Stability Matrix から kohya_ss(Kohya's GUI)をインストールしてLoRAを自作する

表題の通りです。
kohya_ss(Kohya's GUI)に関しては以前LoRA作成記事をいくつか書いてきたんですが、現状では内容が古くなってしまい、うまく設定できなかったりするんじゃないかと思いました。
Kohya_ss というのは Kohya Teck さんが公開なさっている、Stable Diffusionの学習、画像生成スクリプトです。
そして、それをWebUI形式のブラウザから簡単に操作できるようにしたのが、bmaltais さんが公開している Kohya's GUI です。
https://github.com/bmaltais/kohya_ss
少し前のアップデートから Stability Matrix から kohya_ss がインストールできるようになったという事ですが、実際はこの Kohya's GUI の方でのインストールになっています。
今回はそのインストール方法と基本的な解説をします。
また、メンバーシップ向けの解説部分では設定ファイルのダウンロードやLoRAを作成、そして実際にイラストが作成できるまでのメイキングを行います。
それでは、やっていきましょう。
kohya_ssをインストールする
表題通り、Stability Matrix を使ってインストールします。
簡単に言うと、様々な Stable Diffusion の様々な生成アプリを簡単にインストールできたり、モデルなどを共用できたりする インストーラー 兼 管理アプリ ですね。
Stability Matrix の最新リリースページ
Stability Matrix の解説やインストールに関しては以前の記事 ↑ をご覧頂くとして、Kohya_ss のお話を進めます。
画面左のタブ、ダンボールアイコンの「Packages」を開きます。
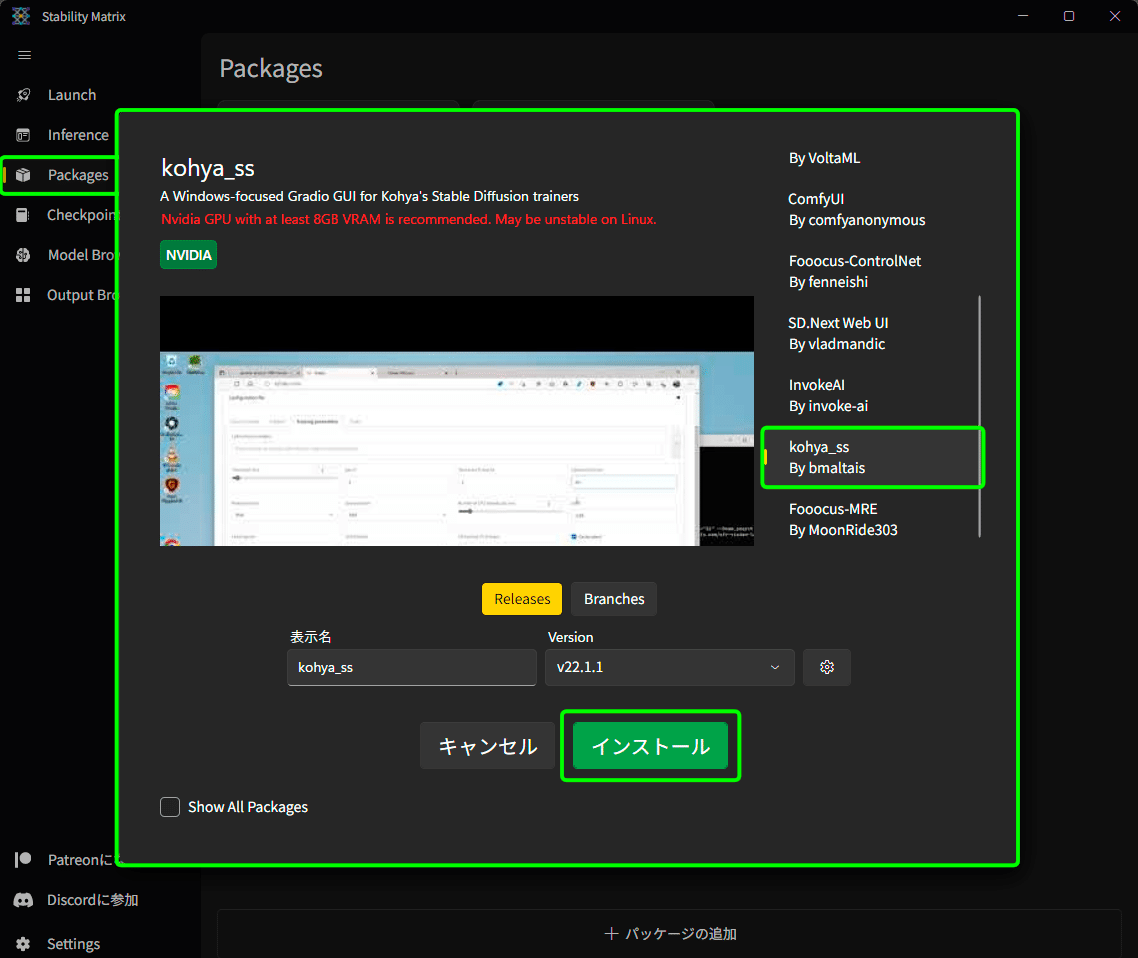
中央に出たウィンドウの右側のスクロールを滑らせ、「Kohya_ss By bmaltais」を選択し、緑色の「インストール」ボタンを押しましょう。

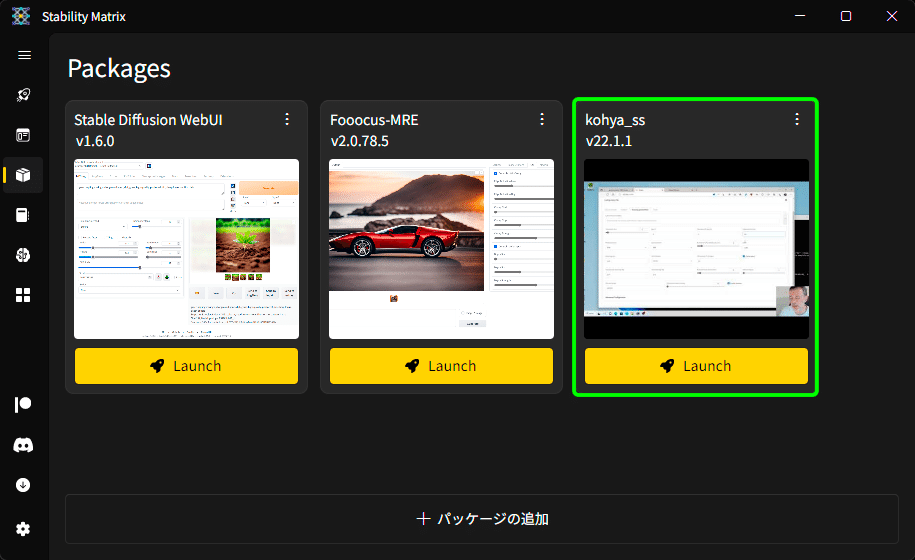
インストールが無事完了しましたら、実際に起動してみましょう。

画面左のロケットアイコンの「Launch」タブを開きましょう。
画面上部のプルダウンから Kohya_ss を選択し、緑色の「Launch」ボタンを押します。
画面はそのままで、本来ならコマンドプロンプトで流れていたような内容が Stability Matrix 内で表示されます。
