
MeCab の品詞解析を用いた教員名の表記揺れ解消

はじめに
こんにちは!株式会社Hashupのエンジニア棚橋です。大学時代は情報系の学部に所属しており、基本的なプログラミングの講義などを受けたことはあったのですが、Hashupに入社してから本格的にプロジェクトに参加させてもらえるようになりました。普段の受託案件の内容は発信することができないのですが、今回自社サービス「楽単らくだ」のタスクということで記事を書くことにしました。以下、報告書のため「である調」で書いています。
経緯
弊社では大学生向け授業評価サイト「楽単らくだ」を運用している。本サービスのリニューアルに伴うデータ移行にあたり、非構造的なデータの整理を実施している。
手動での整理が困難なタスクの一つに教員名の正規化がある。本来、教員名テーブル等を用意し、名寄せされた形式で運用すべきところ、不幸なことに教員名は string 型を受け付けるように運用されていたため、様々なデータが混在している。例えば、姓名間のスペースの有無や、教員名間の区切り方法が統一されていない。また、「など」「他」のような人名以外が入力されているパターンもある。そこで、教員名の正規化を自動化することとなった。
自動化のメリット
1万件以上のデータの正規化を手動で行う手間を、自動化する事により削減できる。さらに、自動化しておく事により、”一名の教員氏名のみを含むデータ” と ”複数名の教員氏名を含むデータ” の管理がしやすくなる。その結果、姓名が不足しているデータの姓名を予測するなどの応用が可能になる。
課題
以下に、教員名に入力された課題となっているパターンを挙げる。
このNote全体を通して、教員名は仮の名前に置き換えている。

提案手法
提案手法の概観

MeCab を用いた教員名元データの品詞分解
MeCab [2] は形態素解析エンジンであり、品詞の解析や姓名の識別に使用する。MeCabの辞書に関しては頻繁に辞書が更新されている mecab-ipadic-NEologdを使用している[3]。以下に品詞分解の例を示す。
>>> dicdir = subprocess.getoutput("mecab-config --dicdir")
>>> wakati = MeCab.Tagger(f"-d {dicdir}/mecab-ipadic-neologd")
>>> parsed_text = wakati.parse(‘山田太郎’)
山田 名詞,固有名詞,人名,姓,*,*,山田,ヤマダ,ヤマダ
太郎 名詞,固有名詞,人名,名,*,*,太郎,タロウ,タロー
EOSまた、MeCab は parseNBest 関数を用いる事で、品詞解析結果の候補を出力する機能を備えている。以下に第三候補まで出力する場合の例を示す。
>>> dicdir = subprocess.getoutput("mecab-config --dicdir")
>>> wakati = MeCab.Tagger(f"-d {dicdir}/mecab-ipadic-neologd")
>>> parsed_text = wakati.parseNBest(3, '山田太郎')
山田太郎 名詞,固有名詞,人名,一般,*,*,山田太郎,ヤマダタロウ,ヤマダタロー
EOS
山田 名詞,固有名詞,人名,姓,*,*,山田,ヤマダ,ヤマダ
太郎 名詞,固有名詞,人名,名,*,*,太郎,タロウ,タロー
EOS
山田 名詞,固有名詞,人名,姓,*,*,山田,ヤマダ,ヤマダ
太郎 名詞,固有名詞,人名,名,*,*,太郎,タロウ,タロー
EOSMeCab のみでも姓名判断でき、課題一覧であげた、”姓_名”、”姓”、”姓_名_姓_名”、”アルファベット”の問題については解決できる。また、解析された品詞情報を用いることで、”教員名以外”を含む人名以外の文字列を除外することができる。さらに、”姓” と “名” の組み合わせによって次の5つのパターンに分類することができる。
一名の教員氏名のみを含むデータ
複数名の教員氏名を含むデータ
名字のみを含むデータ
アルファベットを含むデータ
人名ではあるが分類されていないもの
それぞれのパターンは以下のようになっている。

