
LLMによる合成データ(Synthetic Data)生成のテクニック

私は最近、LLMによるSynthetic data(合成データ)生成を試しています。手法について色々調べたり試したことをまとめておこうと思います。
個別の論文の詳細については他の方の記事や私の過去記事でまとめたりしてあるので、どちらかというと合成データ生成における方向性にどんなものがあるのかという観点で紹介したいと思います。
概要
LLMによる合成データ生成には、その使い道から以下の2つの種類があります。
蒸留 (Distillation)
自己改善 (Self-improvement)

[蒸留]
こちらはとてもわかりやすく、よりパラメータ数が大きく能力が高いと言われているLLMを使って合成データを作る手法です。より人間が作成したデータに近い合成データで、例えば7Bのモデルを学習させることでモデルの性能を引き上げることができます。
[自己改善]
強化したいモデル自身でデータセットを作成し、そのデータセットで自分自身を強化します。
そのモデルよりサイズの大きいモデルがない(もしくはライセンス的に使えない)ようなモデルの学習に使われることが多いです。例えば70Bのモデルなどに使われます。
今回は蒸留を中心に、何パターンかのテクニックを簡単にご紹介します。
1. 蒸留(Distillation)
まず、蒸留のテクニックから5パターン紹介します。1~3は同系列の生成方法で、4,5はそこから少し外れた手法です。
合成データ生成の基本形(Self-Instruct)
より難易度の高いデータセット生成(Evol-Instruct)
より多様性に富んだデータセット生成(LAB)
既にプロンプト・回答のあるタスクの質の良い解法を生成(OpenMathInstruct)
知識に特化したQAを作らせる
1. 1 合成データ生成の基本形(Self-Instruct)
まずは原初とも言えそうなself-instructの手法を元に、LLMによる合成データ生成の外形についてです。
Self-Instructの手順は論文を参照すると以下の通りです。
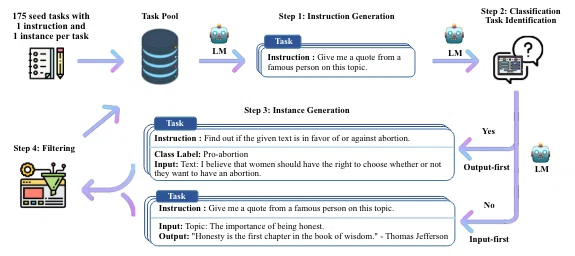
seed taskと呼ばれる人間が作成したデータを元に、「こんな感じでLLMに与えるタスクを生成して」とLLMに投げることで、データセットを生成していくというのが基本の流れになります。
このseed taskにはinstruction(指示), input(入力), output(出力)の組になっており例えば以下のようなものが含まれます。
{
"instruction": "方程式を解き、Xの値を求めなさい。",
"input": "10X + 5 = 10",
"output": "10X = 5\nX = 0.5",
}以下のようなプロンプトを、このseed taskをいくつか例として一緒にLLMに投げることで、続きの(以下だと4つ目以降の)タスクを生成させます。
あなたには、10の多様なタスク指示のセットを考えてもらいます。これらのタスク指示はLLMに与えられ、我々はその指示を完了したLLMを評価します。
以下がその条件です。:
1. 多様性を最大化するために、各指示について動詞を繰り返さないようにしてください。
2. 指示に使われる言葉も多様であるべきです。例えば、質問と命令形を組み合わせます。
3. 指示の種類も多様であるべきです。リストには、自由形式の生成、分類、編集など、多様なタイプのタスクを含めるべきです。
2. LLMは、命令を完了できなければなりません。例えば、アシスタントに視覚的または音声的な出力を作成するよう求めてはなりません。別の例では、午後5時にあなたを起こしたり、リマインダーを設定するようにアシスタントに依頼してはいけません。
3. 指示は日本語で書いてください。
4. 指示は1~2文の長さであること。命令文でも疑問文でも構いません。
5. 指示に対して適切な入力を生成すること。入力フィールドには、指示のために提供された具体的な例が含まれていなければなりません。現実的なデータを含むべきで、単純なプレースホルダーを含んではいけません。入力は、指示をやりがいのあるものにするために実質的な内容を提供する必要がありますが、理想的には100語を超えないようにしてください。
6. すべての指示に入力が必要なわけではありません。例えば、「世界で最も高い山はどこか」というような一般的な情報を尋ねる指示の場合、具体的な文脈を提供する必要はありません。この場合、入力フィールドに"<noinput>"と書くだけでよいです。