実際ならもっと長い文章がでてくるのですが、Stability Matrix ではかなりあっさりしたものです。
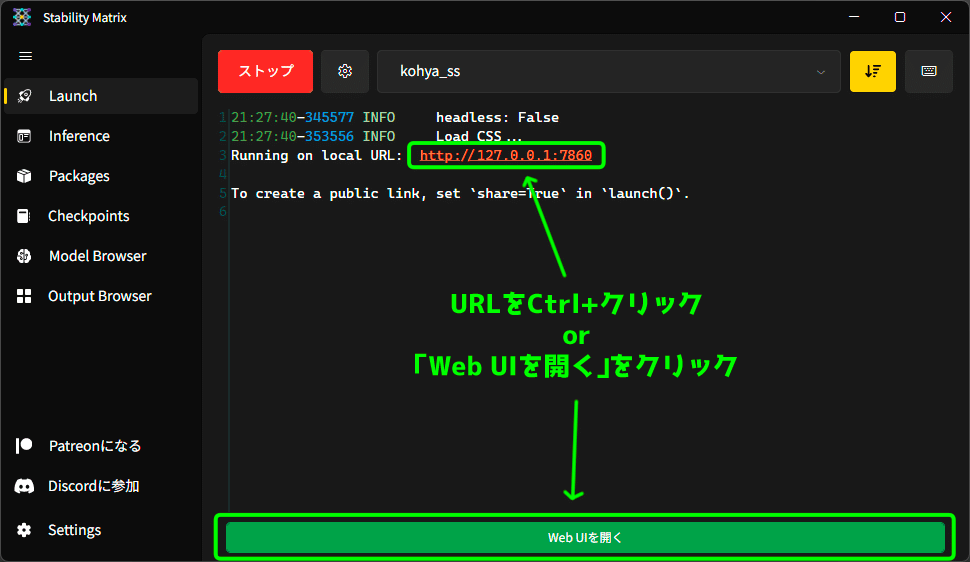
表示された URL を Ctrl+クリックするか、画面下部の「Web UIを開く」ボタンからブラウザの画面を開くことができます。

以前まではここまで来るのにかなり面倒な設定をしたり、罠みたいな設問に答えたりしたものですが、簡単にたどり着くことができました。
LoRAタブ画面の解説
まず先に、私なんかよりもよっぽど詳しい解説をしてくださっているページをご紹介しておきます。
私の解説も、基本的にはこちらのページの情報を参照して書かれてますので、あしからず。
今回の私の記事の内容で、もっと詳しいことが知りたいと思った時は是非こちらのページでご確認ください。
私はわかりやすさ、手軽さでやっていきます。
では、ここからは LoRAタブ の Traning 画面に関する内容と、Utilitiesタブ の一部をピックアップして解説していきます。
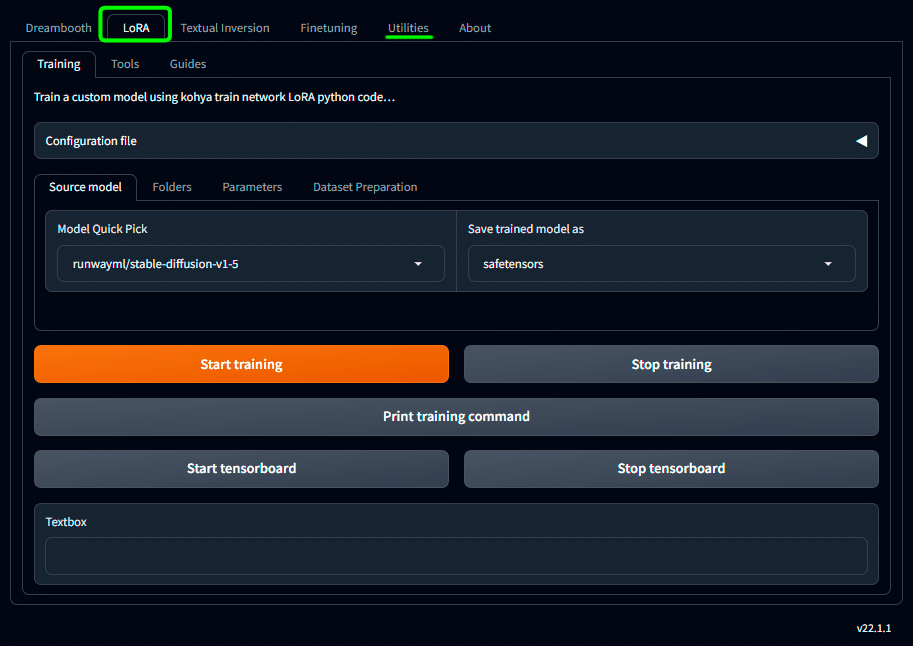
・Configuration file は設定のデータセーブの場所
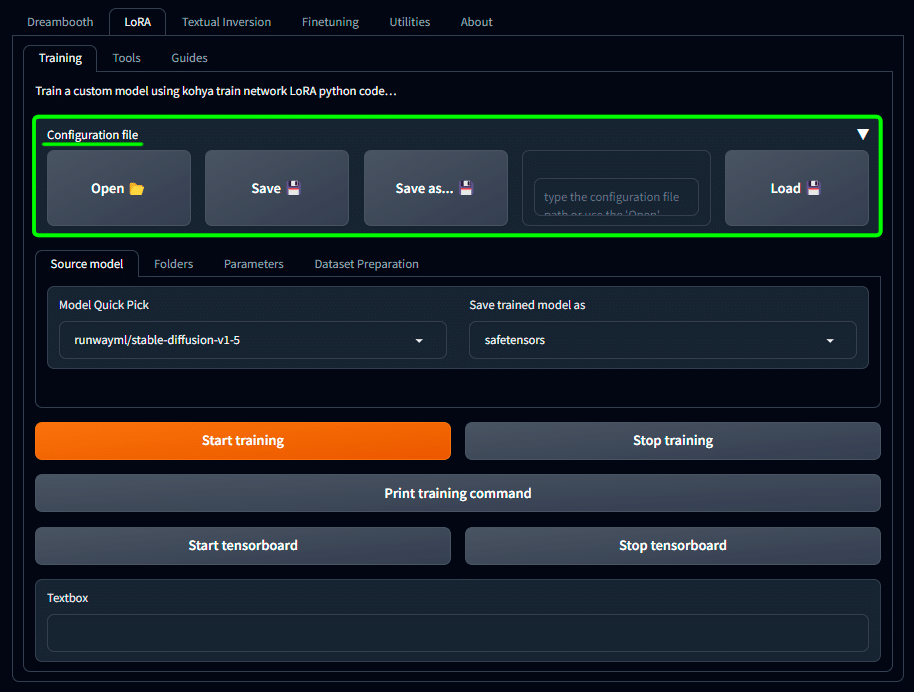
プルダウンをクリックすると、このような画面になります。
ここでは、LoRA学習用に設定した内容を .jsonファイル形式で保存しておくことができるため、次回また同じ設定で学習したい場合に設定を使いまわすことができます。
ゲームで言うところの、データセーブですね。
画面下部には「Source model」「Folders」「Parameters」「Dataset Preparation」といったタブがありますが、このあたりで設定した内容を丸っと保存しておけます。
保存場所は、\Packages\kohya_ss\presets\lora\user_presets をお勧めします。

実は \Packages\kohya_ss\presets\lora にはプリセットとして25個も .json という設定ファイルが保存されています。
そして、user_presets フォルダも最初から置いてありますので、そこに保存することで後述する Presets という設定項目でも選択できるようになります。
・Source model タブはLoRAを作る際に基準とするモデルを選択

LoRA は絵を描く際の追加資料である、という話は以前したことがあるのですが、追加ということは、ベースとなる資料(モデル)があってこそなわけで。
