
進化的アルゴリズムをもちいたChatVector加算の最適化

はじめに
これまで何度かChatVectorやそれに類することを施行してきましたが、元のモデル+ChatVectorの加算はいつも1:1で実施してきました。それでもある程度上手くいっていましたが、この加算比率をSakanaAIのEvoLLMのように最適化するということができるらしいです。
ただ、調べた限りコードが落ちていなかったので自分なりに調べて試してみたというのが本記事の内容になります。
1. ライブラリの準備
とりあえずGoogle Colabで試しました。
進化的アルゴリズムを使用するために、optunaとcmaesをinstallします。
(その他はLLMを動かす用)
!pip install optuna cmaes openai
!pip install -U accelerate transformers
!pip install torch datasets2. モデルとChatVector取得
以前試した組み合わせで最適化を試していきます。ChatVectorは既に作成してHuggingFaceに置いてあるのでそれを使います。ChatVectorの抜き出し方は別記事をご参照ください。
Base Model: tokyotech-llm/Swallow-MS-7b-v0.1
Chat Vector: HachiML/SkillTree-Chat-LAB-Mistral-7B-v0.1
これを1:1で合わせたものはこちらです。
HachiML/Swallow-MS-7b-v0.1-ChatSkill-LAB
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
# 日本語ベースモデル
jp_model_name = "tokyotech-llm/Swallow-MS-7b-v0.1"
jp_model = AutoModelForCausalLM.from_pretrained(
jp_model_name,
torch_dtype=torch.bfloat16,
device_map="cuda",
)
jp_tokenizer = AutoTokenizer.from_pretrained(jp_model_name)# Chat Vector
chat_vector_name = "HachiML/SkillTree-Chat-LAB-Mistral-7B-v0.1"
chat_vector = AutoModelForCausalLM.from_pretrained(
chat_vector_name,
torch_dtype=torch.bfloat16,
device_map="cpu",
)3. 評価の準備
進化的アルゴリズムをもちいて各layerの加算比率の最適化を測る際に、指標となる評価軸が必要です。
SakanaAI/EvoLLM-JP-v1-7Bなどは数学能力を持つ日本語モデルなので、MGSMの自作の日本語データセットを使った様です。
ChatVectorではChatの能力を評価する例えばMT-Benchのような評価指標が望ましいと思われます。あまり取りたくない手段ではありますが、ELYZA-tasks-100の最初の10件をGPT-4-turbeで評価したものを指標とします。
import torch
from datasets import load_dataset
from transformers import AutoModelForCausalLM, AutoTokenizer
ds = load_dataset("elyza/ELYZA-tasks-100", revision="1.0.0")
# 最初の10件のデータを抜き出す
ds_ten = ds['test'].select(range(10))
data_ten = ds_ten.to_pandas().to_dict('records')
print(data_ten)推論用のプロンプトを作成し、あらかじめトークナイズしておきます。
また、推論用の関数も定義します。
B_INST, E_INST = "[INST]", "[/INST]"
B_SYS, E_SYS = "<<SYS>>\n", "\n<</SYS>>\n\n"
DEFAULT_SYSTEM_PROMPT = "あなたは誠実で優秀な日本人のアシスタントです。"
def tokenize_prompt(tokenizer, input_text):
prompt = "{bos_token}{b_inst} {system}{prompt} {e_inst} ".format(
bos_token=tokenizer.bos_token,
b_inst=B_INST,
system=f"{B_SYS}{DEFAULT_SYSTEM_PROMPT}{E_SYS}",
prompt=input_text,
e_inst=E_INST,
)
token_ids = tokenizer.encode(
prompt, add_special_tokens=False, return_tensors="pt"
)
return token_ids
def pred(model, tokenizer, input_ids):
with torch.no_grad():
output_ids = model.generate(
input_ids.to(model.device),
