
OpenAI o1を再現しよう(Reasoningモデルの作り方)

はじめに
2024年9月にo1で新しい言語モデルのあり方をOpenAIが示し、注目を集めました。2024年9月にo1-preview、o1-miniが発表され、2024年12月にはo1(-full)とo1-proが公開されました。
さらには2024年12月21日にo3の結果が公開になりこの分野でのさらなる進展が確認できました。(🔗)
いまだにo1, o3のような推論モデル(Reasoning Model)の開発方法は絶対にこれだろう!というものはわかってきてはいませんが、再現を目指す取り組みがちらほら出てきており、モデルの公開もされていたりしています。
上のようにオープンな取り組みをいくつか解説した記事を前回書きましたが、その中でも特に詳細に開発方法が書かれていたMarco-o1のやり方を試してみて実際に数学の推論能力が上がるのを確認するというのが本記事の取り組みです。
コードや、論文に未記載部分についての私の考えによる補足など、なるべく文字に起こせたら良いなと考えています。
1. Marco-o1の概要
まず振り返りですが、Marco-o1では2つのステップでLLMの推論能力を強化していました。
CoTデータセットでの微調整
推論時のMCTS統合
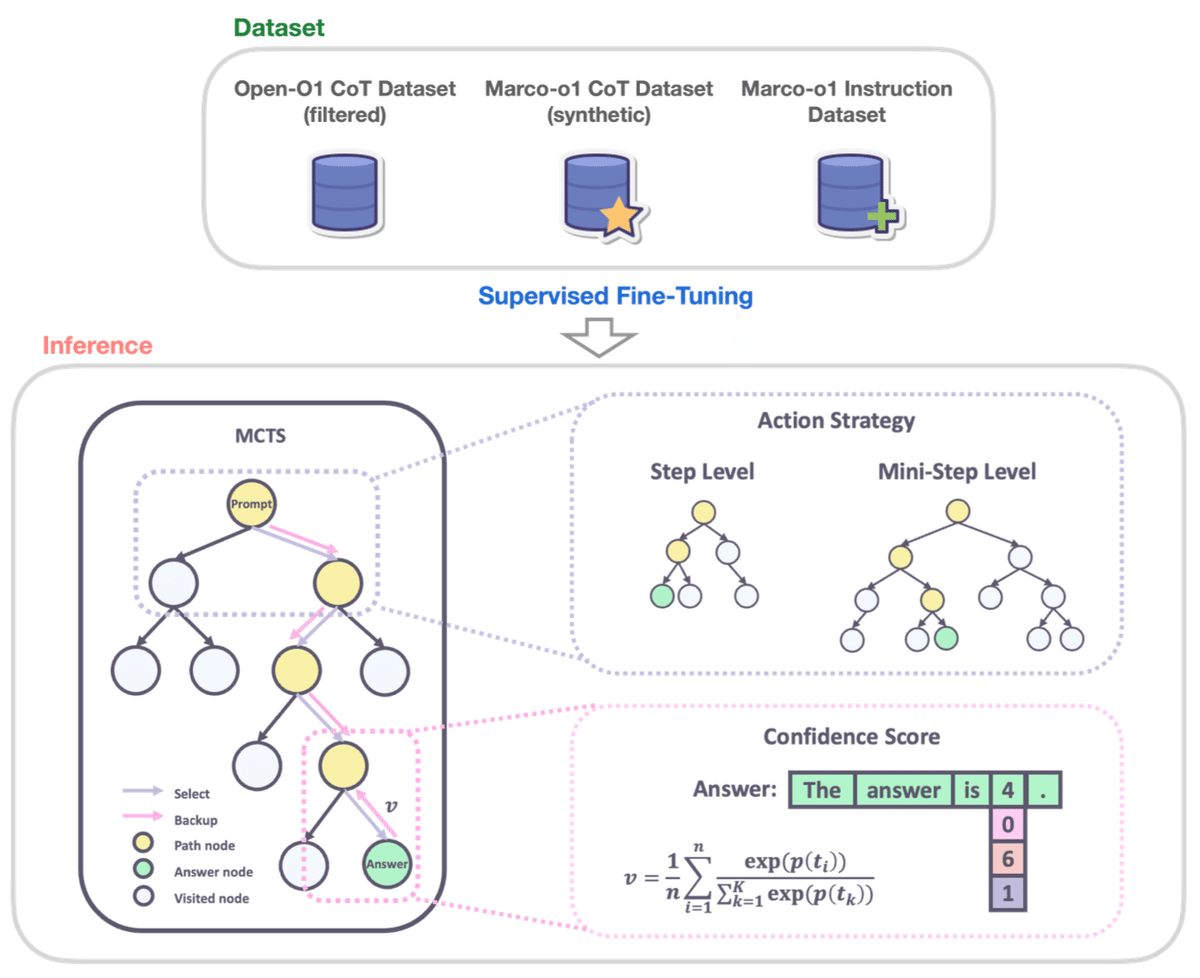
それぞれの概要は上の記事に書いてあります。
本記事では、
ベースモデル:Qwen2.5-0.5B-Instruct
CoTデータ生成用モデル:Qwen2.5-72B-Instruct
CoTデータのベース:OpenMathInstruct-2のmath, augmented_math
評価データ:MGSM-JA(250問)
を使い、上記2ステップをどのように実行したかを残していきます。実行環境は主にGoogle Colabです。
OpenMathInstruct-2には評価に用いるgsm8kの問題が含まれているためこれは除外する必要があります。
2. CoTデータセットでの微調整
2.1 CoT合成データセットの生成
まずは、CoT(Chain of Thought)データセットを作成します。OpenMathInstruct-2の問題をまずQwen2.5-72B-Instructで翻訳します。
OpenMathInstructにはMGSMが含まれます。MGSMは評価に用いるため省いておきます。また、QwenモデルはDeepInfraというサービスを用いました。
import os
from datasets import load_dataset, Dataset
from copy import deepcopy
import re
import time
from openai import OpenAI
from google.colab import userdata
import math
from tqdm.auto import tqdm
import json
# DeepInfra APIの設定
openai = OpenAI(
api_key=userdata.get("DEEPINFRA_API_KEY"),
base_url="https://api.deepinfra.com/v1/openai", # DeepInfraのエンドポイント
)また、今回はあくまで検証であるためデータは1000レコードのみ使用しました。
# データ取得
dataset = load_dataset("nvidia/OpenMathInstruct-2", split="train")
# problem_sourceがaugmented_gsm8kでないものを抽出
filtered_dataset = dataset.filter(lambda x: x["problem_source"] != "augmented_gsm8k")
# 上位1000行のみ使用(必要に応じて変更可能)
filtered_dataset = filtered_dataset.select(range(min(1000, len(filtered_dataset))))日本語訳とCoTデータ保存。
def translate_problem(problem_text):
# Qwen/Qwen2.5-72B-Instructモデルを利用して翻訳
prompt = f"以下を日本語訳してください。\n\n{problem_text}\n\n制約:\n・注釈や説明は不要です。"
response = openai.chat.completions.create(
