなエクスペリエンスを実現するための各ステップについて説明しました。強力な機能とユーザー フレンドリーな設定を備えた Sapiens は、ビジュアル コンテンツを向上させたいと考えている人にとって貴重な資産です。さまざまな機能を試して、創造性を発揮することをお勧めします。