Stage4 深層学習 Day4

1. 強化学習
1-1. 強化学習とは
長期的に報酬を最大化できるように環境のなかで行動を選択できるエージェントを作ることを目標とする機械学習の一分野。行動の結果として与えられる利益(報酬)をもとに、行動を決定する原理を改善していく仕組みです。
また、強化学習と通常の教師あり、教師なし学習との違いは、目標である。教師なし、あり学習では、データに含まれるパターンを見つけ出すおよびそのデータから予測することが目標。一方、強化学習では、優れた方策を見つけることが目標。
環境について事前に完璧な知識があれば、最適な行動を予測し決定することは可能であるが、強化学習では不完全な知識を基に行動しながら、データを収集し最適な行動を見つけていく。
・Q学習
行動する毎に行動価値関数を更新することにより学習を進める手法。
・関数近似法
価値関数や方策関数を関数近似する手法。
2. Alpha Go
Deep Mindが開発した囲碁プログラム。また、過去の試合データを使用せず、自己対戦の強化学習のみで学習したAlpha Zeroも開発された。
2-1. Alpha Go
Alpha Goの学習プロセスは、下記のステップで進む。
1. 教師あり学習によるRollOutPolicyとPolicyNetの学習
2. 強化学習によるPolicyNetの学習
3. 強化学習によるValueNetの学習
・Alpha GoのPolicyNet
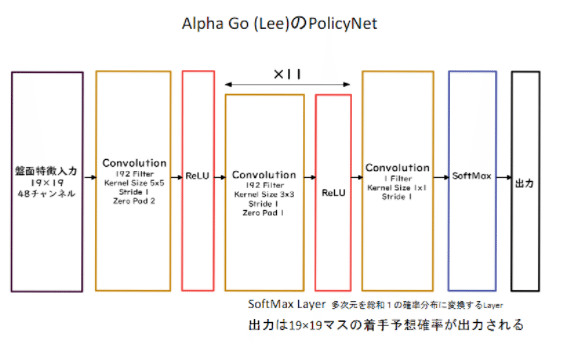
入力は、19×19で、48チャンネルである。
ネットワークは、CNNで、softMaxによって19×19の着手予想確率を出力する。入力の48チャンネルはそれぞれ下記のような入力に対応する。

・RollOutPolicy
PolicyNetはニューラルネットネットワークなので、盤面の推論の際の計算量が多く時間がかかるため、RollOutPolicyを使用する。RollOutPolicyの入力は以下である。