model="Qwen/Qwen2.5-72B-Instruct",
messages=[{"role": "user", "content": prompt}],
max_tokens=1024,
temperature=0.7
)
return response.choices[0].message.content.strip()
# 新しい列problem_jaを作成
filtered_dataset = filtered_dataset.map(
lambda x: {"problem_ja": translate_problem(x["problem"])},
# batched=False
)
# HuggingFaceへPush
filtered_dataset.push_to_hub("OpenMathInstruct-2-CoT-JA")次に、ステップバイステップの回答をQwen2.5-72B-Instructに生成させます。
最初は問題を元にいきなりステップバイステップの回答を作らせようとしましたが、不正解のケースが多々あったので模範回答も合わせてプロンプトに含めそれをステップバイステップにしてもらうという手法を取りました。
また、ここで推論ステップの区切りとなる"\n\n"を含めてもらいました。
さらには、見直しの癖をつけさせるために「待って間違えたかもしれない。」という文言を必ず含めるように依頼しました。この工夫をMarco-o1ではReflection after Thinkingと呼んでいます。
# データ取得
dataset = load_dataset("HachiML/OpenMathInstruct-2-JA", split="train")
# ステップバイステップの回答を生成する関数
def generate_answer(problem_ja, generated_solution):
# Qwen/Qwen2.5-72B-Instructを使用し、指定されたプロンプトで生成
prompt = f"""数学の問題と模範回答が与えられます。模範回答をステップバイステップの形式に書き換えてください。
# 問題:
{problem_ja}
# 模範回答(英語):
{generated_solution}
# 制約:
・回答は日本語で出力してください。
・推論のステップ毎に"\n\n"で区切ってください。
・途中に必ず「待って間違えたかもしれない。XXの見直しをします。」のようん見直しのステップを含めてください。
・推論毎のタイトルは不要です。
・必ず作成した回答文のみ出力してください。"""
response = openai.chat.completions.create(
model="Qwen/Qwen2.5-72B-Instruct",
messages=[{"role": "user", "content": prompt}],
max_tokens=2048,
temperature=0.7
)
return response.choices[0].message.content.strip()ステップバイステップの回答の生成後には必ず答えが正しいかを確認し、その是非をデータに含めるようにしています。
# 生成された回答から答えを抽出する
def extract_boxed_answer(generated_solution):
import re
start_pattern = r'\\boxed\{'
start_match = re.search(start_pattern, generated_solution)
if not start_match:
return None
start_index = start_match.end()
brace_count = 1
i = start_index
# 括弧の対応をカウントしながら探索
while i < len(generated_solution) and brace_count > 0:
if generated_solution[i] == '{':
brace_count += 1
elif generated_solution[i] == '}':
brace_count -= 1
i += 1
if brace_count != 0:
# 対応する閉じ括弧がない場合
return None
# \boxed{ ... } の中身を抽出
content = generated_solution[start_index:i-1]