つまり、ベースをどういうモデルにするかを決めておかないと、最適な追加資料というものは出来ないんですね。
たまに、Civitai なんかで拾ってきた LoRA が、「うちのモデルだとあんまり効かない気がするんだけどなぁ」 という時は、その LoRA を作ったときのベースモデル と 現在ご自身が使おうとしているモデルとの差異がありすぎて、追加資料としての体を為さない場合だったりもします。
まぁつまり、基準点とするモデルをここで決めておこうや、という話です。
v2 , v_parameterization , SDXL Model のチェックに関しては以下の画像の通りです。

・ベースモデルが未だ根強い SD1.5 ならチェックはしなくて良い
・ベースモデルが SD2.0系統なら「v2」にチェック
・v-parameterization は SD2.0系の亜種。使うなら「v2」も同時にチェック
・SDXLをベースにするなら 「SDXL Model」 にチェック
まぁ、ほとんどは1.5 か SDXL のどちらかでしょう。
SD2.0 は中途半端だったのと、1.5がまだまだ燃え盛る時期だったので認知もあまりされてなかった印象です。
そのため、SDXLはインパクトのために名前を変えたとさえ言われてますね。
・Folders タブは学習画像の場所とLoRA出力先の指定
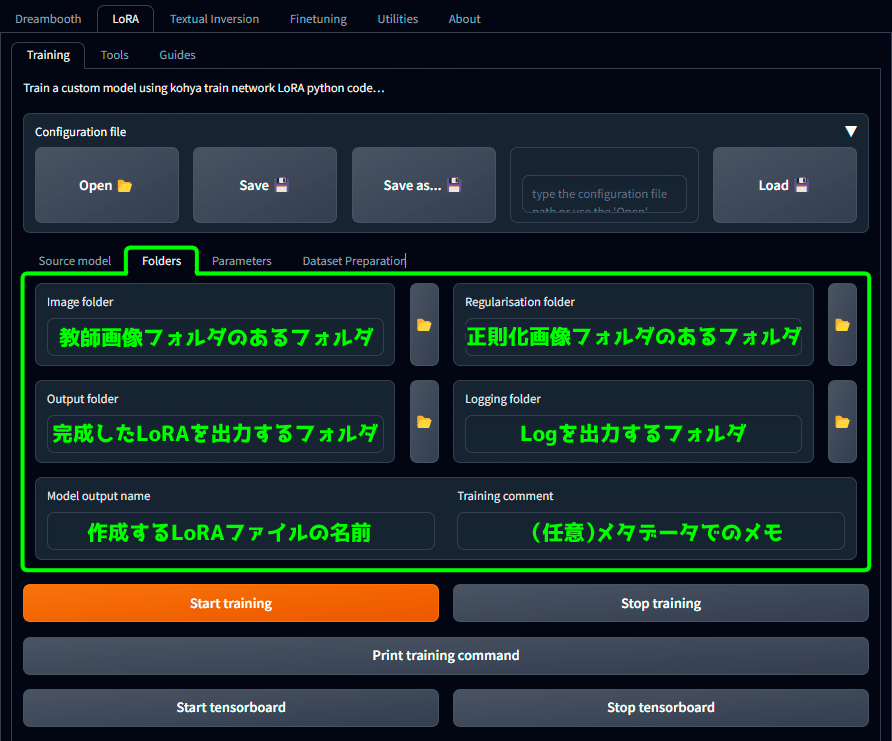
こちらも画像の通りです。
なんか、「教師画像フォルダのあるフォルダ」なんて書くと『頭痛が痛い』みたいなことになってそうなところがありますが、まぁ実際こうなのでなんとも。
詳しくはデータファイルの配布部分で私のフォルダ構成と一緒に図解するので、気になる方はそちらをどうぞ。
・Parameters タブは詳細設定
まず最初に、素人が下手に触るくらいならプリセット使え、が正解だと思います。
Configuration file の項でも述べましたが、現在
\Packages\kohya_ss\presets\lora に25個ものプリセットが格納されています。
下手に数値をいじると破綻する可能性もありますので、わからないならプリセットを丸っと使わせてもらいましょう。
- Basic タブ を丸っと画像で解説
UIは LoRA Type によって内容が変化します。
Standard: 基本、これで良い。以下の画像解説はコレを基本で解説。
LoHa-FA: は高効率なLoRA
LoCon: は学習をU-NetのResブロックまで広げたもの。
LyCORIS: LoRAを発展させた手法の総称で、LoRAの進化形です。
