
Photo by
denwa_uranai1
1.58bit量子化: Llama3-8B-1.58-100B-tokensを試す

なにやら目を離している隙にxが騒がしい。
以前にMicrosoft Researchが発表していたLLMの3進値 log3≒1.58bit量子化手法を、Llama3-8bに適用して100Bトークンでファインチューニングしたモデルと推論フレームワークの bitnet.cpp が公開されていたようです。
わかりやすい解説ブログ記事も公開されていました。
トレーニング時はdetach()を使うことで、順伝播(forward ) では量子化した値を使用して、逆伝播時(backward ) には、量子化部分は無視させて、元の値 x_norm, w のみを用いて、量子化による不連続性を気にせずに勾配を計算できるようにしてるのかー。なるほど!
注:detach() は 計算グラフから切り離して勾配が計算されないようにするメソッド
# Adapted from https://github.com/microsoft/unilm/blob/master/bitnet/The-Era-of-1-bit-LLMs__Training_Tips_Code_FAQ.pdf
import torch
import torch.nn as nn
import torch.nn.functional as F
def activation_quant(x):
scale = 127.0 / x.abs().max(dim=-1, keepdim=True).values.clamp_(min=1e-5)
y = (x * scale).round().clamp_(-128, 127) / scale
return y
def weight_quant(w):
scale = 1.0 / w.abs().mean().clamp_(min=1e-5)
u = (w * scale).round().clamp_(-1, 1) / scale
return u
class BitLinear(nn.Linear):
"""
Only for training
"""
def forward(self, x):
w = self.weight
x_norm = LN(x)
# A trick for implementing Straight−Through−Estimator (STE) using detach()
x_quant = x_norm + (activation_quant(x_norm) - x_norm).detach()
w_quant = w + (weight_quant(w) - w).detach()
# Perform quantized linear transformation
y = F.linear(x_quant, w_quant)
return y
transformersでの実行
transformersを用いた実行例のcolabのノートブックも公開されています。
bitnet.cpp
公式の推論フレームワークの bitnet.cpp は、今のところCPUのみのサポートですが、今後NPUおよびGPUのサポートも予定されているとのことです。
とりあえず、インストールガイドに沿ってWSL上にインストールしてから、スレッド数を16にして実行してみました。
python run_inference.py -m models/Llama3-8B-1.58-100B-tokens/ggml-model-i2_s.gguf -p "Daniel went back to the the the garden. Mary travelled to the kitchen. Sandra journeyed to the kitchen. Sandra went to the hallway. John went to the bedroom. Mary went back to the garden. Where is Mary?\nAnswer:" -n 6 -temp 0 -t 16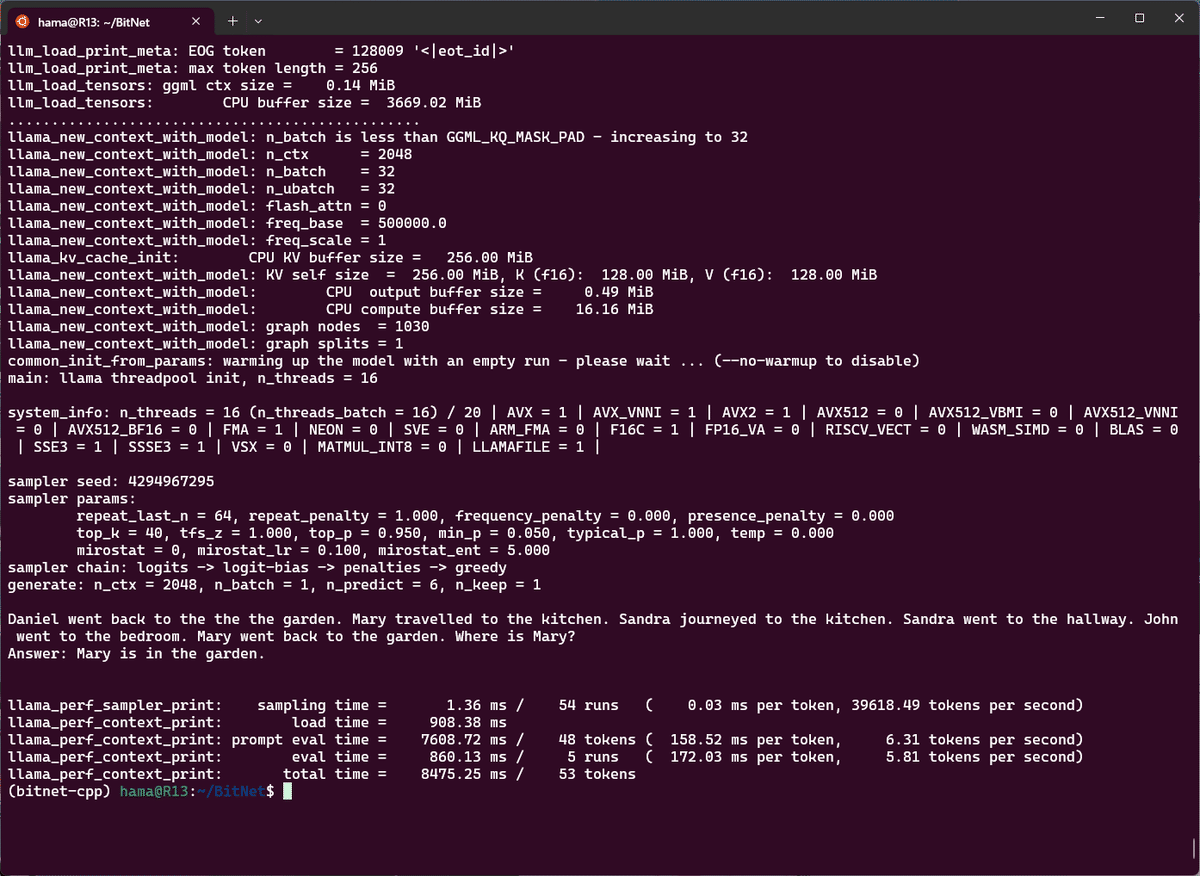
ホントに8BクラスのLLMをCPUだけで推論してるのか!?という感じのレスポンス。もしNPUやGPU上での実行が最適化できれば 、一気にローカル環境でのLLMの普及がすすむかも。とても楽しみですね。
参考記事
BitNetについては以下も参考になれば幸いです。
この記事が気に入ったらサポートをしてみませんか?