# 不要な見た目用コマンドを削除
# たとえば \left, \rightを除去
# 必要に応じてパターンを追加可能
content = re.sub(r'\\(left|right)', '', content)
# 中の空白(スペース、タブ、改行)をすべて削除
content = re.sub(r'\s+', '', content)
return content.strip()
# 回答生成(失敗した場合最大3回まで再実行)
def try_generate_correct_answer(problem_ja, expected_answer, original_generated_solution):
# 最大3回試行し、最後の(3回目)は必ず保存する
max_retry = 3
last_ans = None
for i in range(max_retry):
ans = generate_answer(problem_ja, original_generated_solution)
boxed_val = extract_boxed_answer(ans)
# 中の空白(スペース、タブ、改行)をすべて削除して比較
expected_answer_stripped = None if expected_answer is None else re.sub(r"\s+", "", expected_answer)
boxed_val_stripped = None if boxed_val is None else re.sub(r"\s+", "", boxed_val)
if expected_answer_stripped == boxed_val_stripped:
# 正解が見つかった場合、その時点で返す
return ans, boxed_val, True
last_ans = ans # 正解でなければ次へ
time.sleep(1)
# 3回試行してすべて不一致の場合、最後の回答を返す(不一致だが保存)
return last_ans, extract_boxed_answer(last_ans), False
# 1行ごとの回答生成、確認のフロー
def process_row(example):
problem_ja = example.get("problem_ja", None)
expected_answer = example.get("expected_answer", None)
original_generated_solution = example.get("generated_solution", None)
if original_generated_solution is None or problem_ja is None or expected_answer is None:
# 必要な情報がない場合はNoneを返す
return {"generated_solution_cot": None, "cot_answer": None}
final_ans, final_boxed, correct_flg = try_generate_correct_answer(problem_ja, expected_answer, original_generated_solution)
# final_ans: 最後の回答(成功時は成功回答、失敗時は3回目の回答)
# final_boxed: 最後の回答におけるboxedの中身
return {
"generated_solution_cot": final_ans,
"cot_answer": final_boxed,
"correct_flg": correct_flg
}
# バッチごとに処理し、全データを蓄積しながらプッシュ
def process_dataset_with_batches(dataset, batch_size=100, repo_id="OpenMathInstruct-2-CoT-JA"):
total_batches = math.ceil(len(dataset) / batch_size)
processed_data = []
temp_save_path = "processed_temp.json"
# 中断再開用ローディング
if os.path.exists(temp_save_path):
with open(temp_save_path, "r") as f:
processed_data = json.load(f)
print(f"Loaded {len(processed_data)} previously processed examples.")
