YouTubeライブに寄せられたライブチャットをエクセルに落としてみる

こんばんは。立憲民主党所属の米山隆一さんに、Xで政策の質問をしたら、謎にブロックをされた破綻国家研究所です。本業はデータサイエンティストで飯を食ってます。
はじめに
11/2のたまきチャンネルのライブを見ていたら、スパチャをはじめ各コメントに
実現してほしいこと、政策への質問
など大量の陳情で溢れていました。
1時間のライブではすべて追いきれないし、
流れも速くて追いかけるのに苦労しそうなので、
コメントをエクセルに抽出してみようかなと思ったんですね。
ただ、YouTubeのチャットのリプレイからコメントを取ってくるなんて実は今までやったことないです。
なので寝る間を惜しんで調べながら、4時間コーディングしました。
目的
YouTubeライブでのコメントを拾い上げる。
分かりやすいようにエクセルに書き起こす。
コードと抽出結果
上がコードで下が抽出結果です
環境
Jupyter notebook (Python3, ipykernel) WinPython
yt-dlpのためYouTube APIは不使用。
コード解説
pip install yt-dlpは最新にしておいてください
pip install yt-dlp
!pip install -U yt-dlp今回使うモジュールです
from yt_dlp import YoutubeDL
from tqdm import tqdm
import os
import time
import json
from openpyxl import Workbookvideo_url = ' ここに調べたいライブのURLを貼る '
video_url = 'https://www.youtube.com/watch?v=SsCkhaxAIZg'
video_id = video_url.split('=')[-1]
json_file = f'{video_id}.live_chat.json'JSON形式での保存とのことなので、.json形式でダウンロードします。
class TqdmProgress:
def __init__(self):
self.pbar = tqdm(unit='B', unit_scale=True, desc="Downloading chat data", dynamic_ncols=True)
def hook(self, d):
if d['status'] == 'downloading':
downloaded = d.get('downloaded_bytes', 0)
self.pbar.update(downloaded - self.pbar.n)
elif d['status'] == 'finished':
self.pbar.close()
def download_chat_replay():
retries = 5 # 最大再試行回数
for attempt in range(retries):
progress = TqdmProgress()
ydl_opts = {
'outtmpl': f'{video_id}.%(ext)s',
'writesubtitles': True,
'skip_download': True,
'subtitlesformat': 'json',
'subtitleslangs': ['live_chat'],
'progress_hooks': [progress.hook]
}
with YoutubeDL(ydl_opts) as ydl:
ydl.download([video_url])
if os.path.exists(json_file) and check_data_completeness(json_file):
print(f"チャットデータが正常にダウンロードされ、{json_file} に保存されました。")
return
else:
print(f"ダウンロードが不完全です。再試行 {attempt + 1}/{retries}...")
time.sleep(5) # 次の再試行まで待機
print("再試行が上限に達しました。データが完全ではない可能性があります。")
def check_data_completeness(file_path):
try:
with open(file_path, 'r', encoding='utf-8') as f:
data = json.load(f)
# チャットデータがある程度の件数(例: 100件)以上か確認
return len(data) > 100
except json.JSONDecodeError:
print("JSONファイルの解析に失敗しました。")
return False
download_chat_replay()
これでダウンロードできました。
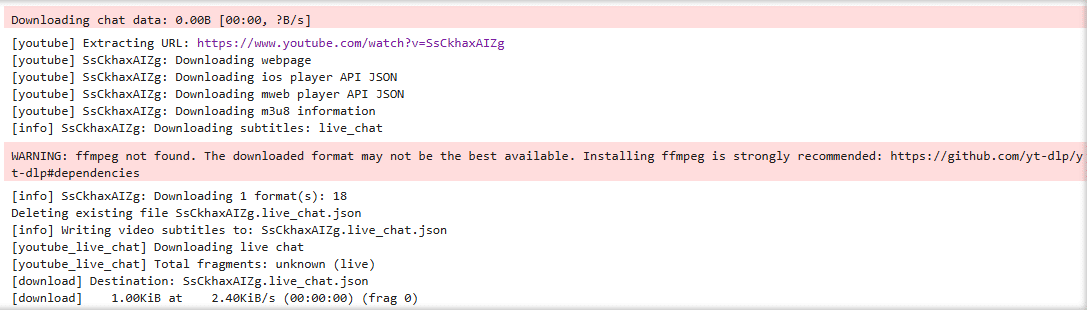
次にダウンロードしたJSONファイルの中身を見てみます。最初の5行だけ抽出。
json_file = f'{video_id}.live_chat.json'
with open(json_file, 'r', encoding='utf-8') as f:
for i in range(5): # 最初の5行を表示
line = f.readline().strip()
try:
data = json.loads(line)
print(json.dumps(data, indent=4, ensure_ascii=False)) # インデント付きで見やすく表示
except json.JSONDecodeError:
print("JSONの読み込みエラーが発生しました。")

