
【ComfyUI + AnimateDiff】SparseCtrlで一貫性のあるAIアニメーション作れるんじゃね?

ComfyUI + AnimateDiffで、AIイラストを
4秒ぐらい一貫性を保ちながら、
ある程度意図通りに動かしたいですよね!
でも参照用動画用意してpose推定はめんどくさい!
そんな私だけのニーズを答えるワークフローを考え中です。
まだワークフローが完成したわけでもなく、
日々「こうしたほうが良くなるな」の繰り返しなのですが、
備忘録として現状のワークフローを紹介したいと思います。
ちなみ今回の完成イメージはコレです。
ピザを食べるメイドさん。

AnimateDiffの課題
AnimateDiff v3は16フレーム動画で学習されてるらしいので16フレーム以上のアニメ、たとえば32フレームのアニメをテキストベースで作ると、16フレームアニメと16フレームアニメを無理やりくっつけた、みたいな動きになるんですよ。

よくあるAIアニメ
とくにアニメ系モデルは動きや一貫性の制御が難しい!
そのために、16フレーム以上のアニメを作る際はControlNet等で一貫性を保つ工夫を入れてやる必要があるんです。
その方法は色々あって、いろいろ試してる状態です。
やはり動画からvideo2videoはそれなりに安定しますし、
動画から人の動きのOpenPose(DW pose)を抜き出すとかなり安定します。

ただね、動画から動画作る系、
めんどくさいんですよ!!!!
動画を用意しないといけないから!!!!
そこで、動画を用意しなくて良い、
そこまで大変でないワークフローを考えてみることにしました。
▼考え方▼
1️⃣ アニメ系モデルでアニメーションが難しいので
まず実写系モデルを使う
実写系モデルで、ベースとなる静止画を作る
↓
2️⃣ 動画のキーフレームとなる静止画を数枚作る
(その際、"1"の生成画像をIPAdaptorで一貫性を出す)
↓
3️⃣ それらの静止画を「SparseCtrl」という謎技術に参照させて
中割として機能させ、一本の実写風動画を作る
↓
4️⃣ その"3"でできた動画からDepthとOpenPoseを推定し、
それをもとにアニメ動画を作る
つまり1️⃣・2️⃣・3️⃣・4️⃣の4つのワークフローができます。
ちなみに背景は今回気にしてないです。
個人的な考え方として、背景も人物も一発で作ると碌な目にあわない。なので別々に作って人物をRemBG系処理で抜いて背景と合成させるほうが良いかと考えています。
1️⃣ 実写系モデルでベースとなる静止画を作るワークフロー

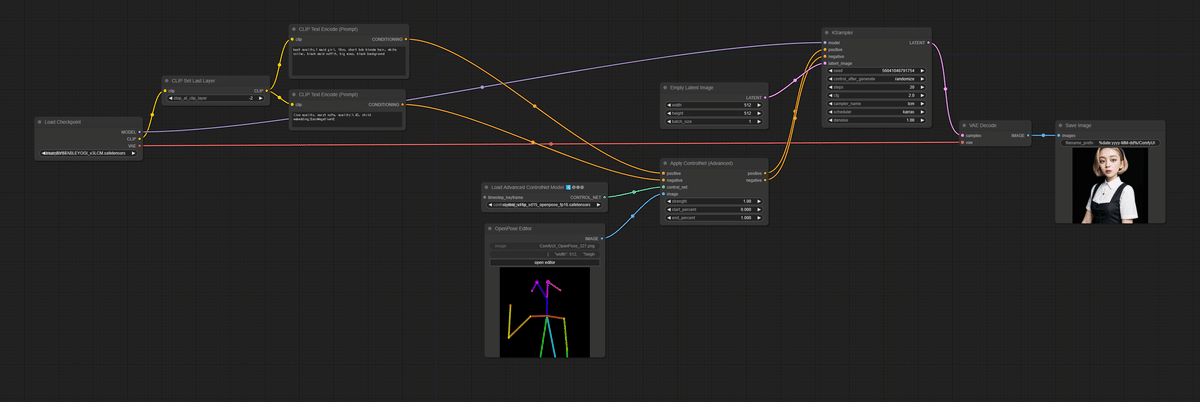
ワークフローは別段ややこしいことはせず。
最終的につくりたいアニメのイメージを想定しながら元絵をつくります。
ワークフロー"2"でポーズを動かせるようにするためにこの時点でControlNetでOpenPose Editorでベースのポーズも作っています。OpenPose Editorは便利なのでインストールしてね。
実写と比較してアニメは顔が大きくなりがちなので、この時点で小顔にならないように、OpenPose Editorで顔を大きめに作ると良いです。
ちなみにモデルは実写系LCMモデル「DREAM_BY_STABLE_YOGI(v3+LCM)」を使ってます。早いといろいろ試せるからねぇ。
LCMモデルを使うときはKSamplerのsampler_nameを「lcm」にしてcgfを「2」とかに下げてください。
2️⃣ キーフレームとなる静止画を作るワークフロー