start_batch = len(processed_data) // batch_size
for batch_idx in range(start_batch, total_batches):
start_idx = batch_idx * batch_size
end_idx = min((batch_idx + 1) * batch_size, len(dataset))
batch = dataset.select(range(start_idx, end_idx))
print(f"Processing batch {batch_idx + 1}/{total_batches}...")
processed_batch = batch.map(process_row, desc=f"Processing batch {batch_idx + 1}/{total_batches}")
processed_data.extend(processed_batch)
# 中間データ保存
with open(temp_save_path, "w") as f:
json.dump(processed_data, f)
print(f"Pushing batch {batch_idx + 1}/{total_batches} to hub...")
try:
temp_dataset = Dataset.from_list(processed_data)
temp_dataset.push_to_hub(repo_id, commit_message=f"Batch {batch_idx + 1}")
print(f"Batch {batch_idx + 1} pushed successfully!")
except Exception as e:
print(f"Error pushing batch {batch_idx + 1}: {e}")
break
if os.path.exists(temp_save_path):
os.remove(temp_save_path)
print("All batches processed and pushed successfully.")
return Dataset.from_list(processed_data)
# ステップバイステップの回答生成を実行
filtered_dataset = process_dataset_with_batches(dataset, batch_size=10)これによって、以下のデータセットを作りました。最終的には1000レコード中93%が正解、つまり使えるデータになっています。
2.2 CoTデータセットでの微調整
作ったCoTデータセットを使って、Qwen2.5-0.5B-InstructをFull FineTuningします。ステップバイステップでの推論ができれば良いので、適当に2epoch微調整しました。
from datasets import load_dataset, Dataset
# データセット取得
dataset = load_dataset("HachiML/OpenMathInstruct-2-CoT-JA", split="train")ここでCoTの際に用いられる特殊トークン(ThoughtタグとOutputタグ)をTokenizerに追加します。
また、学習データにもこれらタグを追加し、メッセージテンプレートも適用させます。
import torch
from datasets import load_dataset
from transformers import AutoTokenizer, AutoModelForCausalLM
from trl import SFTTrainer, SFTConfig
# モデルとトークナイザのロード
model_name = "Qwen/Qwen2.5-0.5B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
# 追加する特殊トークンを定義
special_tokens = ["<Thought>", "</Thought>", "<Output>", "</Output>"]
tokenizer.add_special_tokens({"additional_special_tokens": special_tokens})
# モデルロード(サイズやGPUメモリにより適宜調整)
model = AutoModelForCausalLM.from_pretrained(model_name, trust_remote_code=True)
model.resize_token_embeddings(len(tokenizer))# データセット読み込み
raw_dataset = load_dataset("HachiML/OpenMathInstruct-2-CoT-JA", split="train")
