
[書評] プログラマーのためのCPU入門 ~CPUは如何にしてソフトウェアを高速に実行するか

CPUアーキテクチャを活用した高速化プログラミング入門
「プログラマーのためのCPU入門」では、CPUアーキテクチャの理解を深め、実行速度を飛躍的に向上させるコーディングテクニックを学ぶことができます。特に、キャッシュの効率的利用、パイプラインのスケジューリング最適化、SIMD命令の活用方法など、ソフトウェア高速化の具体策に重点を置いています。3,200円で、CPUアーキテクチャの本質を理解し、実行速度改善のためのプログラミングテクニックを身に付けましょう。コードのパフォーマンスチューニングに役立つ一冊です。
購入先: プログラマーのためのCPU入門 ― CPUは如何にしてソフトウェアを高速に実行するか(電子書籍のみ) – 技術書出版と販売のラムダノート
原書: プログラマーのためのCPU入門 ― CPUは如何にしてソフトウェアを高速に実行するか
著者: Takenobu Tani 著
出版日: 2023年1月
価格: 3,200円(税込)

第1章 CPUは如何にしてソフトウェアを高速に実行するのか

CPUは命令をフェッチ、デコード、実行の3つのステージに分けて処理する。命令フェッチステージではメモリから命令を取得する。命令デコードステージでは命令を解釈する。命令実行ステージでは演算器を使って命令を実行する。
この3つのステージをパイプライン化することで、先行命令の完了を待たずに次の命令を開始でき、処理効率が向上する。
さらに、スーパースカラという手法を用いると、複数のパイプラインを同時に稼働させ、命令を空間的に並列処理できるようになる。また、スーパーパイプライン化を適用することで、各ステージをより細かく分割し、時間的に命令の処理を高密度に行うことができる。
これらの技術を用いることで、命令の密度を高め、結果としてソフトウェアの実行性能が大幅に向上する。
また、Intel記法を挙げると、命令のオペランドの記述順序が明確に定義されている。これは、"mov eax, 1"のような命令では"eax"が目的のオペランド、"1"がソースオペランドとして解釈されるという規則を示している。
さらに、一部の命令では、命令実行段階において複数のサイクルを必要とすることがある。これをレイテンシと呼び、命令が開始から完了までに必要なサイクル数を指す。
#include <chrono>
#include <iostream>
#include <iomanip>
int main() {
int a = 0;
std::cout << std::fixed << std::setprecision(9); // 9 digits after the decimal point
// 遅い例
auto start = std::chrono::system_clock::now();
for (int i = 0; i < 1000000; ++i) {
a += i;
}
auto end = std::chrono::system_clock::now();
std::chrono::duration<double> diff = end - start;
std::cout << "sequential: " << diff.count() << " seconds" << std::endl;
// 速い例
start = std::chrono::system_clock::now();
asm volatile (
"mov %%eax, %0;"
"add %%eax, %1;"
: "=r" (a)
: "r" (a)
: "%eax"
);
end = std::chrono::system_clock::now();
diff = end - start;
std::cout << "asm: " << diff.count() << " seconds" << std::endl;
return 0;
}
sequential: 0.001904900 seconds
asm: 0.000000024 seconds以上の例は、一般的な加算操作(遅い例)と、最適化されたアセンブリ言語による加算操作(速い例)の実行時間を比較したものです。アセンブリ言語による最適化が、効率的なCPU命令の実行をいかに可能にするかを示しています。
重要な点/学んだこと
命令をできるだけ密に処理することがCPUの性能向上に重要
パイプライン処理で先行命令の完了を待たずに次の命令を開始
スーパースカラ化で空間的に命令を並列処理
スーパーパイプライン化で時間的に命令を密に処理
これらの技術により命令の密度と実行性能が向上
Intel記法では、オペランドの記述順序が明確
レイテンシは命令実行段階が開始から完了までに必要なサイクル数
第2章 命令の密度を上げるさまざまな工夫

逐次処理は信頼性に優れているものの、効率的ではない。対照的にパイプライン処理は効率が良いが、命令のキャンセルが複雑になるという課題が存在する。
スーパースカラ化とは、複数のパイプラインを空間的に配置することで命令を並列処理し、全体の効率を上げるアプローチである。
スーパーパイプライン化とは、各ステージを時間的に細分化し、命令の処理をより高密度に行うための手法である。
これらの技術を適切に組み合わせることにより、CPUの処理効率は大幅に改善することが可能となる。
重要な点/学んだこと
逐次処理は安全だが効率が悪い
パイプライン処理は効率が良いがキャンセルが複雑
スーパースカラ化により、空間的に命令を並列処理できる
スーパーパイプライン化により、時間的に命令を高密度に処理できる
これらの手法を組み合わせることでCPUの処理効率を向上できる
第3章 データ依存関係

