
WizardLM-2の開発方法: Auto Evol-Instruct

はじめに
2024年4月に高い性能を叩き出し、オープンライセンスで公開されたにも関わらずすぐにHugging Faceから消されたWizardLM-2というモデルがあります。(現在、HuggingFace上には非公式のモデルのみ公開されています。短期間公開されていたタイミングにダウンロードされていたのでしょうか。)
以下のように高い性能を叩き出したことでWizardLM-2は注目を集めましたが、コードも論文も公開されておらず、その開発方法は概要レベルでしか知られていませんでした。
(MT-Benchは複数ターンの会話能力を測るベンチマークです。)
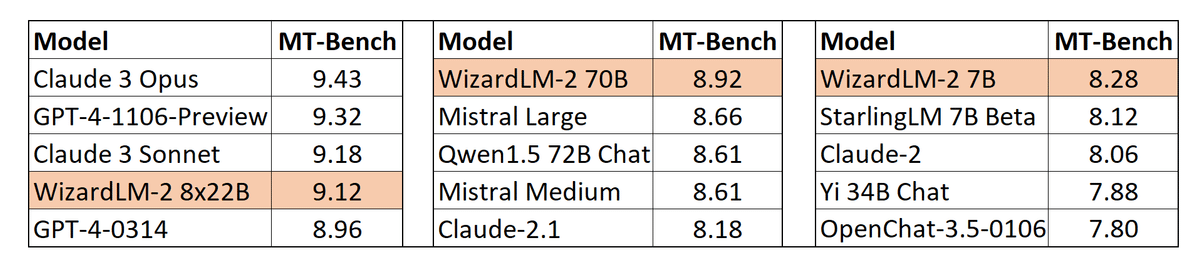
そのWizardLM-2の開発方法に関わる2つの論文が2024年7月に公開されました。
Arena Learning
Auto Evol-Instruct
特にSynthetic data(合成データ)の生成方法に関わる部分であるAuto Evol-Instructを実装していくため読んでみようと思います。
Synthetic dataとはLLMによって、LLMの学習のためのデータを作成するという試み・作成したデータのことです。色々な手法があり、別ノートにまとめているのでよければご参照ください。
1. Evol-Instructとは
Auto Evol-Instructは、WizardLM-1(2と分けるために明示的に1と書きます。)の際に使われたEvol-Instructを拡張した手法になります。
Evol-Instructの詳細は上記の別ノートにまとめていますが、簡単に述べると『既存のInstruction Tuning Dataを、より複雑なタスクとそれに対する回答に進化させる』ということをします。
日本語でEvol-Instructのコードはこちらにあります。
2. Auto Evol-Instructの概要
Evol-Instructは、そのEvolving Method(進化手法; つまり進化のためのプロンプト)を人が作成していました。それにはおそらく、通常のプロンプトエンジニアリングと同じように「このプロンプトだとうまくデータが進化する」「これだとうまくいかない」というのを繰り返したのだと思います。
Auto Evol-InstructではこのプロンプトエンジニアリングをLLMにやらせるということをやらせました。
Auto Evol-InstructではこれをEvolving MethodのプロンプトエンジニアリングをEvolving Method Optimization(進化手法の最適化)としています。
3. Evolving Method Optimization
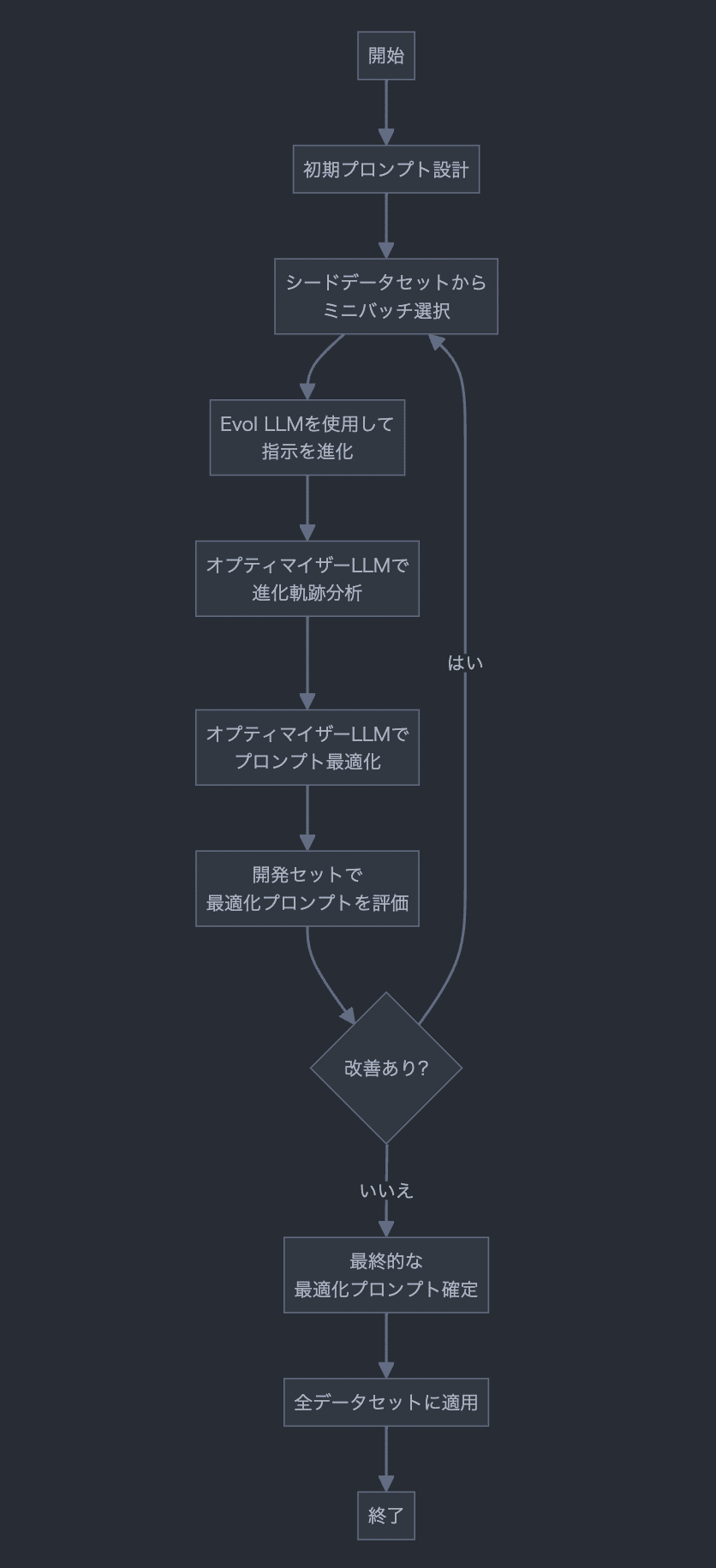
進化手法の最適化の大まかな流れは以下の通りです。3まで行ったらまた1に戻る、というのを指定回数繰り返します。
現状の進化手法(進化プロンプト)でデータを進化
進化がうまくいっているか分析(Evol Trajectory Analysis; 進化軌跡分析)
現状の進化手法 + 分析結果を元に、進化手法の最適化
1, 2, 3ともにllmを使います。1をEvol LLMに、2, 3をOptimizer LLMと呼びます。これは別のLLMを用いても良いですし、同じLLMでも問題ないと思います。
進化手法の最適化を含めてのAuto Evol-Instructの大まかな流れを以下に示します。
3.1 実際のプロンプト例: 指示進化(Initial)
進化手法(進化プロンプト)でデータを進化する際の最初のプロンプトとしては以下が示されていました。