# correct_flgがTrueのものだけフィルタ
filtered_dataset = raw_dataset.filter(lambda x: x["correct_flg"] == True)
# gsm8kを除外(データ生成の際に除外し忘れていた)
filtered_dataset = filtered_dataset.filter(lambda x: x["problem_source"] != "gsm8k")
# messages列を作成
def create_messages(ex):
prompt = ex["problem_ja"]
generated_solution_cot = ex["generated_solution_cot"]
cot_answer = ex["cot_answer"]
assistant_content = f"<Thought>\n{generated_solution_cot}\n\n</Thought>\n<Output>\n{cot_answer}\n</Output>"
messages = [
{"role": "system", "content": "You are a helpful and harmless assistant. You should think step-by-step."},
{"role": "user", "content": prompt},
{"role": "assistant", "content": assistant_content}
]
return {"messages": messages}
processed_dataset = filtered_dataset.map(
create_messages,
batched=False,
remove_columns=filtered_dataset.column_names
)モデルの学習は以下の条件で行いました。ハイパラはかなり適当です。A100 GPUを使って10分程度で完了します。
new_model_name = "QwQ-CoT-0.5B-JA-v1.1"
train_batch_size = 4
save_steps = 80 / train_batch_size
logging_steps = 80 / train_batch_size
training_args = SFTConfig(
output_dir="./"+new_model_name,
overwrite_output_dir=True,
per_device_train_batch_size=train_batch_size,
gradient_accumulation_steps=1,
learning_rate=1e-5,
lr_scheduler_type="cosine",
num_train_epochs=2,
save_steps=save_steps,
save_total_limit=2,
logging_steps=logging_steps,
bf16=True, # BF16を使用(対応GPUが必要)
report_to="wandb", # wandbへログ送信
max_seq_length=2048
)
# SFTTrainerにmessagesを含むデータセットを直接渡す
# SFTTrainerが内部でapply_chat_templateとトークナイズを行う
trainer = SFTTrainer(
model=model,
args=training_args,
train_dataset=processed_dataset,
tokenizer=tokenizer,
)
trainer.train()
# 学習完了後、モデルをBF16へ変換
model.to(torch.bfloat16)
# 学習完了後Hugging Face Hubにプッシュ
trainer.push_to_hub(new_model_name)最後に、MCTS統合への準備として推論ステップの区切りに用いるトークンをconfigに登録しました。
from transformers import AutoTokenizer, AutoModelForCausalLM
from huggingface_hub import HfApi, Repository
# モデルIDを定義
model_id = "HachiML/QwQ-CoT-0.5B-JA-v1.1"
# トークナイザーとモデルをロード
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype="auto", device_map="auto")
# ステップ区切りトークンIDの準備
step_separators = ["。\n\n", "]\n\n", "\n\n"]
step_separator_ids = [tokenizer.encode(step_separator, add_special_tokens=False)[0] for step_separator in step_separators]