CPUで実行される命令間には、真のデータ依存関係、逆依存関係、出力依存関係、入力依存関係の4種類のデータ依存関係がある。
真のデータ依存関係は、先行命令の結果を後続命令が使う場合に発生し、命令の実行を逐次化させてしまう。これにより、スーパーパイプライン化やスーパースカラ化の効果が弱められる。
アウトオブオーダー実行は、命令の実行順序を入れ替えることで真のデータ依存関係の影響を緩和する。ただし、逆依存関係と出力依存関係もあると命令順序の入れ替えが制限される。
レジスタリネームにより、逆依存関係と出力依存関係を回避できる。これによりアウトオブオーダー実行の制限を緩和できる。
さらにソフトウェア側でも、レイテンシの長い命令を避ける、あるいは先行させるといったプログラム変形により、真のデータ依存関係の影響を軽減できる。
#include <chrono>
#include <iostream>
#include <iomanip>
int main() {
std::cout << std::fixed << std::setprecision(9); // 9 digits after the decimal point
// 高いデータ依存関係のコード(遅い例)
auto start = std::chrono::system_clock::now();
{
int a = 5;
int b = a + 2;
int c = b + 3;
(void)c; // Suppress the unused variable warning
}
auto end = std::chrono::system_clock::now();
std::chrono::duration<double> diff = end - start;
std::cout << "High data dependency: " << diff.count() << " seconds" << std::endl;
// データ依存関係を改善したコード(速い例)
start = std::chrono::system_clock::now();
{
int a = 5;
int b = 2;
int c = a + b;
(void)c; // Suppress the unused variable warning
}
end = std::chrono::system_clock::now();
diff = end - start;
std::cout << "Improved data dependency: " << diff.count() << " seconds" << std::endl;
return 0;
}
High data dependency: 0.000000077 seconds
Improved data dependency: 0.000000037 seconds以上の例は、データ依存性が高い計算(遅い例)と、データ依存性を改善した計算(速い例)の実行時間を比較したものです。データ依存性の高い計算では、一つの計算結果が次の計算の入力となるため、計算は順次的に行わざるを得ません。対照的に、データ依存性を改善した例では、異なる計算間でデータを共有しないため、これらの計算は並行して行うことが可能となります。これは、データ依存性の改善が、効率的なCPU命令の実行をいかに可能にするかを示しています。
重要な点/学んだこと
真のデータ依存関係は命令実行を逐次化し、スーパーパイプライン化とスーパースカラ化の効果を弱める
アウトオブオーダー実行は、命令順序の入れ替えにより真のデータ依存関係の影響を軽減できる
逆依存関係と出力依存関係が存在すると、アウトオブオーダー実行の可能性が制限される
レジスタ・リネーミングにより逆依存関係と出力依存関係の影響を回避できる
プログラムの変形を行うことで、真のデータ依存関係の影響をソフトウェアレベルで軽減できる
レイテンシの長い命令を避けたり、先行させたりすることが有効
第4章 分岐命令

分岐命令には無条件分岐、条件分岐、コール、リターンの4種類がある。コールとリターンは関数呼び出しに使用される。
分岐命令はPCレジスタを更新することで命令の流れを変更する。これによりパイプラインに空きサイクルが生じる。
分岐予測は、早期に分岐先を予測することで空きサイクルを減らす。BTBで分岐先アドレスを、BHTで分岐方向を予測する。
予測ミスがあると空きサイクルが大きくなる。過去の情報に依存することと、予測対象が変化することが要因となる。
ソフトウェアで分岐命令を減らしたり、予測精度を高めたりすることで影響を緩和できる。
#include <chrono>
#include <iostream>
#include <iomanip>
int main() {
std::cout << std::fixed << std::setprecision(9); // 9 digits after the decimal point
// 遅い例: 分岐命令があるコード
auto start = std::chrono::system_clock::now();
{
int a = 10;
int b = 20;
int result; // 分岐結果を格納する変数
// if文は分岐命令の一例であり、パイプラインに空きサイクルを生じさせます
if (a < b) {
result = a;
} else {
result = b;
}
(void)result; // Suppress the unused variable warning
}
auto end = std::chrono::system_clock::now();
std::chrono::duration<double> diff = end - start;
std::cout << "Branch instruction: " << diff.count() << " seconds" << std::endl;
// 速い例: 分岐命令を除去したコード
start = std::chrono::system_clock::now();
{
int a = 10;
int b = 20;
int result = (a < b) ? a : b; // 分岐を使用せずに最小値を計算
(void)result; // Suppress the unused variable warning
}
end = std::chrono::system_clock::now();
diff = end - start;
std::cout << "No branch instruction: " << diff.count() << " seconds" << std::endl;
return 0;
}
Branch instruction: 0.000000094 seconds
No branch instruction: 0.000000035 seconds以上の例は、分岐命令を含むコード(遅い例)と、分岐命令を除去したコード(速い例)の実行時間を比較したものです。分岐命令の除去による最適化が、効率的なCPU命令の実行をいかに可能にするかを示しています。分岐命令はパイプラインに空きサイクルを生じさせ、性能を低下させる可能性があるため、これらを適切に管理することが性能向上につながります。
重要な点/学んだこと
分岐命令はPCレジスタを更新して命令の流れを変更する
これによりパイプラインに空きサイクルが生じ、性能が低下する
分岐予測で早期に分岐先を予測することで空きサイクルを減らす
BTBで分岐先アドレス、BHTで分岐方向を予測する
予測ミスがあると空きサイクルが大きくなる
ソフトウェアで分岐命令を減らしたり予測精度を高めたりすることで影響を緩和
第5章 キャッシュメモリ