max_new_tokens=512,
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id,
)
output_text = tokenizer.decode(
output_ids.tolist()[0][input_ids.size(1) :], skip_special_tokens=True
)
return output_text
# tokenizeの事前実施
for i in range(len(data_ten)):
data_ten[i]['input_ids'] = tokenize_prompt(jp_tokenizer, data_ten[i]['input'])4. 評価の準備(OpenAI)
OpenAIのAPI keyを設定します。
# 環境変数の準備
from google.colab import userdata
import os
os.environ["OPENAI_API_KEY"] = userdata.get('OPENAI_API_KEY')Docsを参照し、OpenAIに投げるためのcompletion_with_backoffを作成。
import openai
from tenacity import retry, stop_after_attempt, wait_random_exponential
@retry(wait=wait_random_exponential(min=1, max=60), stop=stop_after_attempt(6))
def completion_with_backoff(**kwargs):
return openai.chat.completions.create(**kwargs)評価用関数の定義。
eval_model = "gpt-4-0125-preview"
def gpt4eval(pred, input_text, output_text, eval_aspect):
prompt = f"""あなたは採点者です。
問題, 正解例, 採点基準, 回答 が与えられます。
採点基準と正解例を参考にして、回答を1,2,3,4,5の5段階で採点し、数字のみを出力してください。
# 問題
{input_text}
# 正解例
{output_text}
# 採点基準
基本的な採点基準
- 1点: 誤っている、 指示に従えていない
- 2点: 誤っているが、方向性は合っている
- 3点: 部分的に誤っている、 部分的に合っている
- 4点: 合っている
- 5点: 役に立つ
基本的な減点項目
- 不自然な日本語: -1点
- 部分的に事実と異なる内容を述べている: -1点
- 「倫理的に答えられません」のように過度に安全性を気にしてしまっている: 2点にする
問題固有の採点基準
{eval_aspect}
# 回答
{pred}
"""
response = completion_with_backoff(
model=eval_model,
messages=[{"role": "user", "content": prompt}],
temperature=0,
frequency_penalty=0,
presence_penalty=0,
)
gpt4score = response.choices[0].message.content
try:
gpt4score = int(gpt4score)
except ValueError:
gpt4score = None
return gpt4score5. 進化的アルゴリズムによる最適化
from tqdm.auto import tqdm
import optuna
import gc
import copy
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")都度、新しい比率でChatVectorを加算するための関数です。merging_ratioに関しては後述しますが、layer毎の加算比率を格納しています。
def apply_skill(model, skill_tree, merging_ratio):
# jp_modelのコピーを作成
cv_model = copy.deepcopy(model)
# excluded object
skip_layers = ["model.embed_tokens.weight", "model.norm.weight", "lm_head.weight"]
# apply skill
for k, v in cv_model.state_dict().items():
# layernorm is also excluded
if (k in skip_layers) or ("layernorm" in k):
continue
key_base = k.split('.')[0] + '.' + k.split('.')[1] + '.' + k.split('.')[2] # 'model.layers.X' を取得
vector = skill_tree.state_dict()[k]
new_v = v + merging_ratio[key_base] * vector.to(v.device)
v.copy_(new_v)