# configにstep_separatorsを追加
model.config.step_separator_ids = step_separator_ids
model.config._name_or_path = model_id
# push
model.push_to_hub(model_id)これによって以下のモデルができました。(モデルカードがそのままなのを許してください。)
2. 推論時のMCTS統合
次に、上記のモデルの推論時にMCTSの推論ステップ探索を統合します。これは学習などでモデルの重みを変更するようなものではなく、推論時のモデルの動きを拡張するコードを外付けで作成する必要があります。
2.1 MCTS(モンテカルロ木探索)とは
そもそもMCTSとはどういうものか振り返ります。(というか私は今回の実装のために勉強しました。)
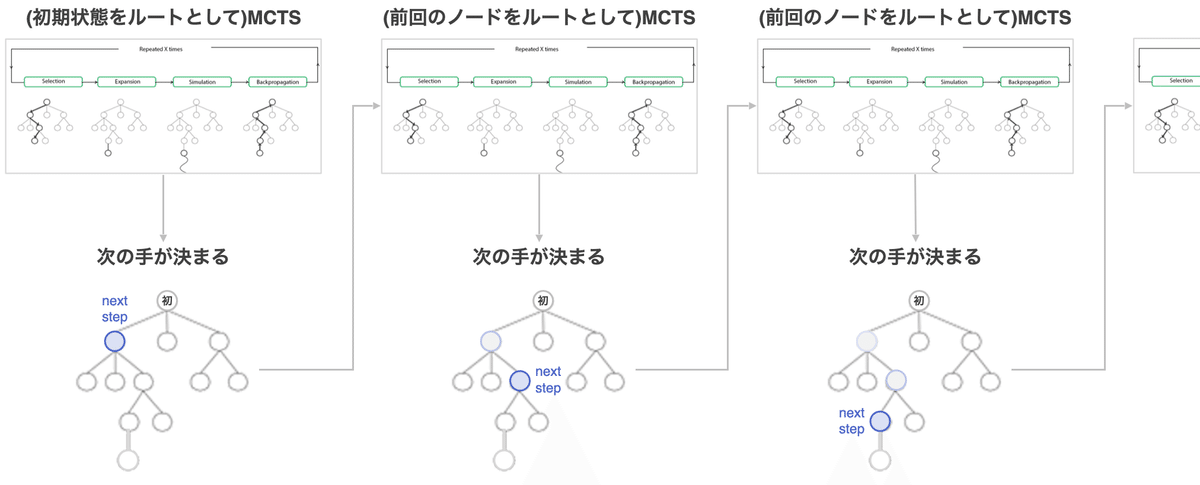
MCTSはAlphaGoなどのゲームによく使われる探索アルゴリズムのようです。以下のように選択→拡張→シミュレーション→逆伝播という流れを指定回数繰り返し、有望な次の一手を決定します。
ルートノードが現在の状態を表し、それ以降のノードが以降の手を表します。

選択(Selection):ルートノードから、葉ノードまで辿り着くまで探索を行う。選択のルールはいくつかあるが、UCB1を用いることが多い。
拡張(Expansion):選択で選ばれた葉ノードから、(訪問回数が一定以上の場合)新しいノードを生成する。訪問回数の制限や生成するノード数は戦略次第で変更となる。
シミュレーション(Simulation):新しいノードからシミュレーションを行い、勝敗を報酬値として取得。
逆伝播(Backpropagation):新しいノードの報酬値をルートノードへと伝播させる。
次の手が決まったら、その手(そのノード)を次のルートノードとして次の一手を決定しこれを繰り返すことで終局に向かっていきます。(相手番は考えないものとする。)
2.2 MCTSの統合
これを踏まえて、LLM向けにMCTSを以下のような内容にしました。初期ルートノードが与えられたプロンプトを表し、以降の各ノードが各推論ステップになります。
選択(Selection):ルートノードから、葉ノードまで辿り着くまで探索を行う。選択のルールはいくつかあるが、今回はUCB1を用いた。
拡張(Expansion):選択で選ばれた葉ノードから、訪問回数1回以上のとき新しいノードを生成するとした。また、生成するノード数は2つ。
シミュレーション(Simulation):Marco-o1の手法にならい、トークンの生成確率を使用して評価。
逆伝播(Backpropagation):新しいノードの報酬値をルートノードへと伝播させる。
UCB1とは、未知のルートの探索と現状成果の高いルートの活用のバランスをとるための選択方法の1つで以下で計算されます。
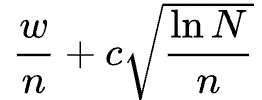
LLM推論へのMCTS統合においては、wはそのノードのvalue_sum(これまでの探索における報酬スコアの合計)、nはそのノードのvisit_count(訪問回数)、cは√2、Nはルートノードの訪問回数となります。
では、報酬スコアはどう計算するでしょうか。これは前回の記事にも書きましたが、各トークンの確率(対数確率)を元にします。各推論ステップで生成されたトークンだけでなく、その時の予測された上位5位までの対数確率を使用します。これを元に、まず信頼スコアを計算します。

それを元に、報酬スコアを計算します。

Transformersライブラリを拡張し、LLMの推論時にMCTSを行うようにしたライブラリを以下に公開しました。(3分クッキング感)
GithubのReadmeを見ていただければわかりますが、TransformersライブラリのAutoModelForCausalLMと同じように使用できるようになっています。
# モジュールのインポート
from reasoning_model import ReasoningModelForCausalLM
from tree_utils import print_tree_with_best_path
from transformers import AutoTokenizer
# tokenizerとmodelの準備
model_name = "HachiML/QwQ-CoT-0.5B-JA-v1.1"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = ReasoningModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
system_prompt = "You are a helpful and harmless assistant. You should think step-by-step." # 固定を推奨
prompt = "231 + 65*6 = ?"
