
アラサーエンジニア シティボーイ化計画 - 都会のお得物件を統計的に探してみる -

はじまり
この note を運営しているピースオブケイク社でエンジニアをしている hanaori です。少し前から統計学を勉強中でして、現実世界に当てはめて試せそうな題材を探している毎日を過ごしています。
そんな折、「弊社CTOが引っ越しを検討している」という話を聞き、
CTOの引越し先としてコスパの良い物件を、統計を使って探し出しだす
のはどうかとひらめいてしまいました 😆
そこで、重回帰分析を用いてコスパに優れる物件を洗い出していきたいと思います。
今回探す物件の条件
ここで今回対象とする物件の条件を確認しておきます。
・ ジムが近い(→ 狙いは東京体育館)
・ 最寄り駅は千駄ヶ谷
・ 高すぎる物件はちょっと・・・(一旦20万より下で設定)
物件データを可視化する
今回は千駄ヶ谷駅周辺の物件データを用意しました。
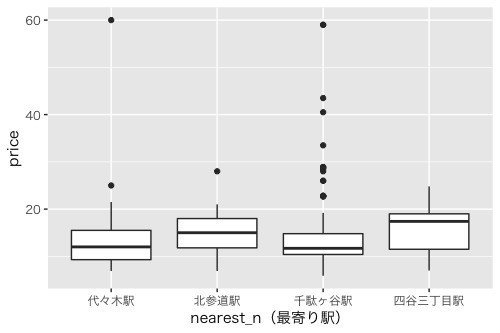
最寄り駅ごとに箱ひげ図を描いてみると駅ごとに賃料の分布が異なりそうなことが分かります。
→ 最寄り駅が千駄ヶ谷の物件のみを対象にする
さらに、20万円以上は外れ値&今回想定する価格帯からも外れます。
→ 価格が20万円以上の物件は省く
次に最寄りが千駄ヶ谷駅の物件を散布図に描いて見てみましょう。
・ 賃貸価格(price)と専有面積(space)の相関が 0.8 以上と高い正の相関がある
・ 築年数(years)は弱い負の相関が見られる
・ 物件のある階(floor)、駅からの距離(nearest_d)は物件の価格との相関があまりなさそう
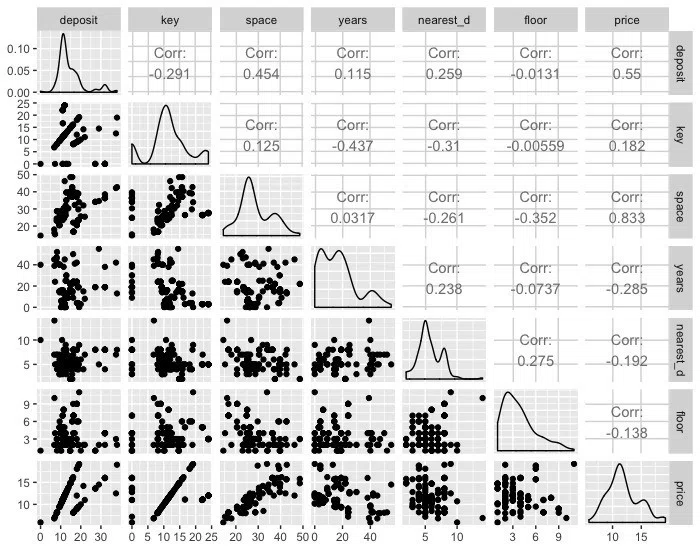
※ 各変数の意味はこちらになります。

重回帰で物件価格の予想モデルを作る
粗方データをきれいにしたら、いよいよ重回帰分析に移ります。

物件の価格を各物件の専有面積・築年数・最寄り駅までの距離(分)・物件の位置する階という4つの説明変数の大小で予測・説明できるようRでモデルを作成します。
物件のある階(floor)、駅からの距離(nearest_d)に関しては相関が弱いのですが、弱くても多少の関係があるのではないかと思い今回は説明変数に入れています。
> result_lm <- lm(price ~ space + years + nearest_d + floor, data = data)
> summary(result_lm)
Call:
lm(formula = price ~ space + years + nearest_d + floor, data = result_under20)
Residuals:
Min 1Q Median 3Q Max
-3.5701 -0.6874 -0.0102 0.5070 5.6142
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.620205 0.607636 2.666 0.008491 **
space 0.346157 0.014183 24.407 < 2e-16 ***
years -0.067430 0.007451 -9.049 6.17e-16 ***
nearest_d 0.127925 0.056481 2.265 0.024922 *
floor 0.170909 0.047589 3.591 0.000443 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 1.173 on 153 degrees of freedom
Multiple R-squared: 0.8189, Adjusted R-squared: 0.8142
F-statistic: 173 on 4 and 153 DF, p-value: < 2.2e-16決定係数(Adjusted R-squared)は0.8以上で良さそうに見えますが、本当にこれで良いとしていいか重回帰の結果をプロットして見てみます。