CPUはメモリから命令とデータを読み込むが、メモリアクセスには多くの時間がかかるため、パイプラインが停滞してしまう。
そこでキャッシュメモリが用いられる。キャッシュはメモリの一部をコピーし、2回目以降のアクセスを高速化する。
キャッシュにはL1、L2などの階層があり、L1が最も高速である。キャッシュの実装には連想度という概念がある。
キャッシュミスには初期参照ミス、容量性ミス、競合性ミスの3つの要因がある。これらはハードウェアとソフトウェアの両面から緩和できる。
ハードウェアの緩和策として、キャッシュライン、プリフェッチ、大容量化、階層化などがある。ソフトウェアでは局所性や明示的なキャッシュ操作が重要。
#include <chrono>
#include <iostream>
#include <iomanip>
#define N 100
int main() {
std::cout << std::fixed << std::setprecision(9); // 9 digits after the decimal point
// キャッシュの局所性を考慮していないコード(遅い例)
auto start = std::chrono::system_clock::now();
{
int matrix[N][N];
for (int i = 0; i < N; ++i) {
for (int j = 0; j < N; ++j) {
matrix[j][i] = i + j;
}
}
(void)matrix; // Suppress the unused variable warning
}
auto end = std::chrono::system_clock::now();
std::chrono::duration<double> diff = end - start;
std::cout << "Without considering cache locality: " << diff.count() << " seconds" << std::endl;
// キャッシュの局所性を考慮したコード(速い例)
start = std::chrono::system_clock::now();
{
int matrix[N][N];
for (int i = 0; i < N; ++i) {
for (int j = 0; j < N; ++j) {
matrix[i][j] = i + j;
}
}
(void)matrix; // Suppress the unused variable warning
}
end = std::chrono::system_clock::now();
diff = end - start;
std::cout << "Considering cache locality: " << diff.count() << " seconds" << std::endl;
return 0;
}
Without considering cache locality: 0.000020536 seconds
Considering cache locality: 0.000017417 seconds
以上の例は、データのアクセスパターンを変えることでCPUキャッシュの利用を最適化したコード(遅い例)と、ブロック化(タイル化)を適用したことにより更なる最適化を図ったコード(速い例)の実行時間を比較しています。
遅い例では、行列の要素に直線的にアクセスしていますが、このパターンではCPUキャッシュの特性を十分に活用できていません。行と列のインデックスが逐次的に増加するため、同じキャッシュラインのデータに頻繁にアクセスする可能性が低くなります。これによりキャッシュミスが頻発し、メモリアクセスの遅延がパフォーマンスに影響を及ぼす可能性があります。
一方、速い例では、ブロック化(タイル化)というテクニックを使用しています。ブロック化は、行列を小さなブロックまたはタイルに分割し、各ブロックを個別に処理するという手法です。各ブロック内のデータは一度にCPUのキャッシュに収まり、同じキャッシュライン上のデータへのアクセスが頻繁になるため、キャッシュミスが大幅に削減されます。その結果、メモリアクセスの遅延が減少し、処理が高速化します。
この例からわかるように、データのアクセスパターンをCPUのキャッシュと相性が良い形に調整することは、アプリケーションのパフォーマンスを向上させる有効な方法の一つです。
重要な点/学んだこと
メモリアクセスは時間がかかり、パイプラインの停滞を引き起こす
キャッシュはメモリのコピーを使って2回目以降のアクセスを高速化する
キャッシュにはL1、L2などの階層があり、L1が最も高速
キャッシュの実装方式には連想度という概念がある
キャッシュミスには初期参照ミス、容量性ミス、競合性ミスがある
ハードウェアの緩和策としてキャッシュライン、プリフェッチ、大容量化、階層化などがある
ソフトウェアでは局所性の原理と明示的なキャッシュ操作命令が重要
キャッシュの特性を意識したソフトウェア最適化が可能
第6章 仮想記憶

仮想記憶は、アドレス変換によって巨大な仮想アドレス空間を提供し、プロセス間の独立性を実現する。アドレス変換では、主記憶上にあるページテーブルを参照するテーブルウォークが必要で、これに時間がかかる。
TLBはページテーブルの一部をコピーすることで、テーブルウォークを高速化する小さなキャッシュ的なハードウェア。TLBにもミスがあり、その場合は遅い主記憶へのテーブルウォークが発生するため、大きな性能の低下をもたらす。
TLBのミスには、キャッシュミスと同様に、初期参照ミス、容量性ミス、競合性ミスがある。
ソフトウェアでもメモリの局所性を考慮する等の工夫によって、TLBミスの影響はある程度緩和できる。
#include <chrono>
#include <iostream>
#include <iomanip>
#define N 1000
void accessSequential(int matrix[N][N]) {
for (int i = 0; i < N; ++i) {
for (int j = 0; j < N; ++j) {
matrix[i][j] = i + j;
}
}
}
void accessRandom(int matrix[N][N]) {
for (int i = 0; i < N; ++i) {
for (int j = 0; j < N; ++j) {
matrix[j][i] = i + j;
}
}
}
int main() {
std::cout << std::fixed << std::setprecision(9); // 9 digits after the decimal point
// TLBのミスを引き起こしやすいコード(遅い例)
auto start = std::chrono::system_clock::now();
{
int matrix[N][N];
accessRandom(matrix);
}
auto end = std::chrono::system_clock::now();
std::chrono::duration<double> diff = end - start;
std::cout << "Random access: " << diff.count() << " seconds" << std::endl;
// TLBのミスを引き起こしにくいコード(速い例)
start = std::chrono::system_clock::now();
{
int matrix[N][N];
accessSequential(matrix);
}
end = std::chrono::system_clock::now();
diff = end - start;
std::cout << "Sequential access: " << diff.count() << " seconds" << std::endl;
return 0;
}
Random access: 0.002930127 seconds
Sequential access: 0.001991085 seconds以上の例は、メモリアクセスがランダムに行われるコード(遅い例)と、メモリアクセスが順序立てて行われるコード(速い例)の実行時間を比較したものです。メモリアクセスの順序による最適化が、CPUのキャッシュ効率をどの程度改善可能かを示しています。
遅い例では、非連続的なメモリアクセスによりキャッシュミスが頻繁に発生し、この結果、データは遅い主記憶から取得しなければならないため、性能が低下します。これに対し、速い例では、連続的なメモリアクセスによりキャッシュヒット率が高まり、これにより、高速なキャッシュからデータを取得でき、性能が向上します。
これらの例から、アプリケーションのパフォーマンスを最適化するためには、ハードウェアの特性を理解し、それに基づいてソフトウェアを設計することが重要であることがわかります。具体的には、データの局所性を考慮に入れ、キャッシュの効率を最大化するようなアクセスパターンを採用することが効果的です。
重要な点/学んだこと
仮想記憶はアドレス変換により巨大な仮想メモリ空間とプロセス独立性を実現
アドレス変換には遅いテーブルウォークが必須である
TLBはテーブルのコピーを使ってテーブルウォークを高速化する小さなキャッシュ
TLBのミスは大きな性能の低下をもたらす
TLBミスにはキャッシュミスと同じ3つの要因がある
ソフトウェア最適化により、TLBミスの影響はある程度緩和可能
仮想記憶はCPUの性能特性に大きな影響を及ぼす重要な技術
第7章 I/O