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": prompt}
]
# chat_templateとtokenize
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# MCTSを用いて生成(Google ColabのT4インスタンスで1分程度かかる)
final_tokens, final_node = model.generate(
**model_inputs,
iterations_per_step=5, # 1推論ステップの探索に何回シミュレーションを行うか。長いほど精度が高まる可能性はあるが、推論時間が伸びる。
max_iterations=15, # 推論ステップの上限: 0.5Bモデルの場合、そこまで長いステップの推論はできないため10~15くらいが妥当。
mini_step_size=32, # mini-step: 32tokens。Step as Action戦略を採用する場合、ここを512など大きな数字にする。(実行時間が伸びるため非推奨)
expand_threshold=0, # ノードを拡張するために必要なそのノードの訪問回数の閾値。デフォルトの0で、拡張には1回以上の訪問が求められる。基本デフォルトで良い。
step_separator_ids=None, # Reasoning Action StrategyでStep as Actionを採用するときの区切りとなるトークンのIDリスト。NoneでモデルConfigの値を利用するため、変更は非推奨。Step as Action不採用時には[]を設定する。
)
# 結果をテキスト化
final_text = tokenizer.decode(final_tokens, skip_special_tokens=True)
print("=== 最終生成テキスト ===")
print(final_text)generate時にいくつかMCTSのための引数を与えられるようになっています。(2024/12/18時点)
iterations_per_step:推論ステップを1つ決定するのに何回の探索を行うか
max_iterations:最終生成結果として、生成する最大推論ステップ数
expand_threshold:ノード拡張に必要なノードの訪問回数閾値
また、Reasoning Action Strategyのための引数として以下を設定可能です。
step_separator_ids:Step as Actionを採用するときの区切りとなるトークンのIDリスト
mini_step_size:Mini-step as Actionを採用するときのミニステップのトークン数
step_separator_idsに["\n"]などを設定し、mini_step_sizeを大きい値(512 など)設定するとStep as Actionが実行されます。
逆にstep_separator_ids=[]、mini_step_size=32や64を設定するとmini-stepで推論ステップが区切られます。
3. 評価
3.1 評価方法
日本語の数学推論のデータセットMGSM-JA(250問)を使って、CoT微調整・MCTS統合の結果、推論能力が向上しているかどうかを確認していきます。
評価もGoogle Colabを使って行いました。
確認のためのコードは先ほどのライブラリに含まれているのでそれを使っていきます。(🔗)
準備
# GitHubリポジトリからクローン
!git clone https://github.com/Hajime-Y/reasoning-model.git
%cd reasoning-model
# 必要なライブラリをpipインストール
!pip install transformers torch numpy datasets
# Pythonパスにカレントディレクトリを追加
import sys
sys.path.append('.') # reasoning_model.py と同じディレクトリにいるため評価
from reasoning_model import ReasoningModelForCausalLM
from tree_utils import print_tree_with_best_path
from evaluate.evaluate_mgsm import evaluate_model_on_mgsm
from transformers import AutoTokenizer
MODEL_NAME = "HachiML/QwQ-CoT-0.5B-JA-v1.1"
# 設定
iterations_per_step = 5
max_iterations = 15
mini_step_size = 32
expand_threshold = 0
step_separator_ids = None
system_prompt = "You are a helpful and harmless assistant. You should think step-by-step."
repo_id = f"mgsm_250-{MODEL_NAME.split('/')[-1]}-MCTS-ips{iterations_per_step}-mi{max_iterations}-mss{mini_step_size}-et{expand_threshold}"
if step_separator_ids is None:
repo_id += "-sa"
# 評価の実行
results_dataset, metrics = evaluate_model_on_mgsm(
model_name=MODEL_NAME,
repo_id=repo_id,
iterations_per_step=iterations_per_step,
max_iterations=max_iterations,
mini_step_size=mini_step_size,
expand_threshold=expand_threshold,
step_separator_ids=step_separator_ids,