しかし、MeCab のみでは解決できない場合がある。"人名ではあるが分類されていないもの" は、"一名の教員氏名のみを含むデータ", "複数名の教員氏名を含むデータ" が存在している。"人名" で構成されるが、”姓_名”, “姓_名_姓_名”, “姓” 以外のパターンであったため、こちらに含まれている。具体的には、次のパターンが例として考えられる。
“姓_名_姓_名_姓_名” などの3名以上のパターン
本来 “姓_名” だが ”姓_名_名” などに余分に分割されたパターン
”教員名以外” に関しては、"一名の教員氏名のみを含むデータ", "複数名の教員氏名を含むデータ", "名字のみを含むデータ", "教員名以外" が混在している。"人名" 以外の要素と判定されたものがあると、こちらに含まれる。
このように分類しきれていない問題がある。
また、MeCab で姓名分離できたものの、”教員名以外” のパターンについては確信度が低く、手動確認が必要なパターンもある。"宮_﨑_真理子" のように、余分な場所や違う場所に分割の候補が入ってしまっている場合が存在している場合だ。
フラグの導入
MeCab の品詞解析結果の固有名詞数に基づいて、一名フラグ・複数名フラグ・保留フラグを付与する。具体的には、固有名詞数が 1〜2 の際は一名フラグ、3 以上の場合は複数名フラグ、固有名詞がない場合は保留フラグを付与する。これらを参考に手動作業をする。
手動作業
手動作業の内容は、自動で csv として書き出したものの変更箇所を修正して保存するのみである。csv の修正は、以下の3点のみを行う。
姓名を分ける位置
複数名のリスト化
明らかに不要なものなどの判断
csv の修正後にレシピを再開すると、自動で csv を読み込み処理をするようになっている。
フラグの活用方法は、固有名詞数・一名フラグ・複数名フラグ・保留フラグを参考に、作業者自身の任意の優先順位を付けて修正を行う。優先順位の付け方の例としては、複数名フラグで絞り込むことで 「リスト形式に変換する作業をある程度まとめることができる」や、保留フラグで絞り込むことで 「本当に不必要(教員名以外)のデータかどうかの確認作業にある程度まとめることができる」などである。
データベースに渡すデータに対して修正・採用するのか判定する際に、csv の情報を辞書に格納し、この辞書で判定するという活用方法がある。辞書は以下のようになっている。
{
"元々の教員名":
{
"teachers_data": "手動で確認後の教員名",
"hold_flag": "採用かどうか"
}
}結果
MeCab を用いた教員名元データの品詞分解
「楽単らくだ」の全ての教員名元データ1819個中1493個のデータを解決できた。"一名の教員氏名のみを含むデータ", "複数名の教員氏名を含むデータ", "名字のみを含むデータ" に分ける際には、分かちがきの ”人名” と ”姓”, ”名” のパラメータを参照しているため精度が高い。それらに分類されなかった "人名ではあるが、分類できないもの", "その他" は ”固有名詞” のパラメータを参照しているため、分割の精度が低くなっている。