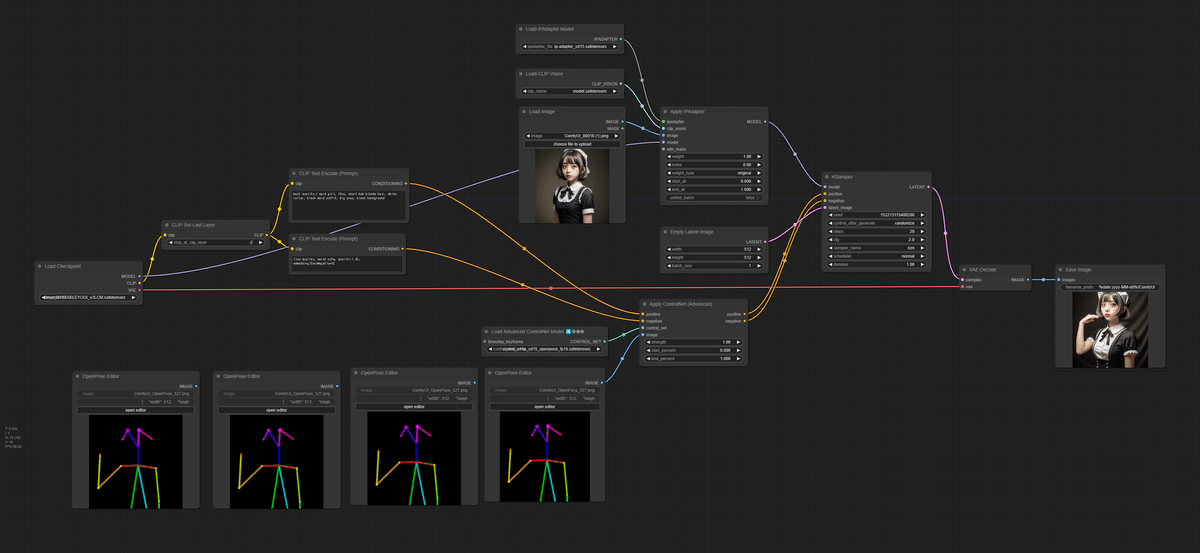
ワークフロー”1”にIPAdapterがついただけで、ほぼ変更はなしですね。
ここのOpenPose Editorでポーズを変えたものをつくって、4枚のキーフレーム画像を作っています。
3️⃣ SparseCtrlを使って実写風動画を作るワークフロー

ウネウネは気にしない
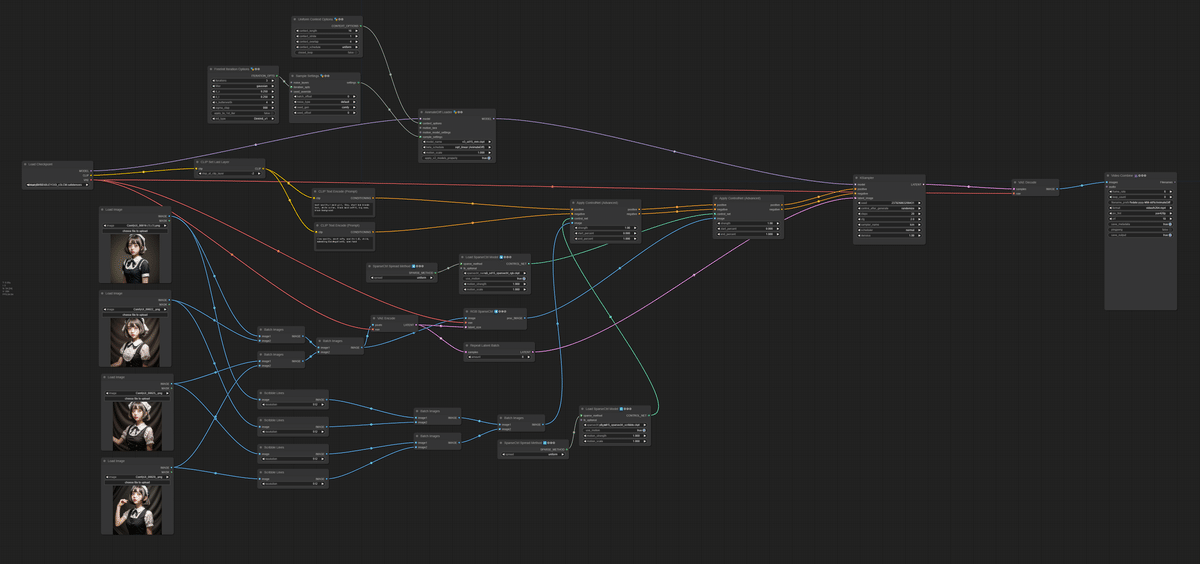
SparseCtrlは謎技術なんですがAnimateDiffで参照させると、超強力にその絵を取り込んでくれる技術です。エンコーダーが必要なので下記で入手してください。
「RGB(画像を参照)」と「Scribble(ラフ画を参照)」という2つの参照方法があって、それぞれ特徴があるんですが、詳細はよくわからん。toyxyzさんがたまに解説を呟いてるので、そのポストを追ってくれぃ。
SparseCtrl is a feature added in AnimateDiff v3 that is useful for creating natural motion with a small number of inputs. Let's take a quick look at how to use it! pic.twitter.com/dLZrjJwMCC
— toyxyz (@toyxyz3) December 25, 2023
SparseCtrlをComfyUIで扱えるようにするためにComfyUI-Advanced-ControlNetをインストールしてね。
あとAnimateDiffのアニメが安定する謎技術「FreeInt」もこの機会に使ってしまいましょう。ComfyUI-AnimateDiff-Evolvedで扱えるはず。
まぁ、なくてもいいけど。(使うと商用利用がダメだった気がする)
このワークフローでは4枚の中割用画像を使ってSparseCtrlを「RGB」と「Scribble」両方で参照させています。
RGBだけだと中割のつなぎが汚くなるので、Scribbleも通したほうが自然になります。
Scribbleで参照する際は、そのままだとラフ絵じゃないので「ScribblePreprocessor」を通しています。
画像2枚以上参照させるにはVideoHelperSuiteのLoad Imagesあたりが良い気がするんですけど、面倒なんで「Batch Image」をタコ足配線したら動きました笑
この場合、4枚の画像が等間隔で中割元として参照されます。SparseCtrl Spread Methodで参照タイミング変えれた気がするけど、よく分かってないのでtoyxyzさんのポストを追ってください。
(このあたりの情報が2024年1月時点で全然見つかってないのでtoyxyzさんはマジで解説を書いてほしい‥)
動画にまとめるのは「VideoHelperSuite」の「Video Combine」を使いますが、便利すぎてもうほかの保存方法に戻れなくなります。gifやmp4にまとめてくれます。
ちなみに、生成動画を見ていただくと、結構、服やら帽子がグニャグニャしていますが、ワークフロー"4"では、そこはあまり使わないので気にしないでください。もちろん、この時点で一貫性があるに越したことはないですが、この程度の荒ぶりならワークフロー"4"でごまかせます。
4️⃣ 実写風動画をPose・Depth推定でアニメ化