system_prompt=system_prompt
)max_iterations=15, expand_threshold=0に固定として、他パラメータを何パターンか試してみました。
3.2 推論能力向上の確認
ひとまず、mini-stepを採用してmini_step_size=64, step_separator_ids=[]としたときの結果は以下のとおりです。
ある理由からMCTSの結果は3回評価した結果の平均を記載しています。(後述)

CoTモデル単体と比較して+104%、Qwenと比較して+410%正答数が増加しました。
3.3 最適なReasoning Action Strategyの確認
次に、推論ステップを区切る方法でスコアがどの程度変わるか、どの方法が区切り方として良いかを確認しました。確認した条件は以下のとおりです。
Mini-step (64 tokens): mini_step_size=64, step_separator_ids=[]
Mini-step (32 tokens): mini_step_size=32, step_separator_ids=[]
Step & Mini-step (64 tokens): mini_step_size=64, step_separator_ids=None
Step & Mini-step (32 tokens): mini_step_size=32, step_separator_ids=None
Mini-stepと書かれているのがトークン長で区切る方法、Stepと書かれているのが事前に設定してある区切りトークンが生成されたら区切るという方法です。Step & Mini-stepはトークン長と区切りトークンの両方で区切る戦略であり、これはMarco-o1の論文では実験されていませんでしたが追加してみました。(step_separator_ids=Noneとするとモデルconfigに設定されているstep_separator_idsが使用される。)
結果は以下の通りです。Google ColabのT4インスタンスでの250問の回答時間も記載してあります。
また、ある理由からMCTSの結果は3回評価した結果の平均を記載しています。(後述)

Step & Mini-step (32 tokens)を採用したMCTS統合した推論では平均して32.3問正解し、CoTモデル単体と比較して+115%、Qwenと比較して+438%正答数が増加しました。
また、回答時間としては1問当たり大体1分弱でしたが、mini-step (64 tokens)が比較的短かったです。
ここからは私の想像も入りますが、
mini-step(64 tokens)の回答時間が短いのは、1推論ステップが長くなったことによって推論ステップ数自体が短くなったことが要因
区切りトークンの使用は推論に悪影響を及ぼさないため使って良さそう
が言えるんじゃないかと考えます。一方で、なぜ区切りトークンの使用有無で、mini-stepのトークン数での正答数の良し悪しが逆転するのかはよくわかりませんでした。
ともあれ、step & mini-step (32 tokens)が良さそうとわかりました。
ただし、論文でも指摘されていますが、最適なアクションの粒度は問題の複雑さに依存するようです。
3.3 安定性の確認
最後にMCTS統合の評価を複数回行った理由をお話しします。

上記は先ほどのスコアの3回評価結果の内訳になります。
かなりスコアのぶれがあることがわかります。特にstep & mini-step (32 tokens)は最小27、最大41と1.5倍近い差ができています。
Marco-o1の論文でもこの問題は以下のように指摘されています。
信頼スコアを報酬として使用しているため、ツリー検索の結果は大幅なランダム性を示します。
この大幅なランダム性というのが上記の結果に表れているのだと思います。
論文ではこの不安定性の改善のため、今後は結果報酬モデリング(ORM)とプロセス報酬モデリング(PRM)を通じてMCTSの報酬シグナルを改良することを目指すと締められています。
4. さらにその先へ
モデルの推論ロジックにMCTSを統合することでかなり推論能力がわかりました。一方で、報酬スコアによる不安定性など課題があり、まだまだ伸び代がありそうです。
おそらくこの後はORMやPRMによる報酬スコアの改善→強化学習という流れになるのかなと思います。
Google DeepMindのReasoningチームリーダーのDenny Zhou氏はXで「Tree Searchは検索であって推論ではない。我々推論チームは、結成時から検索に頼らない推論を目指してきた。」と述べています。(🔗)
強化学習によってMCTSのような探索アルゴリズムを使わない方向に行くのでしょうか。手法は分かりませんが、やはりその先があるようです。
まとめ
CoTデータセットの作成・微調整からMCTS統合までを小さいモデル(0.5B)で試してきました。結果として、
元モデル→CoTモデル→MCTS統合 で推論能力が向上
推論ステップの区切りは、トークン長32 + 区切りトークンの併用が一旦は良さそう
ということを確認できました。思ったよりも推論能力が向上したことに正直驚きました。
手前味噌ながらなかなか良いライブラリが作れたと思います。探索方法としてMCTS以外も追加していけたらと思っています!何か気になる点があればIssueやContributeお願いいたします。
一方で、一部説明ができないところもあったり、またTest Time Scalingをもう少し詳細に確認してみたいなと思っているので気が向いたら調べてみようと思います。
また、ORM/PRMや強化学習の方も試してみたいと考えています。
あと、LLMとは関係ないですが、モンテカルロ木探索について勉強するのに使った以下書籍が面白かったのでぜひ読んでみてください。
議論やツッコミがあればNoteやX(Twitter)でコメント・ご教示いただけると助かります。
X: https://twitter.com/CurveWeb
お読みいただきありがとうございました。検証部分が書けたらXでお知らせしようと思うので良ければフォローお願いいたします。