外れ値があるとモデルの精度に影響が出るので除いていきます。
なんだか75番が著しく外れていますね。調べてみるとどうやら価格が間違っているようなので除去・・・。
80番は専有面積の広さが間違ってるっぽい、除去します(入力ミス発見器のようだ)。
※ ネットで見る物件情報にはたまに価格や専有面積を間違えて載せている場合があるよ。妙な外れ値がある場合は要注意ですね。
---------------
さてさて、入力に間違いがありそうな物件などは省き、改めて重回帰をかけた結果とプロットです。
> summary(result_lm)
Call:
lm(formula = price ~ space + years + nearest_d + floor, data = result_under20)
Residuals:
Min 1Q Median 3Q Max
-3.6415 -0.6100 -0.0208 0.5288 3.5296
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.534929 0.560168 2.740 0.00688 **
space 0.346051 0.013122 26.371 < 2e-16 ***
years -0.064999 0.006886 -9.439 < 2e-16 ***
nearest_d 0.148303 0.052141 2.844 0.00507 **
floor 0.146053 0.044033 3.317 0.00114 **
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 1.08 on 151 degrees of freedom
Multiple R-squared: 0.8419, Adjusted R-squared: 0.8377
F-statistic: 201 on 4 and 151 DF, p-value: < 2.2e-16
決定係数も0.8以上で、さらに先程に比べると normal Q-Q plot の結果も少し直線に近くなりモデルとしてよくなったかなと思います(nomal Q-Q plot について詳しく知りたい方はこちら)。
# 予想価格を求める回帰式
hypo <- 1.580297 + 0.344228 * house$space + (-0.065762 * house$years) + 0.149402 * house$nearest_d + 0.147005 * house$floorお得な物件は?
はい、実際に最新のデータを取得してお得な物件を探して行きましょう!
上記で求めた回帰式に用意した物件の情報を当てはめていきます。
予想価格より安い物件、つまり 実際の賃料 - 予測価格 がマイナスになるものがお得な物件です。
> reasonable_houses[,c('name', 'original_price', 'hypo_price', 'diff')]
# A tibble: 69 x 4
name original_price hypo_price diff
<chr> <dbl> <dbl> <dbl>
1 マイキャッスル千駄ヶ谷 14.8 17.6 -2.80
2 ヴェントヴェルデ 10.2 12.4 -2.16
3 ヴェントヴェルデ101号室 10.2 12.1 -1.87
4 マイキャッスル千駄ヶ谷 15.8 17.6 -1.80
5 グリーングラス千駄ヶ谷 13.9 15.4 -1.46
6 JR中央線千駄ヶ谷駅3階建築3年 10 11.3 -1.26
7 JR総武線千駄ヶ谷駅9階建築14年 15.7 17.0 -1.26
8 ガーラプレシャス神宮外苑前 11.1 12.3 -1.16
9 グリーングラス千駄ヶ谷 15.7 16.8 -1.11
10 JR総武線千駄ヶ谷駅4階建築14年 10.7 11.7 -0.980
# ... with 59 more rowsおお、70件ほどありそうですね。よきよき( ˊᵕˋ )
お得物件を地図に描き出す
今のままでは物件がどこにあるのか分かりづらいので、leaflet というライブラリを用いて地図上にマッピングしました。

これで完璧!(70件あるように見えないけど重なっているものも多い。)
写真では伝わらないですがピンをクリックすると物件の情報が出てくるようにしています。
現地調査
CTO自ら現地を下見に行ってもらいました。いえいいえい・:*+.\(( °ω° ))/.:+
すると突然こんな画像がSlackに。


東京体育館、工事中・・・
なんやて・・・、もはや千駄ヶ谷に引っ越す意味なし(´°ω°)(´°ω°)
(物件条件は 『ジムが近い(狙いは東京体育館)』)

先は長いようだ。
しょうがないから他の場所を見てみる
仕方ないので千駄ヶ谷は諦めましょう。
ある程度柔軟に駅を選択できるよう、会社周辺の区(渋谷区・港区)の物件データを手元に用意しました。