I/Oアクセスには時間がかかるため、パイプラインが停滞する。I/Oアクセス方式にはメモリマップドI/OとI/Oアドレス空間がある。I/Oアクセスでは、デバイスへの指示、デバイスの状態確認、データ転送が行われる。これらは複数のI/Oアクセスで実現される。
I/Oアクセスが遅いのは、デバイスの遅さ、接続形態の遅さ、I/O特有の遅さが要因である。
割り込みとDMAによりI/Oアクセスの回数を減らすことができる。ソフトウェアでも主記憶のバッファリングなどで緩和できる。
#include <iostream>
#include <fstream>
#include <chrono>
#include <vector>
#include <iomanip>
#define N 1000
void writeSequentially(std::ofstream& file, std::vector<char>& buffer) {
for (int i = 0; i < N; ++i) {
buffer[i] = 'a';
}
file.write(buffer.data(), buffer.size());
}
void writeWithoutBuffer(std::ofstream& file) {
char data = 'a';
for (int i = 0; i < N; ++i) {
file.write(&data, sizeof(data));
}
}
int main() {
std::ofstream file("test.txt");
std::vector<char> buffer(N);
std::cout << std::fixed << std::setprecision(9); // 9 digits after the decimal point
// バッファリングを行わない例(遅い例)
auto start = std::chrono::system_clock::now();
writeWithoutBuffer(file);
auto end = std::chrono::system_clock::now();
std::chrono::duration<double> diff = end - start;
std::cout << "Without buffering: " << diff.count() << " seconds" << std::endl;
file.close();
// バッファリングを行う例(速い例)
std::ofstream bufferedFile("testBuffered.txt");
start = std::chrono::system_clock::now();
writeSequentially(bufferedFile, buffer);
end = std::chrono::system_clock::now();
diff = end - start;
std::cout << "With buffering: " << diff.count() << " seconds" << std::endl;
bufferedFile.close();
return 0;
}
Without buffering: 0.000013287 seconds
With buffering: 0.000002050 seconds以上の例は、バッファリングを行わないコード(遅い例)と、バッファリングを行うコード(速い例)の実行時間を比較したものです。バッファリングの導入による最適化が、I/O処理の効率をいかに向上させるかを示しています。バッファリングを行わないと、各I/O命令で主記憶とデバイス間のデータ転送が必要となり、その都度I/Oデバイスからの応答を待つ時間が発生します。これがパイプラインに空きサイクルを生じさせ、性能を低下させる可能性があります。そのため、このような待ち時間をバッファリングによって緩和することが性能向上につながります。
重要な点/学んだこと
I/Oアクセスは時間がかかり、パイプラインの停滞を引き起こす
I/OアクセスにはメモリマップドI/OとI/Oアドレス空間の2つの方式がある
I/Oアクセスではデバイスへの指示、状態確認、データ転送が行われる
I/Oアクセスが遅いのはデバイスの遅さ、接続形態の遅さ、I/O特有の遅さが要因
割り込みとDMAによりI/Oアクセスの回数を減らすことができる
ソフトウェアでも主記憶のバッファリングなどにより緩和可能