LyCORIS/LoCon: LoRAは全結合層(線形層)に中間層を差し込みますが、LoConでは畳み込み層(非線形層)にも中間層を差し込んでファインチューニングするため、多層の学習が可能になります。
LyCORIS/LoHa: LoRAが行列積を使用するのに対し、LoHaは行列AとBのアダマール積(要素ごとの積)を計算します。
LyCORIS/iA3: 比較的新しいアルゴリズム。実験的。ベースモデル専用になるので、汎用的ではなくなるかも。
LyCORIS/LoKr: LoHaがアダマール積を用いるのに対して、LoKrはクロネッカー積(2つの行列のすべての要素の積をとる操作)を使用します。
LyCORIS/DyLoRA: LoRAで最適なランクを見つけるための学習手法で、1回の学習で複数ランクのモデルを得ることができます。

当初は画像のみで解説のつもりでしたが、文字で検索ジャンプできた方が便利かもしれないので、一応内容も文字で抜き出していきます。
ブラウザの横サイズによってUIの並びが変化しますので注意してください。
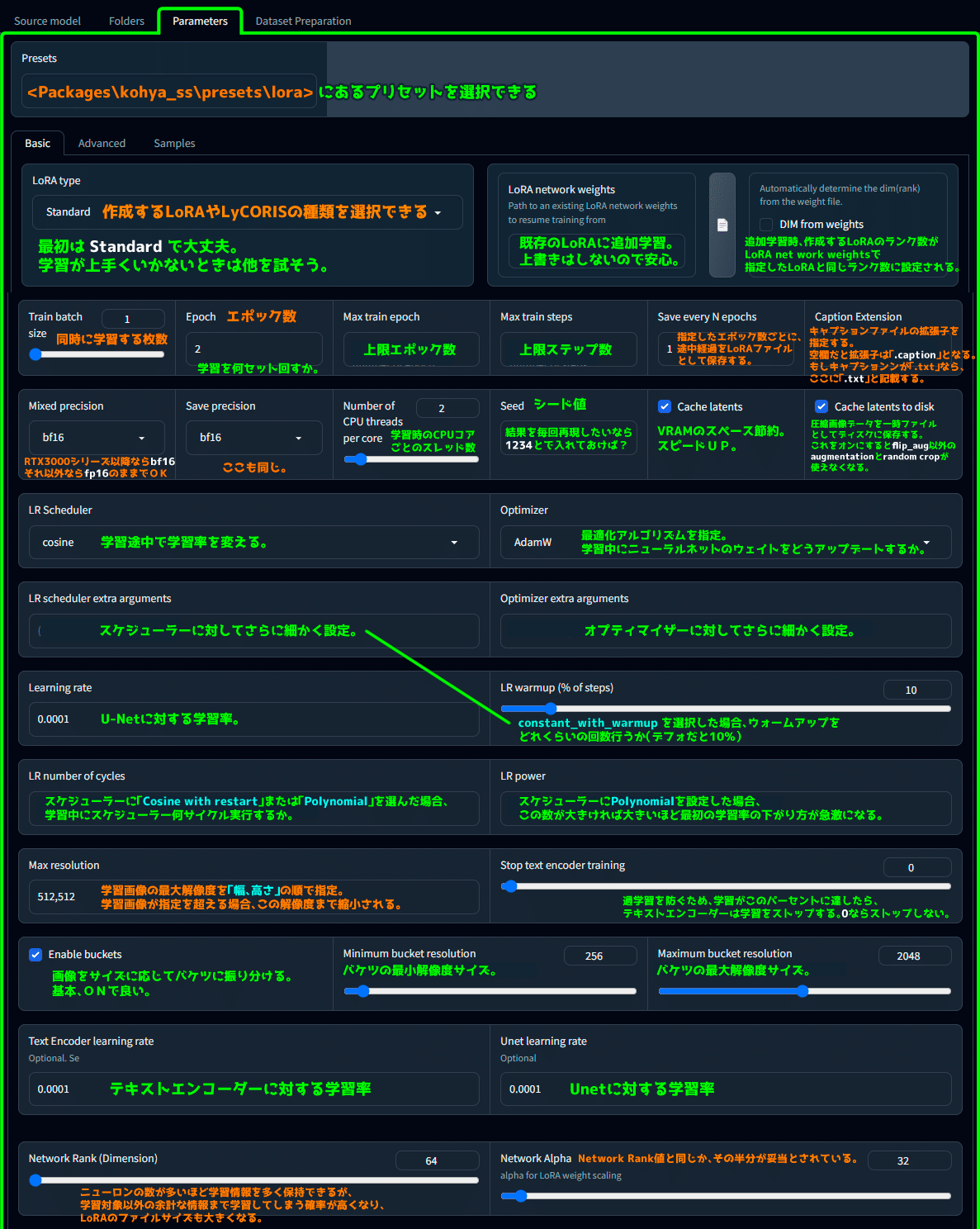
Presets
<Packages\kohya_ss\presets\lora> にあるプリセットを選択できる
Basic
LoRA type
「作成するLoRAやLyCORISの種類を選択できる」
最初はStandardで大丈夫。学習が上手くいかないときは他を試そう。
LoRA network weights
既存のLoRAに追加学習。上書きはしないので安心。
DIM from weights
追加学習時、作成するLoRAのランク数がLoRA net work weightsで指定したLoRAと同じランク数に設定される。
Train batch size
同時に学習する枚数
Epoch
学習を何セット回すか。
Max train epoch
上限エポック数
Max train steps
上限ステップ数
Save every N epochs
指定したエポック数ごとに、途中経過をLoRAファイルとして保存する。
Caption Extension
キャプションファイルの拡張子を指定する。
空欄だと拡張子は「.caption」となる。もしキャプションンが「.txt」なら、ここに「.txt」と記載する。
Mixed precision
RTX3000シリーズ以降ならbf16
それ以外ならfp16のままでOK。
Save precision
ここも同じ。
Number of CPU threads per core
学習時のCPUコアごとのスレッド数
Seed
シード値。結果を毎回再現したいなら1234とで入れておけば?