高いところだと200万円以上の物件もありますね。
高すぎる物件は今回のターゲットから外れるため省きます。
また価格の外れ値がありすぎると重回帰の結果(normal Q-Q plotなど)がきれいにならなかったため、以下の条件で値を省いていきます。
・ 20万円以上の物件は削除
・ normal Q-Q plotで顕著に外れている値の削除
CTOはシティボーイを目指しているらしいので次のターゲットは表参道に決定。
重回帰で港区・渋谷区各駅の予測モデルを一気に作成
やはり物件の最寄り駅ごとに賃料の分布が異なりそうです。
ターゲットは表参道ですが後のことを考え、港区と渋谷区の各駅ごとに一気に重回帰を回しておくことにします(サンプル数があまりに少ない駅のものは省きました)。
# result_allに港区・渋谷区の物件情報を格納
> head(result_all)
name price deposit key space type direction years nearest_n nearest_d floor
1 0913オークテラスKY 9.3 9.3 9.3 22.41 1K 南 13 代々木八幡駅 10 3
2 12月の森スタシオン 13.3 13.3 13.3 35.84 1DK 南 26 広尾駅 10 3
3 12月森スタシオン 13.3 13.3 13.3 35.84 1DK 南 25 広尾駅 9 3
4 12月森スタシオン 13.3 13.3 13.3 35.84 1DK 南 26 広尾駅 9 3
5 272Bldg 5.6 5.6 0.0 8.11 <NA> 南東 21 代々木公園駅 7 3
6 88HANEZAWA 13.9 13.9 0.0 24.66 <NA> 南東 0 広尾駅 18 5
# 重回帰実行
> each_lm <- function(data) {
lm(price ~ space + years + nearest_d + floor, data = data)
}
> res_with_all_stations <- result_all %>% split(.$nearest_n) %>% map(.f = each_lm)
# 表参道の結果
> summary(res_with_all_stations$表参道)
Call:
lm(formula = price ~ space + years + nearest_d + floor, data = data)
Residuals:
Min 1Q Median 3Q Max
-4.0283 -0.9389 -0.0327 0.9998 4.1674
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 3.782783 0.640385 5.907 7.59e-09 ***
space 0.380353 0.012601 30.185 < 2e-16 ***
years -0.071409 0.007356 -9.708 < 2e-16 ***
nearest_d -0.070602 0.035299 -2.000 0.0462 *
floor 0.273518 0.032429 8.434 6.56e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 1.53 on 390 degrees of freedom
Multiple R-squared: 0.8045, Adjusted R-squared: 0.8025
F-statistic: 401.1 on 4 and 390 DF, p-value: < 2.2e-16決定係数も0.8以上あり、まずまず。
plotの結果も見てみましょう。

normal Q-Q plotから見てもかなり観測データが正規分布に従ってると言えそうです(だいぶきれい)。
お得物件を見つける
では最新の表参道の物件を上記で得られた回帰式に当てはめてみましょう。
前回同様予想価格より安い物件が今回お目当てのお得物件です。
価格は20万以下のものに限定しました。
# A tibble: 150 x 3
original_price hypo_price diff
<dbl> <dbl> <dbl>
1 12 19.7 -7.67
2 12 19.7 -7.67
3 12 19.7 -7.67
4 12 19.7 -7.67
5 12 19.7 -7.67おおお、150件くらいありそう。
位置情報がわかりにくいので地図に描き出しましょう。

こう見ると表参道も結構住めるところがある!
現地調査団結成
今回は、弊社CTO konpyu、ディレクター tama、わたくし hanaoriで現地に乗り込みました。