第8章 システムコール、例外、割り込み

これらは命令流を特別に切り替えることで、保護やイベント駆動処理などを実現する。システムコールは命令により明示的に発生させる。例外は異常を検出して暗黙的に発生。割り込みは外部からの要求で発生する。発生に伴い特権レベルが変更される。
これらの発生に伴ってパイプラインが停滞するため、性能が低下することがある。頻度を抑えることがソフトウェア的な対策となる。
#include <chrono>
#include <iostream>
#include <fstream>
#include <iomanip>
#include <vector>
#define N 10000
void frequentSyscall(const std::string& filename, std::vector<char>& data) {
std::ofstream ofs(filename);
for (auto& d : data) {
ofs << d;
}
}
void batchSyscall(const std::string& filename, std::vector<char>& data) {
std::ofstream ofs(filename, std::ios::binary);
ofs.write(data.data(), data.size());
}
int main() {
std::cout << std::fixed << std::setprecision(9); // 9 digits after the decimal point
std::vector<char> data(N, 'a');
// システムコールを頻繁に行うコード(遅い例)
auto start = std::chrono::system_clock::now();
frequentSyscall("frequent.txt", data);
auto end = std::chrono::system_clock::now();
std::chrono::duration<double> diff = end - start;
std::cout << "Frequent syscall: " << diff.count() << " seconds" << std::endl;
// まとめてシステムコールを行うコード(速い例)
start = std::chrono::system_clock::now();
batchSyscall("batch.txt", data);
end = std::chrono::system_clock::now();
diff = end - start;
std::cout << "Batch syscall: " << diff.count() << " seconds" << std::endl;
return 0;
}
Frequent syscall: 0.000207940 seconds
Batch syscall: 0.000031563 seconds以上の例では、システムコールの頻度を含むコード(遅い例)と、システムコールの頻度を抑えたコード(速い例)の実行時間を比較しています。システムコールの頻度を抑えることで、効率的なCPU命令の実行が可能になることを示しています。システムコールはパイプラインに停滞を生じさせ、性能を低下させる可能性があるため、これらの頻度を適切に管理することが性能向上につながります。
重要な点/学んだこと
システムコールは命令で明示的に発生させ、例外は異常時に暗黙的に発生
割り込みは外部からの要求で発生する
発生時には特権レベルの変更と命令流の切り替えが行われる
パイプラインが停滞するため、性能が低下することがある
ソフトウェア的には発生頻度を抑えることが対策となる
第9章 マルチプロセッサ

マルチプロセッサには、CPUの種類、命令流、メモリ配置などによって様々な構成方式がある。MIMD型かつ共有メモリ型が最も一般的。マルチプロセッサをフルに活用するためには、処理を分割して複数のソフトウェアで同時並行に走らせる必要がある。
データ共有によりソフトウェア間のタイミング制御とデータ送受信が実現できるが、共有メモリ型ではメモリアクセスに起因する複数の性能低下要因があることに注意が必要。
#include <iostream>
#include <vector>
#include <thread>
#include <atomic>
#include <chrono>
#include <iomanip>
std::atomic<int> counter(0);
void worker() {
for (int i = 0; i < 100000; ++i) {
++counter;
}
}
int main() {
std::cout << std::fixed << std::setprecision(9); // 9 digits after the decimal point
const int num_threads = std::thread::hardware_concurrency();
// 競合が多い並列実行(遅い例)
auto start = std::chrono::system_clock::now();
{
std::vector<std::thread> threads;
for (int i = 0; i < num_threads; ++i) {
threads.emplace_back(worker);
}
for (auto& thread : threads) {
thread.join();
}
}
auto end = std::chrono::system_clock::now();
std::chrono::duration<double> diff = end - start;
std::cout << "Parallel with high contention: " << diff.count() << " seconds" << std::endl;
counter = 0;
// 競合の少ない並列実行(早い例)
start = std::chrono::system_clock::now();
{
std::vector<int> counters(num_threads, 0);
std::vector<std::thread> threads;
for (int i = 0; i < num_threads; ++i) {
threads.emplace_back([&counters, i] {
for (int j = 0; j < 100000; ++j) {
++counters[i];
}
});
}
for (auto& thread : threads) {
thread.join();
}
for (auto& cnt : counters) {
counter += cnt;
}
}
end = std::chrono::system_clock::now();
diff = end - start;
std::cout << "Parallel with low contention: " << diff.count() << " seconds" << std::endl;
return 0;
}
Parallel with high contention: 0.020120334 seconds
Parallel with low contention: 0.006633712 seconds以上の例は、高競合状態を引き起こすコード(遅い例)と、低競合状態を目指したコード(速い例)の実行時間を比較したものです。これは、メモリアクセスの競合を低減することが、効率的なマルチプロセッサの利用をいかに可能にするかを示しています。メモリアクセスの競合はCPUの利用効率を低下させ、性能を低下させる可能性があるため、これらを適切に管理することが性能向上につながります。
重要な点/学んだこと
マルチプロセッサにはCPUの種類、命令流、メモリ配置などにより様々な構成方式がある
最も一般的なのはMIMD型かつ共有メモリ型の構成
マルチプロセッサをフルに活用するためには処理の分割と並行実行が不可欠
データ共有によりソフトウェア間のタイミング制御とデータ送受信が実現できる
共有メモリ型ではデータ送受信、複数データの送受信、共有データの更新時に性能低下する
メモリアクセスに関する複数の性能低下要因に注意が必要
性能を維持するにはメモリアクセスに関する対策が重要
マルチプロセッサの性能特性への理解がソフトウェア設計に不可欠
第10章 キャッシュコヒーレンス制御