Cache latents
VRAMのスペース節約。スピードUP。
Cache latents to disk
圧縮画像データを一時ファイルとしてディスクに保存する。
これをオンにすると flip_aug 以外の augmentation と random crop が使えなくなる。
LR Scheduler
学習途中で学習率を変える。
Optimizer
最適化アルゴリズムを指定。学習中にニューラルネットのウェイトをどうアップデートするか。
LR scheduler extra arguments
スケジューラーに対してさらに細かく設定。
Optimizer extra arguments
オプティマイザーに対してさらに細かく設定。
Learning rate
U-Netに対する学習率。
LR warmup (% of steps)
constant_with_warmupを選択した場合、ウォームアップをどれくらいの回数行うか(デフォだと10%)
LR number of cycles
スケジューラーに「Cosine with restart」または「Polynomial」を選んだ場合、学習中にスケジューラー何サイクル実行するか。
LR power
スケジューラーにPolynomialを設定した場合、この数が大きければ大きいほど最初の学習率の下がり方が急激になる。
Max resolution
学習画像の最大解像度を「幅、高さ」の順で指定。
学習画像が指定を超える場合、この解像度まで縮小される。
Stop text encoder training
過学習を防ぐため、学習がこのパーセントに達したら、テキストエンコーダーは学習をストップする。0ならストップしない。
Enable buckets
画像をサイズに応じてバケツに振り分ける。基本、ONで良い。
Minimum bucket resolution
バケツの最小解像度サイズ。
Maximum bucket resolution
バケツの最大解像度サイズ。
Text Encoder learning rate
テキストエンコーダーに対する学習率
Unet learning rate
Unetに対する学習率
Use CP decomposition
CPUの速度を大幅に向上させることができ、その一方で制度の低下はわずかで済むらしい。
Network Rank (Dimension)
ニューロンの数が多いほど学習情報を多く保持できるが、学習対象以外の余計な情報まで学習してしまう確率が高くなり、LoRAのファイルサイズも大きくなる。
Network Alpha
Network Rank値と同じか、その半分が妥当とされている。
最下部分は選択している LoRA Type によって内容が変化するようです。

Scale weight norms
最大ノルム正則化のスケールを設定。
値が高いほど正則化の効果が弱く、低いほど強くなります。
Network dropout
ニューロンレベルで確率的にドロップアウトを行う設定。
過学習を抑制し安定性を向上。
推奨範囲は0.1~0.5です。
Rank dropout
各ランクに値億艇の確立でドロップアウトを適用する設定。
推奨範囲は0.1〜0.3です。
Module dropout
各モジュールに特定の確率でドロップアウトを適用する設定。
推奨範囲は0.1〜0.3です。

Convolution Rank (Dimension)
畳み込み層の微調整の複雑さを決定するパラメーター
Convolution Alpha
微調整の強さを制御するパラメーター
Scale weight norms
LoRAの過学習を抑制し、他のLoRAと合わせた時の安定性を向上させるのに効果的かも?
推奨設定は1で、この値が高いほど効果は弱く、低いほど効果は強くなります。
Network dropout
モジュール内のダウンウェイトを一定の確率でドロップアウトする。
デフォルトは0です。推奨範囲は0.1~0.5とされています。
DyLoRA Unit / Block sizeLoRA
LoRAの各ブロックのランクとアルファを個別に調整し、畳み込みのサイズや強度をコントロールする。

iA3 train on input
比較的新しいアルゴリズム。実験的。ベースモデル専用になるので、汎用的ではなくなるかも。