考察
今回の自動化によって、"一名の教員氏名のみを含むデータ", "複数名の教員氏名を含むデータ", "姓名どちらも含まないデータ" を、作業を効率的に行うことができる範囲の纏まりにすることができた。固有名詞数, 一名フラグ, 複数名フラグ, 保留フラグでソート・フィルターをし参考に手作業を行うことで、
複数名の処理
一名の処理
複数名 または 一名の処理
例外の処理
とまとめて処理を行えた。複数名の処理、一名の処理、例外の処理のみの作業を優先し、複数名または一名の処理が混在している範囲を一旦保留とした際は、どの処理をする必要があるか1行づつ考える必要がなく、時間をおよそ半減できる。複数名または一名の処理が混在している範囲も含めて登録する際も、ほとんどが1名の場合が多くそれほど悩むことなく作業できるため、筆者の体感では70%ほどの作業時間になると考えられる。結果として、全てのデータに対して手動確認作業を行った場合、30%程度の作業時間低減が実現できると考えている。
おわりに
結論
非構造な教員名のデータに対し、MeCab を用いた品詞分解の仕組みを応用することで、教員名の正規化を試みた。結果、80%のデータは品詞分析とルールベースの判断により自動で正規化できた。一方、ルールベースで判断できなかった手動確認が必要なデータに対して、固有名詞数を基としたラベルを付与することで、確認作業の低減に繋がる結果を得た。
今後の課題
既存のデータを用いた補完
現在教員名が名字のみとなっているものを、講義名を用いて名前を予測するアルゴリズムの検証も検討している。具体的には、姓のみのデータ(複数名も含む)の ”講義名と姓” を、”姓 名” となっているデータの ”講義名と姓” と比較し、合致した場合は姓のみのデータに名前を追加する。また、学期・年度も加味することで、”山田太郎など” のように本来複数名だが、”など” と ”山田太郎” 以外が省略されてしまっているデータに関しても、[”山田太郎”, “佐藤花子”] のように複数名に変換できるよう応用していきたい。
付録
苦労した点
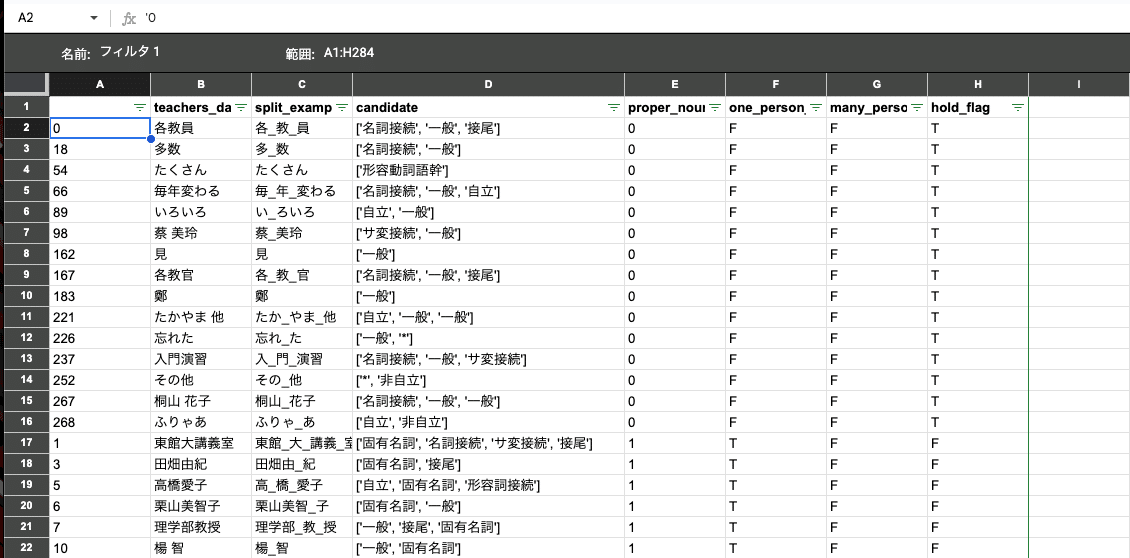
本題とは外れるが、手動作業を自動工程の中に取り入れる仕組みの設計に苦労した。エンジニア自身が編集する場合、生のJSONファイルを編集するなどできるが、非エンジニアが手動作業できることを想定し、Excelで扱いやすいCSVを中間データとして出す工夫を取り入れた。また、作業者が効率的に確認作業を行えるように、自動解析の根拠となる ”元々の教員名, 教員名の分割例, 品詞, 固有名詞数, 一名フラグ, 複数名フラグ, 保留フラグの有無” を1行内に併記し、参照できるようにした。実際の作業画面の例は以下の画像のようになっている。
ソート・フィルターをしていない場合、以下のようになっている。

固有名詞数でソートした場合、以下のようになっており、教員名以外のデータがまとまっている。
面白いデータの紹介
最後に、今回のスクリプトを試行錯誤する際に、データを何度も見て面白かったデータをご紹介したい。
たくさん ← 確かにたくさんでも間違いではない
いろいろ ← 色々あったのでしょう
〇〇だったような違ったような, 〇〇なんとか ← 確かに出てこない時はあります
〇〇+α(オムニバス) ← シラバス通りの可能性もありますが、ワードセンスが好きです
忘れた, 不明 ← 完全に忘れちゃった or ミステリー
ふりゃあ ← ゲストで先生をしたのでしょうか、、、
それぞれ投稿していただいた方の個性が出ているなと感じた。
また、この他に誹謗中傷と捉えられる表現のものもあった。こういった誹謗中傷と捉えられるものを検出できるようにし、入力時に防止することができるようにしたい。
参考文献
[1] Basic Name Divider
GitHub URL: https://github.com/rskmoi/namedivider-python
[2] MeCab
GitHub URL: https://taku910.github.io/mecab/
[3] mecab-ipadic-NEologd
GitHub URL: https://github.com/neologd/mecab-ipadic-neologd