へぇ~こんなふうになってるんだ。
じゃあダウンロードしたJSONをエクセル形式にする。
json_file = f'{video_id}.live_chat.json'
excel_file = f'{video_id}live_chat_unique.xlsx'
wb = Workbook()
ws = wb.active
ws.title = "Chat Data"
ws.append(['Author', 'Message', 'Timestamp', 'MessageType']) # ヘッダー行
unique_messages = set()
with open(json_file, 'r', encoding='utf-8') as f_json:
for line in f_json:
try:
item = json.loads(line.strip())
if 'replayChatItemAction' in item:
action = item['replayChatItemAction']['actions'][0].get('addChatItemAction', {}).get('item', {})
# liveChatTextMessageRenderer (通常のメッセージ)
if 'liveChatTextMessageRenderer' in action:
message_item = action['liveChatTextMessageRenderer']
author = message_item.get('authorName', {}).get('simpleText', 'Unknown')
message = ''.join([run.get('text', '') for run in message_item.get('message', {}).get('runs', [])])
timestamp = message_item.get('timestampText', {}).get('simpleText', '')
# 重複チェック
if (author, message) not in unique_messages:
ws.append([author, message, timestamp, 'Text'])
unique_messages.add((author, message))
# liveChatPaidMessageRenderer (スーパーチャット)
elif 'liveChatPaidMessageRenderer' in action:
message_item = action['liveChatPaidMessageRenderer']
author = message_item.get('authorName', {}).get('simpleText', 'Unknown')
message = ''.join([run.get('text', '') for run in message_item.get('message', {}).get('runs', [])])
timestamp = message_item.get('timestampText', {}).get('simpleText', '')
# 重複チェック
if (author, message) not in unique_messages:
ws.append([author, message, timestamp, 'Paid'])
unique_messages.add((author, message))
# liveChatViewerEngagementMessageRenderer (システムメッセージ)
elif 'liveChatViewerEngagementMessageRenderer' in action:
message_item = action['liveChatViewerEngagementMessageRenderer']
author = 'SYSTEM'
message = ''.join([run.get('text', '') for run in message_item.get('message', {}).get('runs', [])])
timestamp = message_item.get('timestampText', {}).get('simpleText', 'N/A')
# 重複チェック
if (author, message) not in unique_messages:
ws.append([author, message, timestamp, 'Engagement'])
unique_messages.add((author, message))
except json.JSONDecodeError:
print("JSONの解析中にエラーが発生しました。スキップします。")
except KeyError as e:
print(f"必要なデータが見つかりませんでした({e})。スキップします。")
wb.save(excel_file)
print(f"重複のないチャットデータをExcelファイル {excel_file} に保存しました。")

ユニークなデータにしてます。
お、ちゃんと抽出されてますね。よかった。

私はLLMが苦手だ
まとめ
なんとか4時間くらいで抽出コードが書けた。
中途半端な出来だが、人間やればなんとかなるもんだ。
ほなまた