- Advanced タブ を丸っと画像で解説

Advanced
Weights (※これらの設定は上級者向けです。こだわりがないなら全て空欄で構いません。)
Down LR weights
U-Netの「down」ブロックの学習率の重み。
Mid LR weights
U-Netの「mid」ブロックの学習率の重み。
Up LR weights
U-Netの「up」ブロックの学習率の重み。
Blocks LR zero threshold
学習率がこの値以下の場合、LoRAモジュールは学習されません。
デフォルトは0.1
Blocks
Block dims
各ブロックのランク(次元)を指定します。
25個の数値を指定する必要があります。
Block alphas
各ブロックのアルファを指定します。
これは「block_dims」と同じ数の値を指定する必要があります。
Conv
Conv dims
LoRAのConv2d-3x3に拡張し、各ブロックのランク(次元)を指定します。
Conv alphas
LoRAのConv2d-3x3に拡張する際の、各ブロックのアルファを指定します。
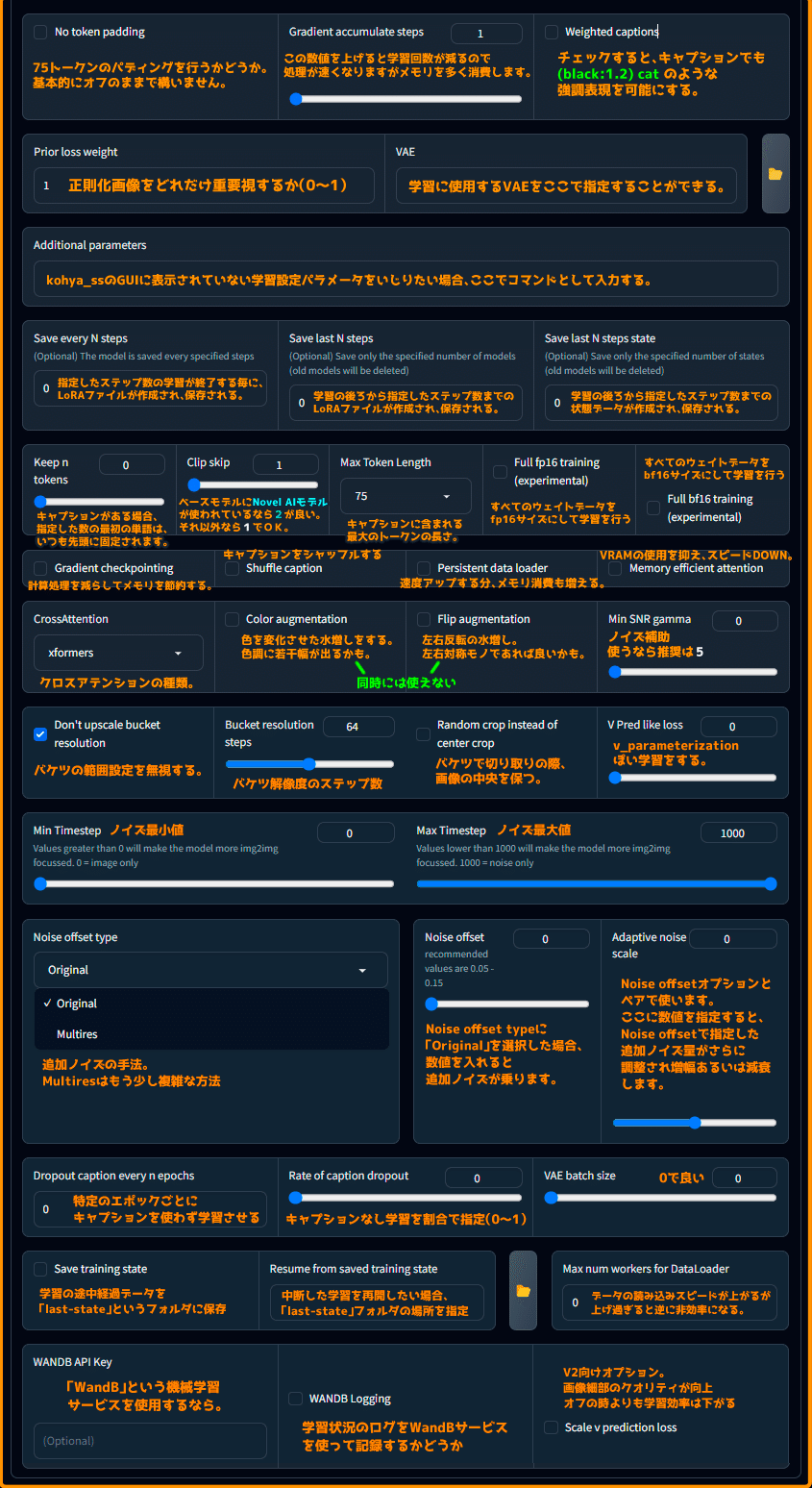
No token padding
75トークンのパディングを行うかどうか。基本的にはオフのままで構いません。
Gradient accumulate steps
この数値を上げると学習回数が減るので処理が早くなりますが、メモリを多く消費します。
Weighted caption
チェックすると、キャプションでも (black:1.2) cat のような協調表現を可能にする。
Prior loss weight
正則化画像をどれだけ重要視するか(0〜1)
VAE
学習に使用するVAEここで指定することができる。
Additional parameters
kohya_ss の GUI に表示されていない学習設定パラメータをいじりたい場合、ここにコマンドとして入力する。
Save every N steps
指定したステップ数の学習が終了する毎に、LoRAモデルが作成され、保存される。
Save last N steps
学習の後ろから指定したステップ数までのLoRAファイルが作成され、保存される。
Save last N steps state
学習の後ろから指定したステップ数までの状態データが作成されえ、保存される。
Keep n tokens
キャプションがある場合、指定した数の最初の単語は、いつも先頭に固定されます。ここでは「,」で区切ったものを1つの単語と判定する。
Clip skip
ベースモデルに Novel AIモデル が使われてるなら2が良い。それ以外なら1でOK。
Max Token Length
キャプションに含まれる最大のトークンの長さ。
Full fp16 training (experimental)
全てのウェイトデータをfp16サイズにして学習を行う。
Full bf16 training (experimental)
全てのウェイトデータをbf16サイズにして学習を行う。
Gradient checkpointing
計算処理を減らしてメモリを節約する。
Shuffle caption
キャプションをシャッフルする。
Persistent data loader
速度アップする分、メモリ消費も増える。
Memory efficient attention
VRAMの使用を抑え、スピードDOWN。
CrossAttention
クロスアテンションの種類。
Color augmentation
色を変化させた水増しをする。色調に若干幅が出るかも。(Flip augmentationと同時には使えない)
Flip augmentation
左右反転の水増し。左右対称モノであれば良いかも。(Color augmentationと同時には使えない)
Min SNR gamma
ノイズ補助。使うなら5。
Don't upscale bucket resolution
バケツの範囲設定を無視する。
Bucket resolution steps
バケット解像度のステップ数。
Random crop instead of center crop
バケツで切り取りの際、画像の中央を保つ。
V Pred like loss
