
論文メモ: Self-Rewarding Language Models

私は最近、LLMによるSynthetic data(合成データ)生成を試しています。手法について色々調べているので論文等忘れないようにこの場にメモを残していきたいと思います。
基本的に、『Synthetic dataをどう作るか』によったメモとなるので、その論文中の結果等は書かなかったりすると思います。
また、内容には私、GPT、Claudeの見解を含みます。
1. 今回の論文
今回は以下の論文を読みました。Metaによる論文です。
まとめるとこんな感じの内容でした。
強化するモデル自身を報酬モデルとしても扱う自己改善手法 Self-Rewarding
oasstを使って作った計5,000 records程のデータセットを使用
学習を重ねる毎にInstructionモデルとしての能力・報酬モデルとしての能力の両方が向上することを期待
LLMによるSynthetic dataの利用は大きく分けて「蒸留」と「自己改善」があり、今回は自己改善手法です。
2. データ準備

データについて
oasst(Open Assistant)元に、IFT(Instruction Fine-Tuning data)を3,200 records、EFT(Evaluation Fine-Tuning data)をtrain 1,630 records, test 531 records作成
oasstのバージョンは明言されていないが、参照論文からおそらく1
データ作成手法について
IFTのFiltering: rank 0のFirst conversational TurnのQAペアを選定
EFTではまず、oasstの各QAに対してLLM-as-a-Judge(強化したいモデルM0 = Llama-70B 使用)
EFTのFiltering: oasstの各QAに対し元々ついているrankの順位と、LLM-as-a-Judgeのscoreでの順位が一致したQAを選択。このQAとscoreの組みがEFTとなる。
EFTはFirst Turnのみという言及はないが、用途からFirst Turnに選定するのが妥当そう。
3. 手法
3-1. モデル準備(iter.0)
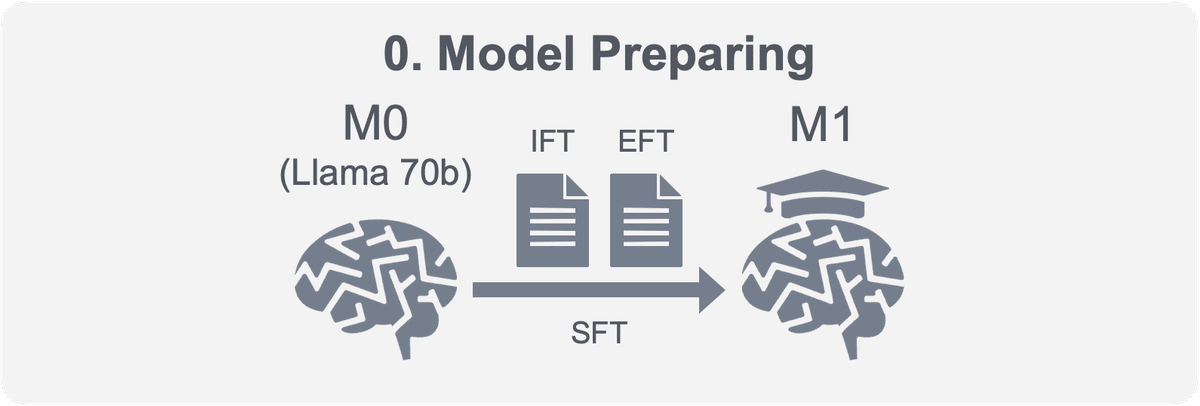
oasstから作成したIFT/EFTを使ってLlama 70bをSFTして、モデルM1を作成する。
3-2. 流れ(iter.1~)
以下のような流れを繰り返します。

Self-Instructについて
Self-Instructの8-shotは6-shotがIFTから、2-shotがmodel generated dataからとある。詳細はないが、前のiterationでモデルMt-1が生成したQA pairを使用すると思われる。最初のiterationではこのデータがないので8-shot IFTとすることになるはず。また、おそらくscoreが高いQA pairを使用するのが有効と考えられる。
Self-Instructでは、固定でLlama2-70b-Chat(固定)をInstructionの生成に使用。(Self-Instructでは通常Instruction,Input, Outputを1度に生成するが、ここでのOutputはおそらく捨てる。)
Output(Response)は強化したいモデルMtを使用して生成する。
LLM-as-a-Judgeについて
LLM-as-a-Judgeには後述のPrompt・強化したいモデルMtを使用。
AIFT(AI Feedback Tuning data)はLLM-as-a-Judgeの結果のScoreとその元となったQA pairから作成。おそらく、QA pairからLLM-as-a-JudgeのPromptを使って作ったテキストがInstructionになり、Score(+Reason)がOutputとなる。
AIFT(M1) 3964 records, AIFT(M2) 6942 records
3-3. Prompt
LLM-as-a-JudgeのPrompt(日本語訳)は以下の通りです。これを、EFT/AIFTデータ作成の際に用います。
ユーザーの質問と対応する回答を、以下に説明する5点満点の加点方式で確認する。加点は、各基準の満足度に基づいて累積されます:
- 回答が不完全であったり、無関係な内容を含んでいても、関連性があり、ユーザーの問い合わせに関連する情報を提供している場合、1点を加算します。
- 回答がユーザーの質問のかなりの部分に対応しているが、問い合わせを完全に解決していない、または直接的な回答を提供していない場合、もう1点を加算する。
- AIアシスタントが書いたと思われる回答や、ブログや検索結果でよく見られる要素を含む回答であるかどうかにかかわらず、ユーザーの質問の基本的な要素に有用な方法で回答している場合、3点目を付与する。
- 回答がAIアシスタントの視点から明確に書かれており、ユーザーの質問に直接的かつ包括的に対処しており、明瞭さ、簡潔さ、焦点の絞り方に若干の改善の余地があるとしても、よく整理された有益なものであれば、4点目を与える。
- AIアシスタントがユーザーの質問に完璧に合わせ、余計な情報がなく、専門的な知識を反映し、質の高い、魅力的で洞察に満ちた回答を示した回答に5点目を与えます。
User: <INSTRUCTION_HERE>
<response><RESPONSE_HERE></response>
ユーザーの指示と回答を検証した後、次のことを行ってください:
- 100字以内で、あなたの合計得点を簡単に正当化してください。
- スコアは以下のフォーマットで記入してください:"Score: <total points>"
必要に応じてウェブ検索の知識を活用しながら、AIアシスタントの視点から評価することを忘れないでください。この加点モデルに沿って回答を評価するために、概略の基準に基づいて体系的に点数を付けます。3-4. 利用モデル整理
複数箇所モデルを利用する工程が出てきたので、利用するモデル/対象となるモデルを整理します。

Llama2 70Bの事前学習モデルがSelf-Rewardingで強化されていき、Iteration毎にM1から順番に名前が振られます。
例えば、私がやるとすると左のモデルはMistral-7B、右のモデルがMixtral-8x22B-Instructとかを使うと良いかなと考えます。
4. まとめ
使いやすい点:
✅ GPT-4のような高性能なモデルは利用しなくて良い。(Self-Instructでより良いInstructionを生成することを考えると、ここのモデルの性能は高いほど良いとは思うが必須ではない。)
✅ 用意するデータが比較的少ない。(5,000 records程度)
✅ 各Iterationで生成する合成データも比較的少ない。(4,000-7,000 records程度)
使いにくい点:
✅ Llama2 70Bでの成果となっており、7B paramsサイズのモデルでも効果があるのかが不明。命令追従能力と評価能力の両方が向上する必要がある。