
OpenAI o1はどう作るのか(概要編)

1. はじめに
OpenAIから久しぶりに新しいモデルが出ました。
OpenAI o1: 強力な推論能力と幅広い世界知識
OpenAI o1-mini: コーディングタスクに特化
モデルについての細かい説明はここではしませんが、OpenAIの公式報告によれば
競技プログラミング問題 (Codeforces) で 89 パーセンタイルにランクインし、米国数学オリンピック (AIME) の予選で米国のトップ 500 学生にランクインし、物理学、生物学、化学の問題のベンチマーク (GPQA) で人間の博士レベルの精度を超えています。
とのことです。少なくとも既存のLLMからは一歩抜きん出た能力を持っていそうです。
公式からOpenAI o1の詳細な中身については言及がありませんが、信憑性の高そうな話として、Google DeepMindの論文 "Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters" で言及されているアプローチに近い動きが採用されているのではないかと言うものがあります。
OpenAI Strawberry (o1) is out! We are finally seeing the paradigm of inference-time scaling popularized and deployed in production. As Sutton said in the Bitter Lesson, there're only 2 techniques that scale indefinitely with compute: learning & search. It's time to shift focus to… pic.twitter.com/jTViQucwxr
— Jim Fan (@DrJimFan) September 12, 2024
従って、今回はこの論文の内容からo1の動きを考えていきたいと思います。
2. 論文のアプローチ
Google DeepMindの論文 "Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters"のこのタイトルは日本語にすると『LLMのテスト時間計算(Test-Time Compute)を最適にスケーリングすることは、モデルパラメータをスケーリングするよりも効果的である。』です。
2.1 手法
これは、斜め読みした感じだと以下の感じのようです。
通常、LLM単体では、次のトークンの生成確率を探索(Greedy/Beam Search/Samplingなど)し文章を生成する。
LLMと合わせて新しくPRM(プロセス報酬モデル)というモデルを併用して使う。
PRMはLLMが出力した推論のステップ毎に正確性・有用性を予測する。この予測に基づいてステップレベルで探索を行うことで最終的な出力文章を決定する。
順を追って説明していきます。
通常、LLMの生成では以下の絵のように、次のトークンをその生成確率からGreedy Search, Beam Search, Samplingのような手法を用いてより確からしい文章を生成していきます。
この探索に使われるため、TemperatureやTop-kなどのパラメータが必要となっています。

論文のアプローチでは、LLMと合わせて新しくPRM(プロセス報酬モデル, Process Reward Model)というモデルを併用して使うようです。
このPRMは、LLMと異なり予測時に推論のステップごとに正確性・有用性を0-1で予測します。

LLMが次のトークンを探索して決定し、文章を生成していく。
文章が生成されていく過程でPRMが生成された検討ステップを評価し、正しい推論ステップを探索していく。
と言う流れを踏んでいくと言う話でした。
これによって、簡単な問題や中程度の難しさの問題では、テスト時計算を使用した小さいモデルが、14倍大きなモデルを上回るパフォーマンスを示しましたようです。
これによって、LLMはモデルサイズやデータ量をスケールさせる時代から推論時間をスケールさせる(つまり、沢山の推論ステップを探索する)時代に移っていきそうです。
2.2 PRM(Process Reward Model)の作成
PRMもLLMから作成します。論文では、PaLM 2-SというモデルをFine Tuningすることで作成しています。
Fine Tuningには、OpenAIが公開しているPRM800Kというデータを用いています。OpenAIが作成したデータというのもこの話の信憑性を上げている気がしますね。
PRM800Kとは数学に関連したデータセットで以下のような形式です。
MATHデータセットの問題に対して、推論ステップ毎に正誤を0,1のバイナリ形式で付与されています。
また、ステップの分割は改行毎に行われています。