これを日本語にすると以下の通りです。
あなたは、与えられた「#命令#」をより複雑なものに書き換える「命令リライター」です。以下の手順に従って、与えられた「#命令#」をより複雑なものに書き換えてください。
ステップ1: 「#命令#」を注意深く読み、この命令をより複雑にするために可能な方法をすべて列挙してください(ChatGPTやGPT4のようなよく知られたAIアシスタントが扱うのが少し難しくなるようにします)。命令の言語を変更する方法は提供しないでください!
ステップ2: ステップ1で作成した#メソッドリスト#に基づいて、#命令#をより複雑にするための包括的な計画を作成してください。その計画には、#メソッドリスト#からいくつかのメソッドを含める必要があります。
ステップ3:ステップごとに計画を実行し、#Rewritten Instruction#を提出してください。#リライトされたインストラクション#」は、「#インストラクション#」に10語から20語を追加する程度で構いません。
ステップ4: 「#書き換えられた指示#」を注意深く確認し、不合理な箇所を特定してください。その「#書き換えられた指示#」が、「#指示#」をより複雑にしたものにすぎないことを確認してください。何の説明もなく、#Finally Rewritten Instruction # を提出すること。
以下のフォーマットで厳密に回答してください:
ステップ1
#方法リスト#:
ステップ2
#プラン#:
ステップ3
#書き直された指示#:
ステップ4
#最終的に書き直された指示#:
#指示#:
これをベースにプロンプトを最適化させていきます。これを15ステップ最適化させると次のようになるようです。