まずは南青山側の物件を調査しに行くことにします。
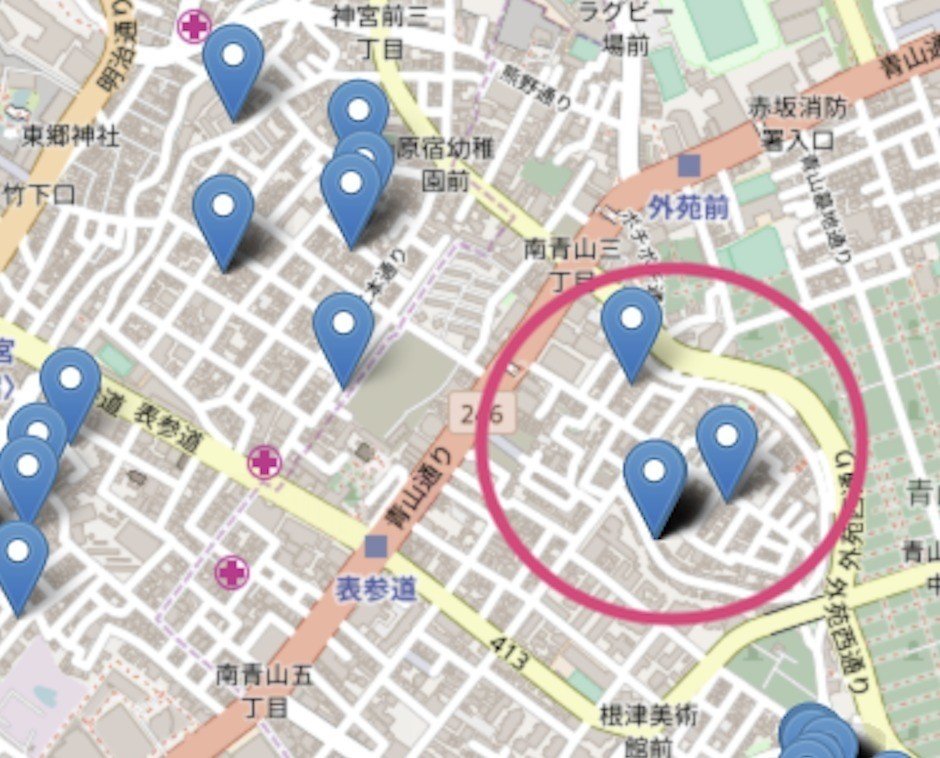


写真からは伝わりづらいかもしれないけれど、すごく変わった物件多い。色が派手だったりやたら緑茂ってたり。
個性豊かなエリアなんですね…。noteの多様性に通ずるものを見ました!
お目当ての物件もかなりの曲者。
・ 大家さんと同居?物件
・ 玄関に謎のbarスペースのようなカウンターがある物件(それより宅配ボックスを置いてほしいと思うのは我儘だろうか)
・ アパートの治安が少々不安になる物件
こういうところが予測より安くなる原因なのですかね。
これは実際見てみないとわからないです。おもしろい 👀
お次は神宮前側。
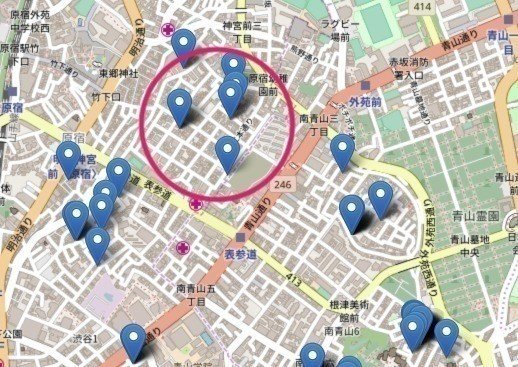

南青山と毛色がちがう!
あの個性派な物件を見た後なせいか、とてもまっとうな物件が多いように見えます。
ここ何週間かずっと募集されてる物件があって、条件も悪くないのになぜだろうと思ってたのですが、物件裏が長期の工事中のようでした。なるほど。


LATTESTでほっこり。
台風が近づいているので今日はここまで。解散!
現地を見る重要性
実際に現地を見ることがかなり大切なんだと気づかされました。
コード上で結果を出してお得✨と飛びつくのはやめたほう無難そう。
その物件がなぜ予測より安いのか、自分の目で見て確認することが大切ですね。
重回帰の限界
今回ばらつきを抑えるため1駅ずつ重回帰を行いました。しかし違う駅で探したくなることも大いにあり得ます。
そうしたときに柔軟に対応できなかったのが今回少し残念でした。
今回は引っ越しの期限が決まっていたため違うモデルを試す時間があまりありませんでしたが、そういった反省を踏まえてもう少し他の方法を探ってみようかなと思います。
結局どこに決めたのか
記事を出す前に物件が決まったようです。めでたい 🎉
その上記事投稿前に候補物件近くにジムがあたらしくできました。CTO引き寄せてますね。
この記事で物件を推薦されたkonpyuです。結局、おすすめされたお得物件の一つに決めまして、先週契約を済ませてきました。物件選びのヒントになりまして助かりました。
お得物件に住めるなら住みたいですよね。本稿では平均より残差が下に大きいほどお得物件だと解釈したわけですが、不動産のプライシングはよくできたもので、何らかの「ワケあり」で安くなってる物件がほとんどでした。
逆に、残差の上の方、つまりお得じゃない方を狙ってみるのも面白そうです。割高に思える物件にはその理由にふさわしい魅力的なポイントがあるのでしょうね。
Special Thanks
konpyu:身を挺して実験に付き合ってくれるすばらしいCTO
tama:最近カメラの沼に自ら望んでハマりに行った名カメラマン
utaka233:弊社で統計を教えてくれてる先生。どれだけあほなことを言っても見捨てない優しさの持ち主。今回もいろいろアドバイスいただきました。
シティボーイになる他にタワマンに住む夢もあるようなのでこの勢いで叶うといいですね。
いいなと思ったら応援しよう!