これを用いてFine Tuningするため、PRMは推論過程の正確性・有用性を判定できるようになるようです。
私の知る限りこの形式のデータはこれしかないので、一般的な推論に関してこうしたデータを用意するのはかなり難しいだろうなと思いました。
3. OpenAI o1の作り方
3.1 強化学習
公式やGreg Brockman氏の投稿を見ると、以下のような投稿があります。
人間が難しい質問に回答する前に長い時間考えるのと同じように、o1 は問題を解決しようとするときに思考の連鎖(Chain of Thought)を使用します。強化学習を通じて、o1 は思考の連鎖を磨き、使用する戦略を洗練することを学びます。間違いを認識して修正することを学びます。
OpenAI o1 — 回答する前に問題について真剣に考えるように強化学習でトレーニングされた最初のモデル。
(中略)
しばらく前に、モデルに「段階的に考える」ように促すとパフォーマンスが向上することが発見されました。しかし、試行錯誤しながらモデルを最初から最後までトレーニングする方がはるかに信頼性が高く、Go や Dota などのゲームで確認したように、非常に印象的な結果を生み出すことができます。
キーワードは思考の連鎖(Chain of Thought; CoT)と強化学習のようです。
Google DeepMindが提案している手法はあくまでLLMとPRMを推論時に併用するもので、LLM自体を学習するものではありませんでした。
一方で、OpenAI o1は強化学習を行なっているということを明言しています。
従って、PRMを報酬モデルとしてLLMを強化学習したモデルがo1なのではないかと思います。
つまり、AlphaGoが1手1手勝つための道筋を学習していくように、ロボットが障害物を避けてゴールへの辿り着き方を学習するように、LLMを正しい推論結果への辿り着き方を学ばせていくのではないでしょうか。
Reinforcement Learning for Chain of Thought(RLCoT)とでも呼ぶのでしょうか。元々、強化学習を強みとしていたOpenAIらしい手法だと思います。
(2024/9/14 追記)
Tom Yeh氏がX上でとてもわかりやすい図を作成してくれていました。
RLFHはReward Model(報酬モデル)を用いてAnswerに対して報酬を予測し、LLMを学習させます。
他方、OpenAI o1の手法ではPRM(プロセス報酬モデル)は、Answerだけでなく推論プロセスの1ステップ毎に報酬を予測できます。このため、推論途中のどこで間違えたのかをLLMが学んでいくことができるのだと思います。
How does OpenAI train the Strawberry🍓 (o1) model to spend more time thinking?
— Tom Yeh (@ProfTomYeh) September 13, 2024
I read the report. The report is mostly about 𝘸𝘩𝘢𝘵 impressive benchmark results they got. But in term of the 𝘩𝘰𝘸, the report only offers one sentence:
"Through reinforcement learning, o1… pic.twitter.com/OYpXpC2sZp
3.2 推論(Reasoning)トークン
OpenAIのドキュメントには以下のような図が示されています。
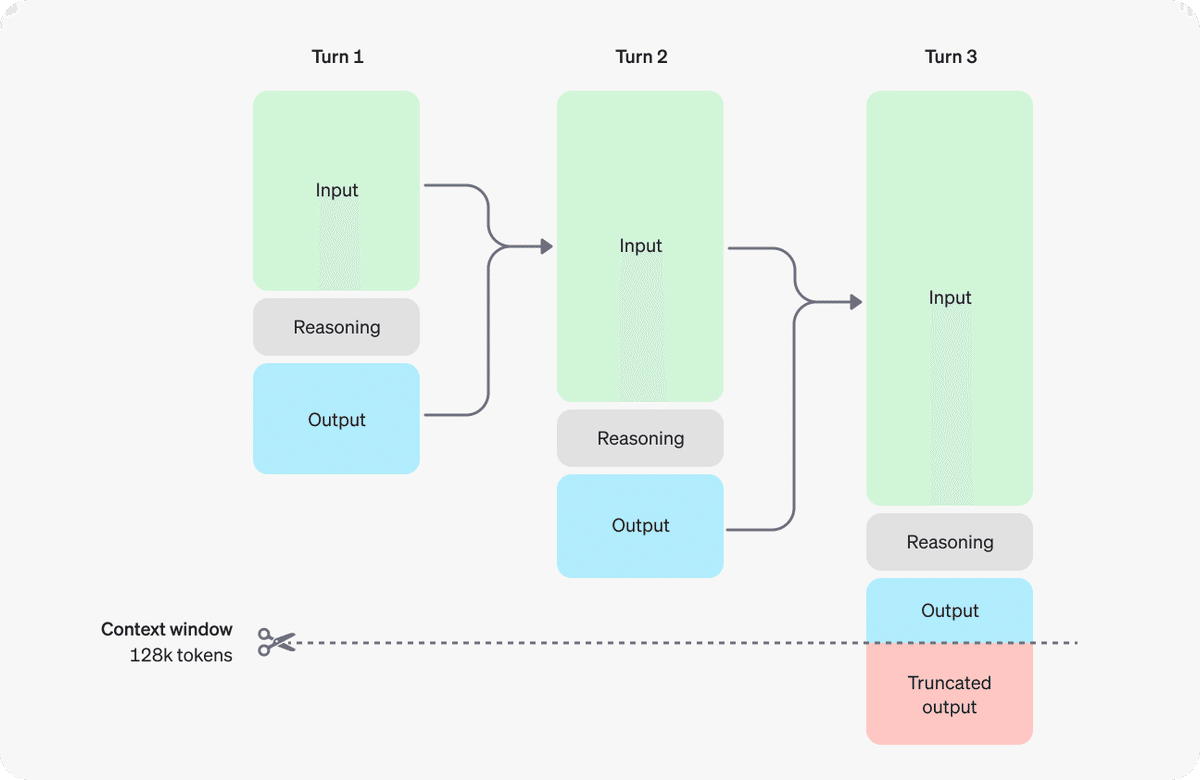
これらの推論ステップがReasoningに当たる場所で行われるのだと考えられます。また上記の図から分かる通り、現状のLLMは例えば
<user></user>
<assistant></assistant>のようにHumanMessageとAIMessageを区別しているのを、
<user></user>
<reasoning></reasoning>
<assistant></assistant>と出力するようにInstruction Tuningされているようです。
このReasoning内の各行が推論の1 stepとしてPRMに評価されるのだと考えられます。"</reasoning>"が出力されたらReasoningが完了となるのではないでしょうか。
3.3 推論ステップの区切り
ステップの推論をどう分けているかは説明がありません。上記のPRM800Kは、ステップ毎の分割は改行で判断しているようです。
公式のブログを確認してみると、以下のような感じです。