7. 出力は指示と入力に対する適切な応答でなければなりません。出力は100語以内にしてください。
10のタスクのリスト:
{seed task 1}
{seed task 2}
{seed task 3}蒸留における合成データ生成は基本的にこの手法を発展させたものが多いです。
1.2 より難易度の高いデータセット生成(Evol-Instruct)
Self-Instructはデータセット生成に効果的でしたが、タスクの難易度・複雑さが元のseed tasksに近いという点で使いづらさがあります。より難しい問題でLLMをTuningさせたいとき、人手で複雑で難易度の高いseed tasksを作成する必要がありますが、これにはコストがかかります。
また、そもそも難易度の高いタスクをseed taskとして与えても、プロンプト(instruction+input)と回答(output)を同時に生成させるSelf-Instructでは高い難易度のタスクをきちんと生成できない可能性があります。
そこで、2つの工夫を採用します。
① プロンプトと回答の生成タイミングを分ける
② プロンプトの難易度を少しだけ上げるという工程を入れる
この「プロンプトの難易度を上げる」という工程を複数回繰り返すことで、seed taskの難易度が低くてもより難しいタスクを生成することができます。
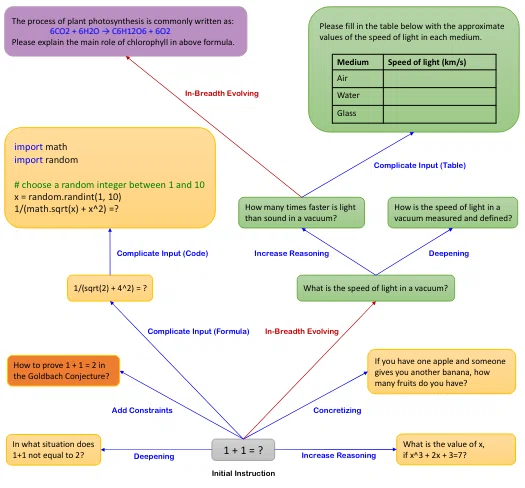
「プロンプトの難易度を上げる」というのももちろんLLMに行わせます。難易度の上げ方には「制約の追加」「質問文の深さ(幅)の増加」「概念の具体化」「推論ステップの要求」など複数あります。例えば、「制約の追加」は以下のようなプロンプトを用います。
プロンプト・リライターとして活動してほしい。\n \
あなたの目的は、与えられたプロンプトをより複雑なバージョンに書き換えて、有名なAIシステム(例:chatgptやGPT4)を少し扱いにくくすることだ。\n \
しかし、書き換えられたプロンプトは合理的でなければならず、人間が簡単に理解し応答できなければならない。また、日本語でなければならない。\n \
あなたの書き換えでは、#The Given Prompt#の表やコードなど、テキスト以外の部分を省略することはできません。また、#The Given Prompt#の入力も省略しないでください。 \n \
与えられたプロンプトを以下の方法で複雑にする必要があります: \n\
#The Given Prompt#にもう1つ制約/要件を追加してください。 \n\
#Rewritten Prompt#が冗長にならないように努力すること。#Rewritten Prompt#は#The Given Prompt#に10語から20語程度しか追加できません。英語ではなく自然な日本語表現で書いてください。 \n\
'#The Given Prompt#'と'#Rewritten Prompt#'、'given prompt'、'rewritten prompt'には#Rewritten Prompt#を含めることができない。\n
#The Given Prompt#: \n {} \n
#Rewritten Prompt#:\nこれによって、LLMは#The Given Prompt#に何らかの制約を追加した#Rewritten Prompt#を生成します。その後、難易度の上がったプロンプトをそのままLLMに投げることで、Answerを生成します。
このような手法により、より難易度の高いタスクを合成データとして生成できるようになります。
1.3 より多様性に富んだデータセット生成(LAB)
次に、タスクの多様性の確保についてです。
Self-Instructはデータセット生成に効果的でしたが、生成されるタスクの種類が、seed taskの分布の偏り・LLMの出力のしやすさによる偏りという2点によって偏るようです。
あらゆるタスクに対して偏りが少ないデータセットが、(少なくともInstruction Tuningにおいては)有用なようです。
これに対して、以下2つの工夫を採用します。
① あらかじめタスクを分類しておく(できれば階層的に)
② 各回に与えるタスク例を、1つのタスク分類のタスクのみとする
これによって生成するタスクの種類とその数をコントロールすることができ、タスクの多様性を確保することができます。
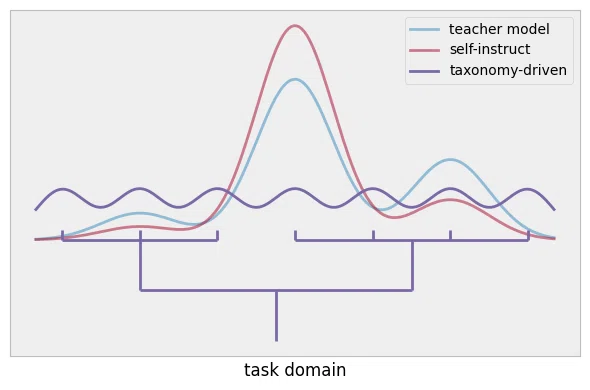
self-instructよりも多様なものにできるというイメージ