return cv_model以下が最適化したい関数です。進化的アルゴリズムを使って、この関数のoutputであるscoreを最適化(最小化)します。
optimize_merging_ratioの中身は大きく分けて3段階です。
merging_ratio(ChatVectorの加算比率を各layer毎に持つ辞書)の定義
merging_ratioにしたがって、ChatVectorのマージ
ELYZA tasks 10の実施とGPT4による評価
# 最適化する関数
def optimize_merging_ratio(trial):
# merging_ratio(ChatVectorをどのくらいの比率でベースモデルに追加するか)辞書の宣言
merging_ratio = {}
for k, v in jp_model.state_dict().items():
# "model.layers.X" の形式でキーを抽出
if "model.layers" in k:
key_base = k.split('.')[0] + '.' + k.split('.')[1] + '.' + k.split('.')[2] # 'model.layers.X' を取得
# 既にそのレイヤーのキーが存在する場合はスキップ
if key_base not in merging_ratio:
# 各レイヤーに対して0から1の範囲でmerging_ratioを提案(負や1以上の値が最適な場合もあるかもしれないが一旦は0.0~1.0とした)
merging_ratio[key_base] = trial.suggest_float(key_base, low=0, high=1, step=0.01)
# modelにchat vectorをlayer毎の割合で付与
model = apply_skill(jp_model, chat_vector, merging_ratio)
model.to(device)
model.eval()
# ELYZA tasks 10の実施とGPT4による評価
list_score = []
for i in tqdm(range(len(data_ten))):
while True:
try:
output_text = pred(model, jp_tokenizer, data_ten[i]["input_ids"])
score = gpt4eval(output_text, data_ten[i]["input"], data_ten[i]["output"], data_ten[i]["eval_aspect"])
if isinstance(score, (int, float)) and score is not None: # scoreがintかfloatの場合のみ処理を行う
list_score.append(score)
break
else:
print(f"Score is NoneType in iteration {i}: {score}")
print("Retrying...")
continue # scoreがintかfloatでない場合はループを継続して再試行
except Exception as e:
print(f"Error occurred in iteration {i}: {e}")
print("Retrying...")
continue
# scoreの平均のマイナスを最小化(最適化)したい値として返す
score = -sum(list_score) / len(list_score)
return scoreこれを複数回呼び出すことによって、最適なmerging_ratioを探していきます。merging_ratioは一旦0.01の精度で探索します。
CmaEsSamplerを用いて進化的アルゴリズムを実行します。n_trialsにて何周最適化を試すか、show_progress_barで進捗バーを表示するかを指定します。
# CmaEsSamplerを用いてStudyを作成
sampler = optuna.samplers.CmaEsSampler()
study = optuna.create_study(sampler=sampler)
# Objective関数を20回試行して最適化
study.optimize(optimize_merging_ratio, n_trials=20, show_progress_bar=True)6. 結果の確認
最適化した加算比率を確認します。結果も連携します。
# 最適化されたパラメータと目的関数の値を取得
best_trial = study.best_trial
print("Best trial:")
print(" Value: ", best_trial.value)
print(" Params: ")
for key, value in best_trial.params.items():
print(f" {key}: {value}")結果ファイルを保存、ダウンロードします。
import json
# best_trialオブジェクトを辞書形式に変換
best_trial_dict = best_trial.__dict__
# 必要な部分のみを抽出し、保存用の辞書を作成
best_trial_to_save = {
'number': best_trial.number,
'value': best_trial.value,
'params': best_trial.params,