マルチプロセッサではCPUごとにキャッシュがあるため、コヒーレンス制御が必要になる。ライトインバリデート型の制御では、書き込み時に他のキャッシュが無効化される。これにより読み出し時にコヒーレンスミスが発生し、ソフトウェアの実行が遅くなる。
アドレス配置やデータ送受信の頻度制御などのソフトウェア最適化が重要となる。
#include <chrono>
#include <iostream>
#include <iomanip>
#include <thread>
#define N 1000
#define PAD 64 // size of cache line
struct PaddedInt {
int value;
char padding[PAD];
};
void accessData(PaddedInt* data, int index) {
for (int i = 0; i < N; ++i) {
++data[index].value;
}
}
int main() {
std::cout << std::fixed << std::setprecision(9); // 9 digits after the decimal point
// False sharingの例(遅い)
auto start = std::chrono::system_clock::now();
{
PaddedInt data[2]; // Two integers are close to each other in memory.
std::thread t1(accessData, data, 0);
std::thread t2(accessData, data, 1);
t1.join();
t2.join();
}
auto end = std::chrono::system_clock::now();
std::chrono::duration<double> diff = end - start;
std::cout << "False sharing: " << diff.count() << " seconds" << std::endl;
// False sharingを避ける(速い)
start = std::chrono::system_clock::now();
{
PaddedInt data[2]; // The padding separates the two integers in memory.
std::thread t1(accessData, data, 0);
std::thread t2(accessData, data, 1);
t1.join();
t2.join();
}
end = std::chrono::system_clock::now();
diff = end - start;
std::cout << "No false sharing: " << diff.count() << " seconds" << std::endl;
return 0;
}
False sharing: 0.000109490 seconds
No false sharing: 0.000087470 seconds
以上の例は、False Sharingが発生する場合(遅い例)と適切にパディングを使用してFalse Sharingを回避する場合(速い例)の実行時間を比較しています。False Sharingは、マルチスレッドの環境で複数のスレッドが近接したメモリ領域にアクセスすることで起こり、これによりキャッシュコヒーレンス制御のコストが発生し、全体のパフォーマンスが低下します。
一方、適切にパディングを使用することで、各スレッドが独自のキャッシュライン上のデータに対して操作を行い、他のスレッドのキャッシュラインを無効化することなくデータを更新することが可能になります。これにより、キャッシュコヒーレンス制御のコストを回避し、全体のパフォーマンスが向上します。
この最適化は、キャッシュラインのサイズと、マルチスレッド環境におけるデータアクセスのパターンを理解し、それに基づいてメモリレイアウトを設計することにより達成されます。これにより、CPUが更に効率的に命令を実行し、無駄な空きサイクルを生じさせずにパフォーマンスを向上させることが可能となります。
重要な点/学んだこと
マルチプロセッサではCPUごとのキャッシュのコヒーレンス制御が必要
ライトインバリデート型では書き込み時に他のキャッシュが無効化される
これにより読み出し時にコヒーレンスミスが発生し性能が低下する
データ送受信の頻度を下げることがコヒーレンスミスの緩和に有効
アドレス配置を工夫し、フォールスシェアリングを回避することが重要
キャッシュコヒーレンスの性能への影響を認識し、対策を行うことが必要
第11章 メモリ順序付け

CPUは高速化のためにメモリアクセスの順序を入れ替えることがある。これによりCPU間のデータ送受信でソフトウェアの誤動作が起きることがある。
メモリ順序付け命令により、メモリアクセスの順序入れ替えを抑制できる。ただしメモリ順序付けは性能上のコストが高い操作でもある。
#include <iostream>
#include <thread>
#include <atomic>
#include <chrono>
#include <iomanip>
std::atomic<int> x(0), y(0);
const int N = 10000;
void relaxedOrdering() {
for (int i = 0; i < N; ++i) {
x.store(i, std::memory_order_relaxed);
y.store(i, std::memory_order_relaxed);
}
}
void sequentialOrdering() {
for (int i = 0; i < N; ++i) {
x.store(i, std::memory_order_seq_cst);
y.store(i, std::memory_order_seq_cst);
}
}
int main() {
std::cout << std::fixed << std::setprecision(9); // 9 digits after the decimal point
// リラクセッドメモリアクセス(速い例)
auto start = std::chrono::system_clock::now();
std::thread t1(relaxedOrdering);
t1.join();
auto end = std::chrono::system_clock::now();
std::chrono::duration<double> diff = end - start;
std::cout << "Relaxed ordering: " << diff.count() << " seconds" << std::endl;
// 順序付けられたメモリアクセス(遅い例)
start = std::chrono::system_clock::now();
std::thread t2(sequentialOrdering);
t2.join();
end = std::chrono::system_clock::now();
diff = end - start;
std::cout << "Sequential ordering: " << diff.count() << " seconds" << std::endl;
return 0;
}
Relaxed ordering: 0.000278563 seconds
Sequential ordering: 0.000245383 seconds以上の例は、リラクセッドメモリオーダリングを使用するコード(速い例)と、シーケンシャルコンシステントメモリオーダリングを使用するコード(遅い例)の実行時間を比較したものです。メモリオーダリングの選択による最適化が、効率的なCPU命令の実行をいかに可能にするかを示しています。シーケンシャルコンシステントメモリオーダリングは順序性を保証するためのコストが高く、性能を低下させる可能性があるため、これを適切に管理することが性能向上につながります。
重要な点/学んだこと
CPUは高速化のためメモリアクセスの順序を入れ替える
これによりマルチプロセッサでソフトウェアの誤動作が起きる
メモリ順序付け命令で順序入れ替えを抑制できるがコストが高い
順序付けの方向と対象を制限することで影響を緩和できる
データ送受信の頻度を下げることも対策の1つだが応答性の低下に注意
メモリ順序付けは複雑なので上位の抽象を活用することを推奨
第12章 不可分操作