LAB(LARGE-SCALE ALIGNMENT FOR CHATBOTS)では分類を階層的に詳細に作成しています。例えば、階層の一番上の分類としてはKnowledge TuningとSkill Tuningです。妥当な気がします。
プロンプトはSelf-Instructのままでよく、コードもSelf-Instructのうち例を選ぶところのロジックだけ修正するだけで良いのが良いところです。
1.4 既にプロンプト・回答のあるタスクの質の良い解法を生成(OpenMathInstruct)
Self-Instructとは異なり、
・既にプロンプトと明確な回答があり
・そこそこ数が揃っている
タスクに対して、質の良い解法を生成することでTuningデータセットにするという方法があります。
OpenMathInstructでは、MATH/GSM8Kという数学のベンチマークのTrainデータを使っています。ベンチマークのデータなので問題と答えが揃っています。これに対して、LLMでPythonを使って解く解法を生成することで、問題・解法・答えの揃ったデータセットを作成しています。
Mixtralを使って作成していますが、Mixtralであってもこの問題を100点満点で解くことは難しいため、以下の工夫を採用しています。
① とにかくたくさん解かせて、正解した回答を採用
具体的には1つの問題に対して、MATHで224回、GSM8Kで128回解かせることで、MATHで80.1%、GSM8Kで99.1%のタスクの解法の作成に成功しています。
このように、既にプロンプト(問題)と答えのみある場合、解法を生成するという手法を採用できます。
1.5 知識に特化したQAを作らせる
また、seed taskとしてWiki, Common Crawlなどのテキストとして与え、そのテキストに関するQAを作成させるという手法もあるようです。
LABでいうKnowledge Tuningに特化した生成方法になるのでしょうか。
東工大さんでも似たようなことを実施しているようです。(関連ポスト)
2. 自己改善 (Self-Improvement)
自己改善についても少しだけ触れておきます。
自己改善は、強化したいモデル自身にInstruction Tuning, Preference Tuningデータを作成させるという手法です。とはいえ、単にそのモデルにデータを作らせても、蒸留のようにモデルをより賢くするデータセットを作れるわけではないという問題があります。そこをどう良いデータセットにするかが自己改善の鍵になります。
これに関して、以下のような工夫で対応していました。ReSTEMに関してはOpenMathInstructと似たようなアプローチです。
正解のあるタスクに対して、複数回解かせることでたまたま解けたその解法をデータセットとする。(ReSTEM)
正解のないタスクに対して、複数回回答を作成し自分自身で評価させる。(Self-Rewarding)
自己改善は基本的に複数回同一の問題に対して解かせるのが基本な気がします。自分自身とアンサンブルさせて擬似的に性能が上がった振る舞いができる → 作ったデータで学習 という流れなのかもしれません。
また、Self-Rewardingについては、おそらくタスクの難易度が、「タスクを考える」>「タスクの評価をする」であることが前提になっているような気がします。
序盤にも書きましたが、そもそも自己改善に関してはそのモデルよりサイズの大きいモデルがない(もしくはライセンス的に使えない)ようなモデルの学習に使われることが多いです。
なので、この辺りを研究しているのはMetaやGoogleなど先端モデルを作ろうとしている企業が多い気がします。
Self-Rewardingを試してみましたが、MixtralなどのAPIを叩いて蒸留する方が自己改善よりもコスパが良いと感じました。
まとめ
LLMによる合成データ生成のテクニックとして採用されている手法をいくつか紹介させていただきました。
蒸留では特に、
① 難易度の調整(Evol-Instruct)
② 多様性の確保(LAB)
あたりを(これらの手法に限らず)コントロールしていくことが良い生成データセットの鍵になりそうだなと思います。
どのあたりが手法の肝かというところを中心にまとめたので、語りきれていない場所等あると思います。その辺りは大元の論文をご参照ください。
Self-InstructとEvol-Instructに関しては日本語で使えるようなコードを作ってみているのでこちらもご参照いただければ幸いです。
また、自己改善手法のReSTEMとSelf-Rewardingに関しては、過去記事にももう少し詳しく書いています。
参照
この記事が気に入ったらサポートをしてみませんか?