3.2 実際のプロンプト例: 進化軌跡分析
進化がうまくいっているか分析(Evol Trajectory Analysis; 進化軌跡分析)のプロンプトとしては以下が示されていました。

これを日本語にすると以下のようになります。
以下のリストは、インストラクションがより複雑なインストラクションに進化するケースを示しています。
それぞれのケースについて、ステージ0は初期状態の「インストラクション」を表し、それ以降の各ステージでは、前のステージに基づいて複雑さを増す必要があります。
進化に失敗したケースを特定し、そのケース ID と理由を記入してください。
{進化の軌跡}
3.3 実際のプロンプト例: 進化手法最適化
現状の進化手法 + 分析結果を元に進化手法の最適化のプロンプトとしては以下が示されていました。

これを日本語にすると以下のようになります。
{フィードバック}
上記の命令を進化させるための方法を提供します。
あなたは、進化失敗ケースからのフィードバックに基づいて、他のケースの性能を損なわずに、このメソッドを最適化する必要があり、最適化されたメソッドによってもたらされる複雑さの増加が以前のメソッドを下回らないようにしてください。
最適化された方法を以下の形式で提供してください。
```最適化手法\n<最適化手法はこちら>\n```
{進化プロンプト}
4. Auto Evol-Instruct vs Evol-Instruct
最後にAuto Evol-Instructの強力さを共有します。
比較方法として、作った合成データを使って学習したモデルのGSM8Kベンチマークのスコアを比較しています。GSM8Kは数学能力のベンチマークです。
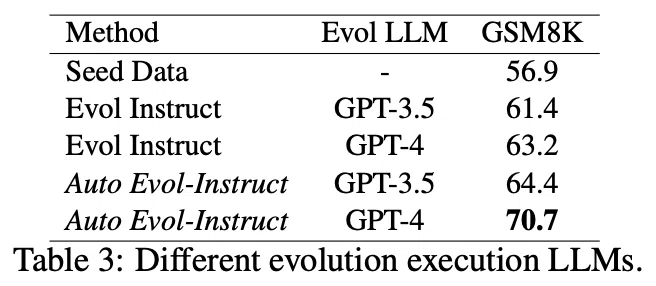
Evol Instructの時点でスコアを上げているものの、Auto Evol-Instructはさらに大きくスコアを上げています。
もはやプロンプトを人間が作ることがボトルネックになっていることが見て取れます。
最後に
Microsoftは良い論文を書くのですが、こうした強力な手法はなかなかコードを公開してくれません。
日本語のデータでAuto Evol-Instructのコードを作成中なのでそのうち公開しようと考えています。また、結果をここに書き足せたらと思っています。