・PolicyNetの教師あり学習
KGS Go Server(ネット囲碁対局サイト)の棋譜データから300万局面分の教師を用意し、教師と同じ着手を予測できるよう学習を行った。
具体的には、教師が着手した手を1とし、残りを0とした19×19次元の配列を教師とし、それを分類問題として学習した。
この制度で作成したPolicyNetは57%程度の精度である。
・PolicyNetの強化学習
PolicyNetの強化学習の過程を500Iterationごとに記録し保存して、PolicyPoolを作る。
次に現状のPolicyNetとPolicyPoolからランダムに選択されたPolicyNetと対局シミュレーションを行い、その結果を用いて方策勾配法で学習を行う。
現状のPolicyNet同士の対局ではなく、PolicyPoolに保存されているものとの対局を使用する理由は、対局に幅を持たせて過学習を防ごうというのが主たる理由である。
この学習をmini batch size 128で1万回行った。
・ValueNetの学習
PolicyNetを使用して対局シミュレーションを行い、その結果の勝敗を教師として学習する。
教師データ作成の手順は、
1. まずSL PolicyNet(教師あり学習で作成したPolicyNet)でN手まで打つ。
2. N+1手目の手をランダムに選択し、その手で進めた局面をS(N+1)とする。
3.S(N+1)からRL PolicyNet(強化学習で作成したPolicyNet)で終局まで打ち、その勝敗報酬をRとする。
S(N+1)とRを教師データ対とし、損失関数を平均二乗誤差とし、回帰問題として学習した。この学習をmini batch size 32で5000万回行った。
N手までとN+1手からのPolicyNetを別々にしてある理由は、過学習を防ぐためである。
・モンテカルロ木探索
min-max探索やαβ探索では、盤面の価値や勝率予想値が必要だが、囲碁では
盤面価値や勝率予想値を出すことが困難とされてきた。
そこで、盤面評価値によらず、末端評価値、つまり勝敗のみを使って探索を行うという発想で生まれた探索法である。囲碁の場合、他のボードゲームと違い、最大手数はマスの数でほぼ限定されるため、末端局面に到達しやすい。
具体的には、現局面から末端局面までをPlayOutと呼ばれるランダムシミュレーションを多数回行い、その勝敗を集計して着手の優劣を決定する。
また、該当手のシミュレーションが一定数を超えたら、その手を着手した後の局面をシミュレーション開始局面とするよう、探索気を成長させる。
この探索木の成長を行うという点が、モンテカルロ木探索の優れているところである。
モンテカルロ木探索は、この木の成長を行うことによって、一定条件下では探索結果は最善手を返すことが理論的に証明されている。
Alpha Go(Lee)のモンテカルロ木探索は、選択、評価、バックアップ、成長という4つのステップで構成されている。
2-2. AlphaGo Zero
・AlphaGo(Lee)とAlphaGo Zeroの違い
1. 教師あり学習を一切行わず、強化学習のみで作成
2. 特徴入力からヒューリスティックな要素を排除し、石の配置のみにした
3. PolicyNetとValueNetを1つのネットワークに統合した
4. Residual netを導入した
5. モンテカルロ木探索からRollOutシミュレーションをなくした
・AlphaGo Zeroの学習法
AlphaGo Zeroの学習は、自己対局による教師データの作成、学習、ネットワークの更新の3ステップで構成される。
1. 自己対局による教師データの作成
現状のネットワークでモンテカルロ木探索を用いて自己対局を行う。
まず30手までランダムで打ち、そこから探索を行い、勝敗を決定する。
自己対局中の各局面での着手選択確率分布と勝敗を記録する。
教師データの形は、(局面、着手選択確率分布、勝敗)が1セットとなる。
2. 学習
自己対局で作成した教師データを用い、学習を行う
NetworkのPolicy部分の教師に着手選択確率分布を用い、Value部分の教師に勝敗を用いる。
損失関数はPolicy部分はクロスエントロピー、Value部分は平均二乗誤差。
3. ネットワーク更新
学習後、現状のネットワークと学習後のネットワークとで対局テストを行い、学習後のネットワークの勝率が高かった場合、学習後のネットワークを現状のネットワークとする。
3. 軽量化・高速化技術
3-1. 分散深層学習
深層学習は多くのデータを使用したりパラメータ調整に多くの時間を使用する。高速な計算が必要。そのため、データ並列化、モデル並列化、GPUによる高速技術が不可欠である。
・データ並列化
1. 同期型
各ワーカーの計算が終わるのを待ち、全ワーカーの勾配が出たところで勾配の平均を計算して親モデルのパラメータを更新する。
2. 非同期型
各ワーカーはお互いの計算を待たず、各子モデルごとに更新する。
学習が終わった子モデルはパラメータサーバにpushされ、新たに学習を始める時は、パラメータサーバから pop したモデルに対して学習していく。
非同期型は処理のスピードが早い。ただし、最新のモデルのパラメータを利用できないので、学習が不安定になりやすい。なお、同期型の方が精度が良い。
・モデル並列化
親モデルをワーカーに分割し、それぞれのモデルを学習させる。
全てのデータで学習が終わった後で、一つのモデルに復元する。
・GPUによる高速化
GPGPU の開発環境はDeep Learningフレームワーク(Tensorflow, Pytorch)で実装されているので、使用する際は上記を指定すれば良い。
3-2. モデルの軽量化