完全に出力の感じを見ただけでの判断になりますが、不自然に1行毎に改行が挟まれており、PRM800Kと同じように改行毎にステップ分けをしているように感じます。
一方で、ChatGPT UIで思考内容を開いてみてみると、1行づつ何やらタイトルのようなものが付けられています。(解読のヒントを探る、など)
これは、改行毎にステップ分けしていて、後から軽量モデルで何を考えていたかのタイトルづけをしているのではないかと思います。

4. OpenAI o1の限界とその先
これまでの想定が全て正しければ、の話をします。
もし上記の方法、あるいは似たような方法でOpenAI o1が作られているのならば、ある限界があるはずです。
それはPRMの学習データが、明確に答えのある分野に限られるという点です。
囲碁やロボットの迷路探索における強化学習には、勝ちやゴール地点への到達というゴールがありますが、一般的な推論には決定的な正解がない場合が多々あると思われます。
そうした時に安定した学習ができるのでしょうか。
だからこそOpenAI o1では、数学や科学的な推論など既存の明確に答えのある問題を中心に学習されたのだと思います。
その先までこの手法で問題なくいけることを示されるといいなと個人的には思っています。(AGIの到来?)
(とはいえ、強制的にStep by Stepで推論されるのでその分の推論能力上昇はどの分野でもある程度起こっていると思われます。)
まとめ
論文やXの投稿などから色々と予測を交えてふわっとしたOpenAI o1の作り方を考えてみました。
結論としては、シンプルですが以下の流れなのかなという結論です。
LLMをInput, Reasoning, Outputの出力をするようにInstruction Tuning
PRMデータを作成する(手動?合成データで作成する方法がある?)
LLMをFineTuningしてPRMを作成
LLMを強化学習
色々と知識不足な点・強化学習について(一度勉強したものの)忘れている点もあり間違えている箇所、より効率的なやり方、考えが甘い点等あるかもしれません。(更には、あくまで私の予測なので、ミスリーディングがあるかもしれません。)
何か議論や感想があればNoteやX(Twitter)でコメント・ご教示いただけると助かります。
私自身新たな気づきがあれば追記していこうと思います。
X: https://twitter.com/CurveWeb
目を通していただきありがとうございました。
続き
参照
https://openai.com/index/learning-to-reason-with-llms/
https://platform.openai.com/docs/guides/reasoning
OpenAI o1-preview and o1-mini are rolling out today in the API for developers on tier 5.
— OpenAI Developers (@OpenAIDevs) September 12, 2024
o1-preview has strong reasoning capabilities and broad world knowledge.
o1-mini is faster, 80% cheaper, and competitive with o1-preview at coding tasks.
More in https://t.co/l6VkoUKFla. https://t.co/moQFsEZ2F6
OpenAI Strawberry (o1) is out! We are finally seeing the paradigm of inference-time scaling popularized and deployed in production. As Sutton said in the Bitter Lesson, there're only 2 techniques that scale indefinitely with compute: learning & search. It's time to shift focus to… pic.twitter.com/jTViQucwxr
— Jim Fan (@DrJimFan) September 12, 2024
o1 may be good at reasoning, but bombs on code completion
— Bindu Reddy (@bindureddy) September 13, 2024
However the models do quite well on code generation
Overall they underperform compared to Sonnet 3.5 pic.twitter.com/JA3VDyNy50
How does OpenAI train the Strawberry🍓 (o1) model to spend more time thinking?
— Tom Yeh (@ProfTomYeh) September 13, 2024
I read the report. The report is mostly about 𝘸𝘩𝘢𝘵 impressive benchmark results they got. But in term of the 𝘩𝘰𝘸, the report only offers one sentence:
"Through reinforcement learning, o1… pic.twitter.com/OYpXpC2sZp