v_parameterizationぽい学習をする。
Min Timestep
ノイズ最小値。
Max Timestep
ノイズ最大値。
Noise offset type
追加ノイズの手法。Multiresはもぷ少し複雑な方法。
Noise offset
Noise offset typeに「Original」を選択した場合、数値を入れると追加ノイズが乗ります。
Adaptive noise scale
Noise offsetオプションとペアで使います。ここで数値を指定するとNoise offsetで指定した追加ノイズ量がさらに調整され増幅あるいは減衰します。
Dropout caption every n epochs
特定のエポックごとにキャプションを使わずに学習させる。
Rate of caption dropout
キャプションなし学習を割合で指定(0~1)。
VAE batch size
0で良い。
Save training state
学習の途中経過データを「last-state」というフォルダに保存。
Resume from saved training state
中断した学習を再開したい場合、「last-state」フォルダの場所を指定。
Max num workers for DataLoader
データの読み込みスピードが上がるが上げ過ぎると逆に非効率になる。
WANDB API Key
「WandB」という機械学習サービスを使用するなら。
WANDB Logging
学習過程のログをWandBサービスを使って記録するかどうか。
Scale v prediction loss
V2向けオプション。画像細部のクオリティが向上。オフの時よりも学習効率は下がる。
- Samples タブ を丸っと画像で解説
LoRAを使った画像生成がどんな感じになるのか学習途中でチェックしたい場合、ここで画像生成プロンプトを入力します。
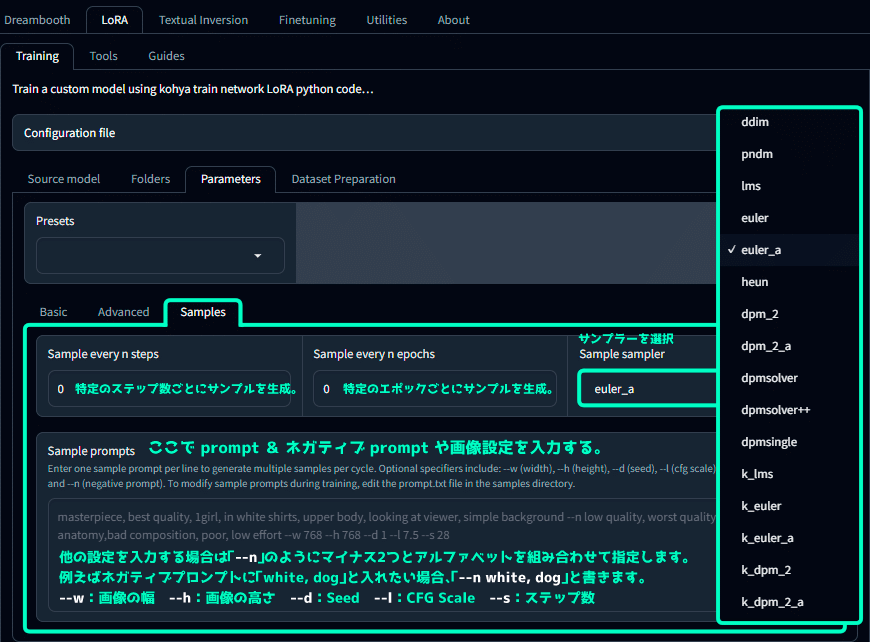
Sample every n steps
特定のステップ数ごとにサンプルを生成。
Sample every n epochs
特定のエポックぎおとにサンプルを生成。
Sample sampler
サンプラーをプルダウンから選択。
Sample prompts
ここで prompt & ネガティブ prompt や画像設定を入力する。
他の設定を入力する場合は「--n」のようにマイナス2つとアルファベットを組み合わせて指定します。
例えばネガティブプロンプトに「white, dog」と入れたい場合は「--n white, dog」と書きます。
--w : 画像の幅
--h : 画像の高さ
--d : Seed
--cfg : CFG Scale
--s : ステップ数
・Dataset Preparation タブ はデータ整理
ここはトレーニングプロセスがスムーズに進むようにデータを整える場所です。
わからない人は触らなくて良いと思います。
私もわかりません!!!
だが、とりあえずUIの解説だけはしておく、デキる小鳥🐣✨
Dreambooth/LoRA Folder preparation(フォルダの整理)
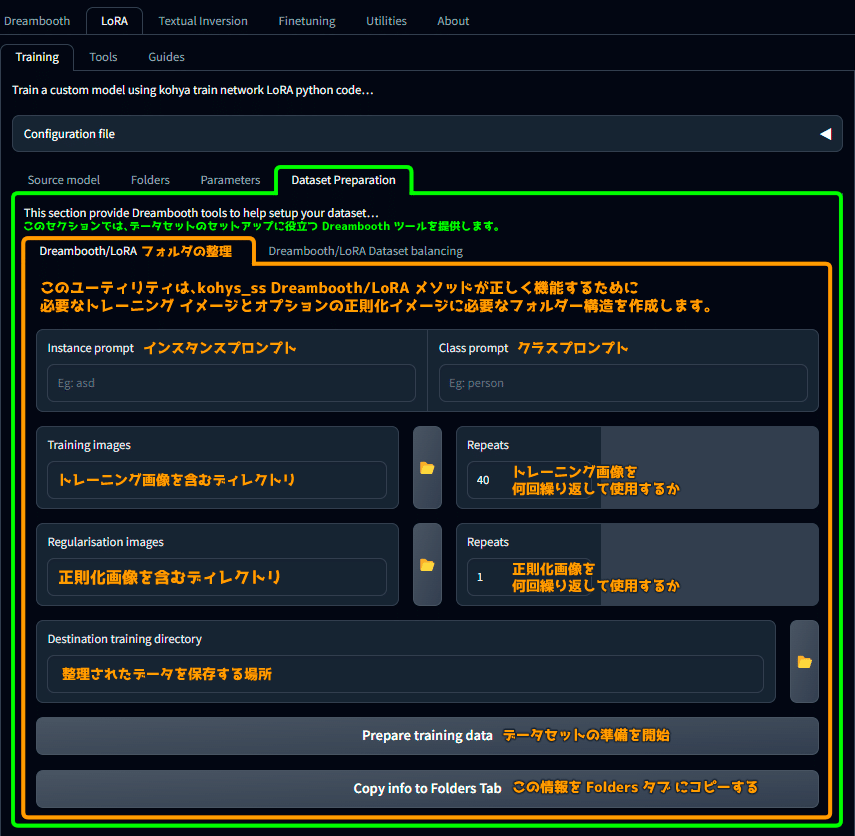
Dataset Preparation
このセクションでは、データセットのセットアップを支援する Dreambooth ツールを提供します。
Dreambooth/LoRA データの準備
このユーティリティは、kohya_ss Dreambooth/LoRA メソッドにてが正しく機能するために必要なトレーニングイメージとオプションの正則化イメージに必要なフォルダー構成を作成します。
Instance prompt
インスタンスプロンプト
Class prompt
クラスプロンプト
Training images
トレーニング画像を含むディレクトリ
Repeats
トレーニング画像数を何回の繰り返して使用するか
Regularisation images
正則化画像を含むディレクトリ
Repeats
正則化画像を何回の繰り返して使用するか
Destination training directory
整理されたデータを保存する場所
Prepare training data