モデルの精度を維持しつつ、パラメータや演算回数を低減する手法。モデルの軽量化は計算の高速化と省メモリ化を行うためモバイル,IoT 機器と相性が良い手法になる。
代表的な手法は量子化、蒸留、プルーニング。
・量子化
64bit浮動小数点を 32 bit など下位の精度に落としてメモリと演算処理を削減する。メリットは計算の高速化、省メモリ化。デメリットは制度の低下。
・蒸留
精度の高いモデルはニューロンの規模が大きなモデルで、推論に多くのメモリと演算処理が必要。そこで規模の大きなモデルの知識を使って軽量なモデルの作成をする。
・プルーニング
モデルの精度に寄与が少ないニューロンを削除することでモデルの軽量化・高速化を見込める。
4. 応用モデル
4-1. MobileNet
Depthwise Convolution と Pointwise Convolution を用いて軽量化・高速化・高精度化したモデル。全体の計算量はDepthwise Convolutionの計算量+Pointwise Convolutionの計算量となる。
4-2. DenseNet
Dense Convolutional Networkは、畳込みニューラルネットワークアーキテクチャの一種である。ニューラルネットワークでは層が深くなるにつれて、学習が難しくなるという問題があったが、Residual NetworkなどのCNNアーキテクチャでは前方の層から後方の層へアイデンティティ接続を介してパスを作ることで問題を対処した。DenseBlockと呼ばれるモジュールを用いた、DenseNetもそのようなアーキテクチャの一つである。
4-3. 正規化
ミニバッチ単位で平均が0、分散(標準偏差)が1になるように正規化。
学習時間の短縮や初期値への依存低減、過学習の抑制効果がある。ただし、バッチサイズに影響を受けるため、バッチサイズが小さいと学習が収束しないこともある。このバッチサイズはマシンスペックによって調整せざるを得ないため、正確に効果を確認しづらくなる。
4-4. WaveNet
時系列データに畳込みニューラルネットワーク(Dilated Convolution)を用いた音声生成モデル。次元間でのつながりがある場合、畳込みができる。また、畳込みは2次元(画像)だけでなく1次元や3次元等も可能。
<確認テスト>
深層学習を用いて結合確率を学習する際に、効率的に学習が行えるアーキテクチャを提案したことがWaveNet の大きな貢献の1 つである。提案された新しいConvolution 型アーキテクチャは(あ)と呼ばれ、結合確率を効率的に学習できるようになっている。(あ)を用いた際の大きな利点は、単純なConvolution layer と比べて(い)ことである。
<回答>
(あ)Dilated causal convolution(い)パラメータ数に対する受容野が広い
5. Transformer
RNNを使用せず、Attentionのみ使用しているモデル。機械翻訳のみならず様々な自然言語処理で使用されている。構成としてはエンコーダーとデコーダーに分かれており、エンコーダーでは、Positional Encodingで単語ベクトルに単語の位置情報を付加し、それに対してAttention機構をかけて全結合層に流す。デコーダーでは、未来の単語を見ないようにマスクをする機構が入っている。エンコーダーもデコーダーもAttenntionはSelf-Attentionを用いて、正規化としてLayer Normalizationが用いられる。
<実装演習>
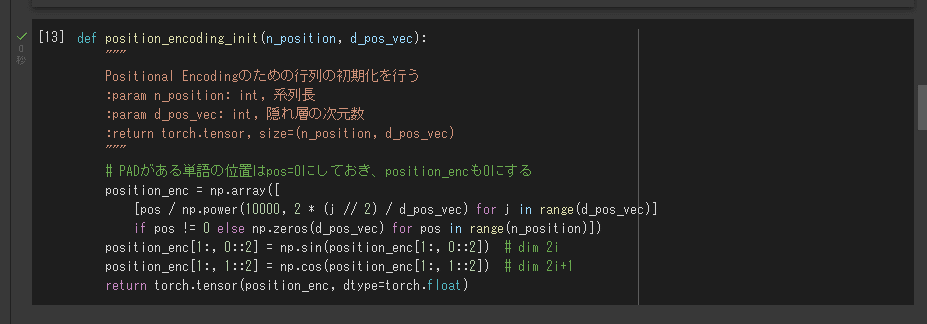
① Position Encoding
Transformerは系列の処理にRNNを使用しないので、そのままでは単語列の語順を考慮することができない。そのため入力系列の埋め込み行列に単語の位置情報を埋め込むPosition Encodingを加算する。
② Multihead Attention
ソース・ターゲット注意機構と自己注意機構 Attentionは一般に、queryベクトルとkeyベクトルの類似度を求めて、その正規化した重みをvalueベクトルに適用して値を取り出す処理を行います。


③ Position-Wise Feed Forward Network
単語列の位置ごとに独立して処理する2層のネットワーク。

④ Masking
TransformerではAttentionに対して2つのマスクを定義する。

6. 物体検知・セグメンテーション
・広義の物体認識タスク

・代表的なデータセット

・分類問題における評価指標

・IoU(Intersection over Union)
物体検出においてはクラスラベルだけでなく、物体位置の予測精度も評価したいので、それをConfusion Matrixの要素を用いて表現したものをIoU(Intersection over Union)である。IoUの定義は、以下の通り。

・mAP(mean Average Precision)

・物体検出のフレームワーク

・SSD(Single Shot Detector)
SSD(Single Shot Detector)の肝となるのは、「デフォルトボックス(default boxes)」という長方形の「枠」である。 一枚の画像をSSDに読ませ、その中のどこに何があるのか予測させるとき、SSDは画像上に大きさや形の異なるデフォルトボックスを8732個乗せ、その枠ごとに予測値を計算する。
・Semantic Segmentation
Up-samplingの壁
コンボリューション+プーリングを経ることで解像度が下がっていくので、SSを行うためにはアップサンプリングが必要になる。
この記事が気に入ったらサポートをしてみませんか?