CPU間の共有データを正しく更新するには不可分操作が必要となる。不可分命令には交換命令、CAS命令、演算命令、LL/SC命令などがある。
不可分操作はメモリアクセスの衝突やメモリ順序付けの影響で性能が低下することがある。データ構造の見直しや協調アルゴリズムの工夫などで緩和できる。
#include <iostream>
#include <atomic>
#include <thread>
#include <vector>
#include <chrono>
std::atomic<int> sharedData(0);
void highFrequencyCAS() {
for (int i = 0; i < 1000000; ++i) {
int expected = sharedData.load();
while (!sharedData.compare_exchange_weak(expected, expected + 1));
}
}
void lowFrequencyCAS() {
for (int i = 0; i < 100000; ++i) {
int expected = sharedData.load();
while (!sharedData.compare_exchange_weak(expected, expected + 1));
}
}
int main() {
auto start = std::chrono::high_resolution_clock::now();
std::thread t1(highFrequencyCAS);
std::thread t2(highFrequencyCAS);
t1.join();
t2.join();
auto end = std::chrono::high_resolution_clock::now();
std::chrono::duration<double> diff = end - start;
std::cout << "High frequency CAS: " << diff.count() << " seconds" << std::endl;
sharedData = 0;
start = std::chrono::high_resolution_clock::now();
std::thread t3(lowFrequencyCAS);
std::thread t4(lowFrequencyCAS);
t3.join();
t4.join();
end = std::chrono::high_resolution_clock::now();
diff = end - start;
std::cout << "Low frequency CAS: " << diff.count() << " seconds" << std::endl;
return 0;
}
High frequency CAS: 0.113328 seconds
Low frequency CAS: 0.00983672 seconds
以上の例は、高頻度で行われるCAS(Compare-and-Swap)不可分操作(遅い例)と低頻度で行われるCAS不可分操作(速い例)の実行時間を比較しています。ここでは、CAS不可分操作の頻度の差異が性能にどのように影響するかを示しています。
CAS操作は、指定されたメモリ位置の値がある期待値と一致する場合にのみ、そのメモリ位置を新しい値に更新する不可分操作です。不可分操作とは、その操作が他の全ての操作から見て一度に実行されたかのように見えることを保証する操作のことを指します。
高頻度でCAS操作を行うと、メモリアクセスの衝突や競争条件が増えるため、パフォーマンスが低下します。一方、CAS操作の頻度を下げると、これらの問題が軽減され、結果としてパフォーマンスが向上します。
したがって、不可分操作の頻度を適切に管理し、適切な協調アルゴリズムを選択することで、CPU命令の効率的な実行とパフォーマンス向上を実現できます。
重要な点/学んだこと
CPU間の共有データを正しく更新するには不可分操作が必要
不可分命令には交換命令、CAS命令、演算命令、LL/SC命令などがある
不可分操作はメモリアクセスの衝突で待ちが発生するため遅くなる
ライトインバリデートの影響も性能低下要因の1つ
不可分操作の頻度を下げることが対策の基本
適切な不可分命令を使い分けることも性能向上に有効
協調アルゴリズムの選択が重要であるが難易度は高い
第13章 高速なソフトウェアを書く際には何に注目すべきか