PromptScheduleでピザを食べるように改良。


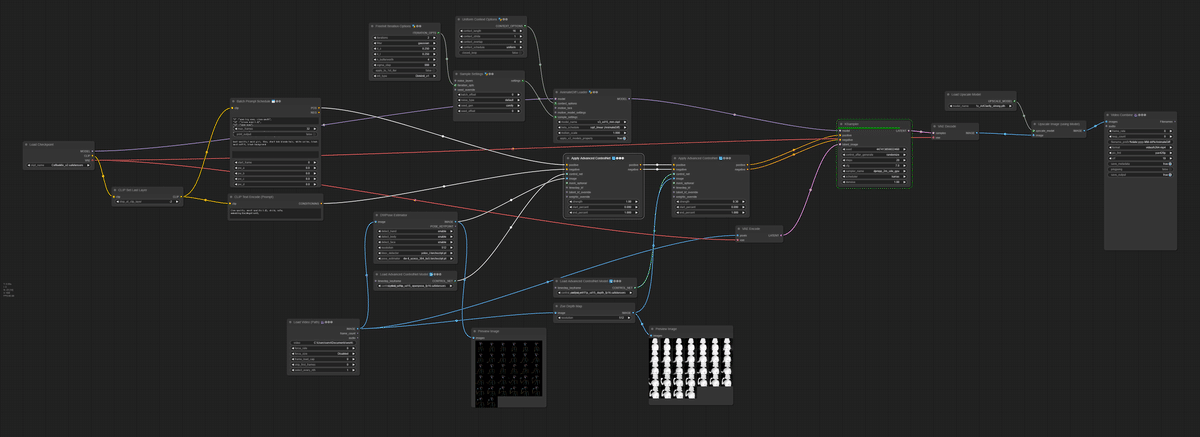
前提として、アニメ系モデルを使う際に、異常に描き込み系やキラキラする系のモデルは向いてないです。アニメにノイズが混じってきます。
なので私は絵がパキッと出る「CoffeeMix」を使っています。
ここではワークフロー"3"でできた動画をPose推定とDepth推定して、その推定結果をControlNetで使っています。
Depth推定は「comfy_controlnet_preprocessors」の「Zoe-DepthMapPreprocessor」を使ってるんですが、処理が重い分、めちゃくちゃ推定が精緻です。すごい。
また「瞬き」や「ピザを食べる」などの演出は「FizzNodes」の「Batch PromptSchedule」でテキストでフレームごとに指示を追加しています。
(「PromptSchedule」」だとなぜか機能しない‥)
KSampler後に「ArtClarity」という1倍のアップスケーラーでくっきりさせています。
工程は以上です。お疲れ様でした。
結論
結局、あんまり簡単ではない。
まぁベースだけ組んじゃえば、あとは融通が効くかなと思います。
ただもっと良い方法がありそうだし、
日々新たな手法が生まれるだろうから、検証の旅は一生続くわけですね。
面倒だなと思った人はPikaを使いましょう。