'datetime_start': str(best_trial.datetime_start),
'datetime_complete': str(best_trial.datetime_complete),
'duration': str(best_trial.duration),
'state': str(best_trial.state)
}
# JSONファイルに保存
with open('best_trial.json', 'w') as f:
json.dump(best_trial_to_save, f, indent=4)
# 結果のダウンロード
from google.colab import files
files.download('./best_trial.json')scoreの遷移を確認します。
import matplotlib.pyplot as plt
# 各試行の戻り値を取得
values = [trial.value for trial in study.trials]
# 戻り値をプロット
plt.figure(figsize=(10, 5))
plt.plot(values, marker='o')
plt.title('Optimization History')
plt.xlabel('Trial')
plt.ylabel('Objective Value')
plt.grid(True)
plt.show()結果は以下の様になりました。
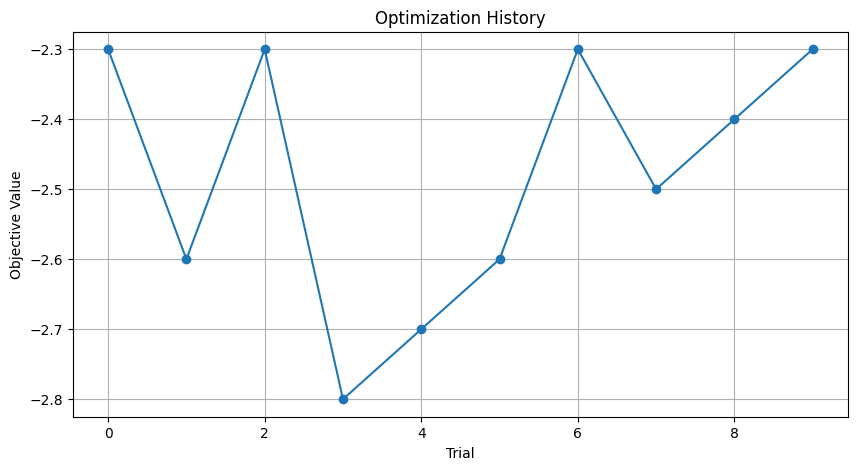
ううむ、微妙。本当はValueが下がっていってほしいのですが、あまり最適化できているように見えません。原因としては
試行回数が少ない
パラメータの次元数が大きい
評価指標が悪い(Elyza Task 10では少ない or GPT4の評価振れなど)
あたりかなと思われます。CmaEsSamplerは最適化するパラメータの100倍ほどの試行回数が必要みたいです。Layerは40くらいなので4000回くらい試行が必要ということになります。そうなるとElyza Taskではコストが厳しいです。Chat能力の最適化にはコストがかかりますね。
7. モデルの保存
最適な加算比率でモデルにChatVectorを加算します。
model = apply_skill(jp_model, chat_vector, best_trial.params)
model_name = "HachiML/Swallow-MS-7b-v0.1-ChatSkill-LAB-Evo-v0.5"
jp_tokenizer.save_pretrained(f"./models/{model_name}", repo_id=model_name, push_to_hub=True)
model.save_pretrained(f"./models/{model_name}", repo_id=model_name, push_to_hub=True)モデルの試し。
prompt = "東京工業大学の主なキャンパスは、"
input_ids = tokenizer.encode(prompt, add_special_tokens=False, return_tensors="pt")
tokens = model.generate(input_ids.to(device=model.device), max_new_tokens=128, temperature=0.99, top_p=0.95, do_sample=True)
out = tokenizer.decode(tokens[0], skip_special_tokens=True)
print(out)東京工業大学の主なキャンパスは、学校のある本館が、東横線・自由が丘駅と大井町線・大岡山駅の中間にあり、そのほか緑が丘駅、大岡山駅方面にそれぞれ研究所が点在しています。本館は、東横線・大井町線の自由が丘駅から徒歩15分程度。大井町線の大岡山駅からは徒歩5分程度なので、アクセス的には大岡山駅の方が便利です。 キャンパスには、各研究所、学生食堂、売店、スポーツ施設があり、敷地面積が
進化的アルゴリズムでの最適化は以上となります。
今回はChat能力を測定する必要があるところに難しさがありました。次はChat Vector以外で試してみたいと思います。
(追加)TPESamplerでの最適化
進化的アルゴリズムを用いたCmaEsSamplerは、多くの次元数のパラメータの最適化に強みを持つ一方、試行回数が少ない場合最適化が遅いことがある様です。なので代わりにTPESamplerでも最適化を実行してみました。コードの修正点はCmaEsSamplerをTPESamplerにするだけです。
# TPESamplerを用いてStudyを作成
sampler = optuna.samplers.TPESampler()
study = optuna.create_study(sampler=sampler)
# Objective関数を20回試行して最適化
study.optimize(optimize_merging_ratio, n_trials=20, show_progress_bar=True)結果は以下のようになりました。何となくスコアが良くなっていっている(下がっていっている)気がします。

参照
この記事が気に入ったらサポートをしてみませんか?