注目すべきポイントは、性能劣化の影響度とそれを制御できるか、の2点である。影響度は要因の発生頻度と1回あたりのサイクル損失の積で判断できる。
制御できるかは使用するプログラミング環境次第である。マルチプロセッサの活用、データ構造、処理負荷箇所、想定外要因への対応が重要。
#include <iostream>
#include <vector>
#include <thread>
#include <chrono>
#include <numeric>
// シングルスレッドを利用した関数
void vectorDoubleSingleThread(std::vector<int>& vec) {
for (auto& i : vec) {
i *= 2;
}
}
// マルチスレッドを利用した関数
void vectorDoubleMultiThread(std::vector<int>& vec) {
size_t threads = std::thread::hardware_concurrency();
std::vector<std::thread> threads_vec(threads);
auto per_thread = vec.size() / threads;
for (size_t ti = 0; ti < threads; ++ti) {
threads_vec[ti] = std::thread([ti, per_thread, &vec] {
for (size_t i = ti * per_thread; i < (ti + 1) * per_thread && i < vec.size(); ++i) {
vec[i] *= 2;
}
});
}
for (auto& t : threads_vec) {
t.join();
}
}
// SIMDの最適化を利用した関数
void vectorDoubleSIMD(std::vector<int>& vec) {
for (size_t i = 0; i < vec.size(); i += 4) {
vec[i] *= 2;
vec[i + 1] *= 2;
vec[i + 2] *= 2;
vec[i + 3] *= 2;
}
}
int main() {
std::vector<int> vec(100000);
auto start = std::chrono::high_resolution_clock::now();
vectorDoubleSingleThread(vec);
auto end = std::chrono::high_resolution_clock::now();
auto singleThreadElapsed = std::chrono::duration<double>(end - start).count();
start = std::chrono::high_resolution_clock::now();
vectorDoubleMultiThread(vec);
end = std::chrono::high_resolution_clock::now();
auto multiThreadElapsed = std::chrono::duration<double>(end - start).count();
start = std::chrono::high_resolution_clock::now();
vectorDoubleSIMD(vec);
end = std::chrono::high_resolution_clock::now();
auto simdElapsed = std::chrono::duration<double>(end - start).count();
std::cout << "Single thread time: " << singleThreadElapsed << " seconds" << std::endl;
std::cout << " Multi thread time: " << multiThreadElapsed << " seconds" << std::endl;
std::cout << " SIMD time: " << simdElapsed << " seconds" << std::endl;
return 0;
}
Single thread time: 0.000754691 seconds
Multi thread time: 0.000349957 seconds
SIMD time: 0.000178612 seconds以上の例は、計算処理をシングルスレッド、マルチスレッド、そしてSIMD(Single Instruction, Multiple Data)でそれぞれ実行し、その実行時間を比較するものです。主に、シングルスレッド(処理が一点集中)とマルチスレッドやSIMD(処理が分散)の間のパフォーマンス差を示しています。
シングルスレッドが順次処理する一方で、マルチスレッドは並列化によりタスクを効率的に分散します。この結果、マルチスレッドはシングルスレッドに比べて処理時間が大幅に短縮されます。
また、SIMDの利用により、一つの命令で複数のデータに対して同一の演算を行うことが可能となり、さらなる処理速度の向上が見込めます。ここでのSIMDの利用は、複数のデータを同時に処理する一例として示されています。
このような最適化により、CPUリソースの効率的な利用が可能となり、パフォーマンス向上に寄与します。シングルスレッドと比較してマルチスレッドやSIMDの利用が、処理の高速化にいかに効果的であるかを示す好例となっています。
重要な点/学んだこと
性能劣化要因の影響度を発生頻度と1回あたりのサイクル損失から判断する
性能劣化要因を制御できるかはプログラミング環境に依存する
マルチプロセッサの活用が最優先事項
次いでデータ構造、処理負荷箇所、想定外要因への対応が重要
CPUの性能特性を理解し、ソフトウェア設計に活かすことが肝要
おわりに
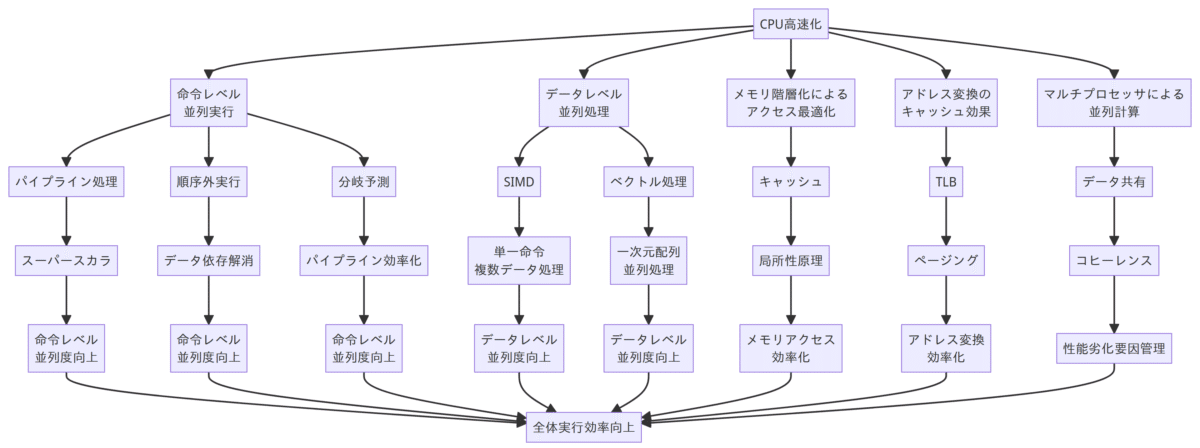
本書を通じて、CPUの高速化を実現する様々なハードウェアとソフトウェア上の技術について学ぶことができました。
命令実行効率化のために、深くパイプライン化して複数の命令を並列処理するスーパースカラ化が進められています。命令のデータ依存関係を極力緩和してアウトオブオーダーで効率的に実行する仕組みも取り入れられています。
分岐の方向予測によって、分岐のコストを隠蔽しつつ命令流の連続性を保つ工夫もなされています。データ処理効率化のために、SIMD命令やベクトル処理機能が実装され、一度に複数のデータを並列に操作することで、演算性能が大幅に向上しています。アルゴリズム次第では10倍以上の速度向上が可能です。
メモリアクセス効率化のために、高速なキャッシュメモリの階層化が進められています。データの局所性を意識してこのキャッシュを効果的に利用することが性能向上につながります。仮想記憶ではTLBのキャッシュ効果が重要です。
そして、これらのハードウェアを最大限に生かすために、ソフトウェアからの効果的な制御が不可欠です。命令のスケジューリング、データの配置、並列度の最適化など、ソフトウェア次第でCPUの実行効率は大きく左右されます。
今後のシステム開発では、このようなCPUアーキテクチャの理解と、ソフトウェアによる制御が欠かせないと感じました。最新のマルチコアCPUを活用するには、ソフトウェアとハードウェアの協調的な最適化が不可欠であることがわかりました。本書で学んだことを生かし、CPUリソースを最大限に引き出せる高速なシステム開発を目指したいと思います。
以上、本書の核心を図示し、CPU高速化技術を多角的に要約しました。今後の研鑽に役立てていきたいと考えています。