データセットの準備を開始
Copy info to Folders Tab
この情報を Folders タブにコピーする
Dreambooth/LoRA Dataset balancing(データセットのバランス)
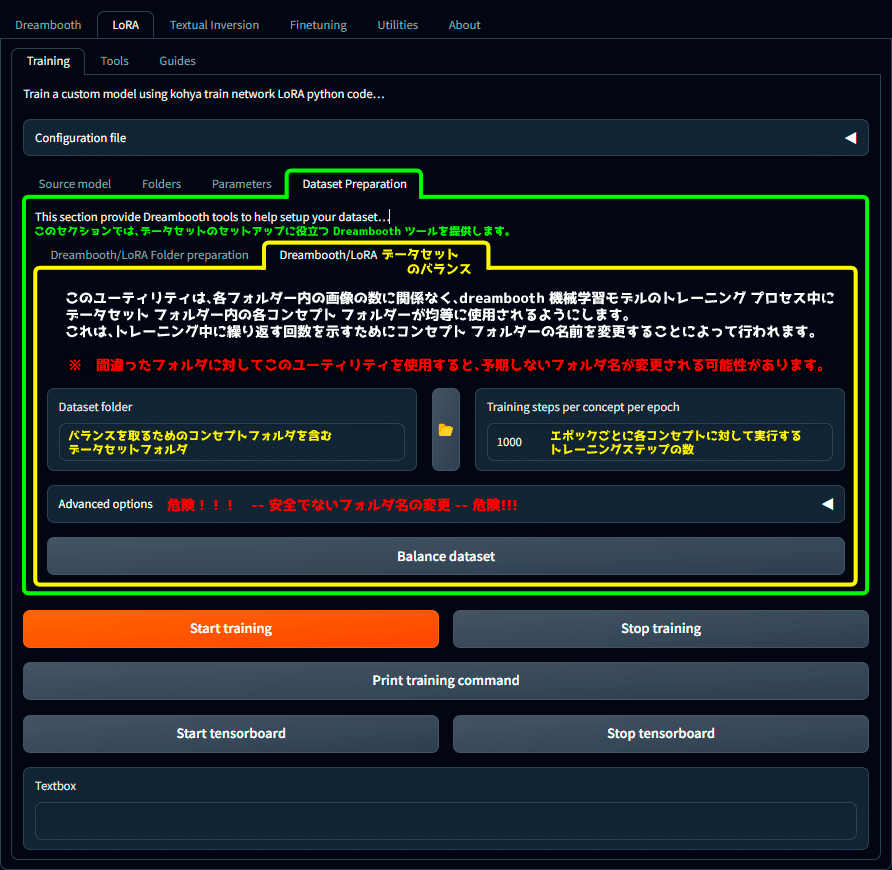
Dreambooth/LoRA
データセットのバランスを取る
このユーティリティは、各フォルダー内の画像の数に関係なく、dreembooth機械学習モデルのトレーニングプロセス中にデータセットフォルダー内の各コンセプトフォルダーが均等に使用されるようにします。
これは、トレーニング中にク理解す回数を示すためにコンセプトフォルダーの名前を変更することによって行われます。
※ 間違ったフォルダに対してこのユーティリティを使用すると、予期しないフォルダ名が変更される可能性があります。
Dataset folder
バランスを取るためのコンセプトフォルダを含むデータセットフォルダ
Training steps per concept per epoch
エポックごとに各コンセプトに対して実行するトレーニングステップの数
Advanced options
危険!!!! -- 安全ではないフォルダ名の変更 -- 危険!!!
Balance dataset
データセットを整理する
キャプションをつける機能の解説
後述するメイキング部分で扱うので、教師画像のキャプションを付けるための機能に関しても解説を入れておきます。
ここでは WD14 Captioning を使って解説します。
Utilities ➡ Captioning ➡ WD14 Captioning

このユーティリティは、WD14 を使用して、フォルダー内の描く画像のファイルにキャプションを付けます。
Image folder to caption
キャプションを付ける画像フォルダ
Caption file extension
キャプションファイルの拡張子
Undesired tags
望ましくないタグ
Prefix to add to WD14 caption
キャプション先頭につけるタグ
Postfix to add to WD14 caption
キャプション文尾につけるタグ
Use onnx
onnx を使用する
Append TAGs
既存のタグを置き換えるのではなく、タグを既存のタグに追加する。
Replace underscores in filenames with spaces
ファイル名のアンダースコアをスペースに置き換える
Recursive
サブフォルダの画像にもタグを付ける
Verbose logging
タグ付け中にデバッグすると、一般タグを文字タグを含む画像ファイルが印刷されます。
Show tags frequency
画像のタグの頻度を表示します
Model
モデル
Force model re-download
onnxに切り替えるときにモデルを強制的に再ダウンロードする。
General threshold
生成されるタグの量と質をコントロールする閾値。
Character threshold
キャラクター用の閾値。
Batch size
バッチサイズ
Max dataloader workers
最大のデータローダーワーカー数
Caption images
キャプションを画像に付ける
というわけで、死ぬほど時間をかけて内容を調べながら画像に書き出してみました。
別記事では Dataset Tag Editor でのキャプション編集方法も解説してますので、そちらも参考にしていただければと思います。
教師画像が多いほど Dataset Tag Editor は便利ですよ。
それでは、ここから先はメンバーシップ向けのメイキング内容となります。
今回も prompton でご注文頂いた個人様のオリジナルキャラクターに関して、キャラLoRAを作成して再現しつつ、自分の絵柄で魅力的なイラストにしたいと思います。
また、私が実際に使っているフォルダ構成の配布や、今回制作したLoRAのプリセット設定を配布しています。
正直、ここまでの解説画像も便利だとは思うんですが、大多数の人は
「解説あっても試行錯誤が面倒くせぇ、お前の成功設定を寄こせ」
だと思うんですよね🙄
この記事が気に入ったらチップで応援してみませんか?