
推論時にも学習できるLLM!? 「Titans」

Google Researchからtransformerアーキテクチャの記憶メカニズムを抜本的に改善するモデルアーキテクチャに関する論文が公開されていました。とても興味深かったので概要をまとめてみました。
理解不足も多々あるので、興味を持たれた方はぜひ原文をご確認ください。また、間違いなどあればコメントいただけると幸いです。
1.概要
現状の大規模事前学習言語モデル(LLM)の多くは推論時(テスト時)には学習は行われず、モデル使用時はあくまでも「推論専用」の存在でした。
「Titans: Neural Long-Term Memory for Enhanced Sequence Modeling」では、テスト時(オンライン学習フェーズ)にも新しい情報で学習内容をアップデート、蓄積し、従来のモデルアーキテクチャでは実現が難しかった記憶の忘却が可能な「Neural Memory(ニューラルメモリ)」という機構を提案しています。
従来のTransformerのアテンション機構と「ニューラルメモリ」を組み合わせることで、非常に長いシーケンス(数百万トークン規模)の“干し草の山の中の針”タスク(NIAHタスク:「長大な文章(干し草の山)」に埋もれたごく少数の重要情報(針)を正しく見つけられるか」というタスク)での性能も改善された。
2.Transformerアーキテクチャの課題
従来のTransformerは、アテンション機構を用いて、限られたコンテキストウィンドウ内でトークン同士の依存関係を正確にモデリングできる一方で、コンテキストが長くなる(数万〜数百万トークン)ほど、計算量とメモリ消費量が二乗で爆発的に増えるという問題点が従来から指摘されていました。
また、Transformerを含む多くのモデルは、推論(テスト)時に新しい情報を学習し直すことができず、過去に学習した「固定された知識」のみを使って推論するという制約がありました。
「干し草の山の中の針 (NIAH)」タスクにおいて、既存モデルは、コンテキスト長を増やしても実際に使える有効コンテキスト長がそれほど伸びず、急激に性能低下しがちでした。その理由は、非常に長い文章を処理するうち、重要情報への注意が散漫になり、“針”を正確に取り出せなくためと考えられていました。
3.Titansの改善提案
Titansでは、“人間の脳が持つ短期記憶(ワーキングメモリ)と長期記憶を組み合わせて情報を扱う”というヒントを得て、アテンション機構を「短期記憶」、ニューラルメモリを「長期記憶」として位置づける新しいアーキテクチャを提案しました。
テスト時(オンライン学習フェーズ)にも継続的に情報を学習・記憶・忘却して記憶を更新できるニューラルメモリを備える。
3.1Titansのコアとなる機構
Titansでは以下の3つを機構を組み合わせて、3つのアーキテクチャが提案されています。
①ニューラルメモリ(Neural Memory)
テスト時(オンライン学習フェーズ)にも更新可能
“驚き度”を指標とした学習・忘却メカニズムを備える
過去のトークンと新たに到着するトークンの差分に対する勾配を使い、サプライズが大きい情報を優先的に記憶
ニューラルメモリを実装については、MLPを多層化した深い構造を採用する「ディープメモリ」と提案。層数を増やすと表現力が向上し、長期依存関係をよりうまく捉えられる一方、計算コストは増えるため、層数に応じた性能・効率のトレードオフが存在する。
②永続メモリ(Persistent Memory)
タスクに共通するメタ知識を格納
テスト時にはパラメータの更新は行わず固定
③短期記憶:アテンション機構
Transformerと同様なアテンション機構
全入力トークンを対象にするのではなく、ウィンドウを制限した「スライドウィンドウアテンション (SWA)」を使うアーキテクチャも提案
実装モデルでは1D畳み込みも利用している

3.2 Titansで提案されているアーキテクチャ
①MAC (Memory as a Context)アーキテクチャ
長期メモリを現在の文脈(コンテキスト)に付加する形で利用
シーケンスをセグメント単位で区切り、それぞれに対して過去のメモリを参照

②MAG (Memory as a Gate)アーキテクチャ
スライドウィンドウアテンション(SWA)とニューラルメモリをゲーティング機構で組み合わせ
短期的にはSWAで局所的依存を、高い「驚き度」の情報はニューラルメモリで保持

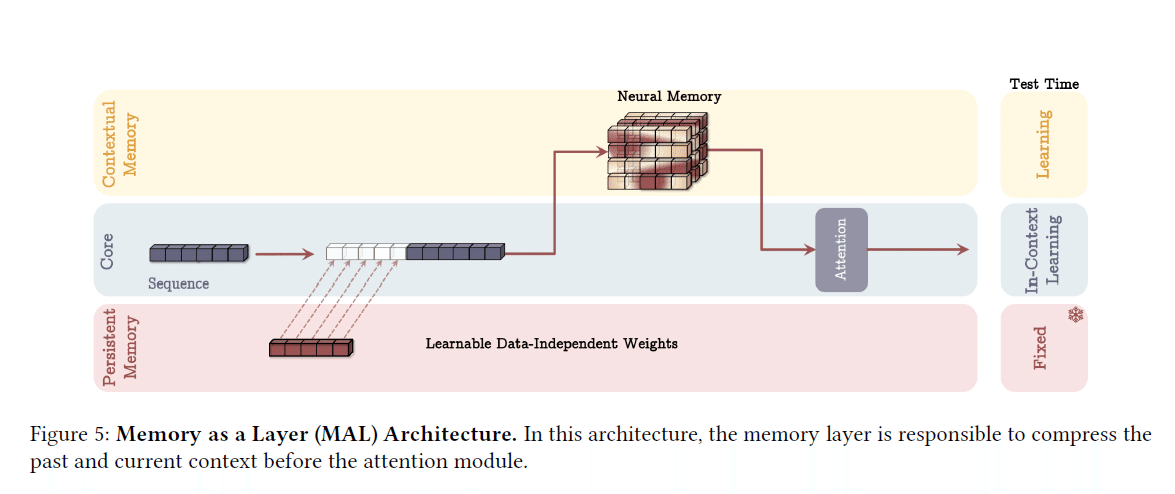
③MAL (Memory as a Layer)アーキテクチャ
ニューラルメモリ自体をニューラルネットワークの1層として組み込む
まずメモリ層で処理し、その出力をSWAなどに投入
MACやMAGに比べると、計算効率面で劣る可能性
4.実験結果
実験結果として、従来モデルと比べて良好な結果が報告されています。詳しくは原論文を参照ください。
Titansは、従来のTransformerや線形リカレントモデル、ハイブリッドモデルとのベンチマークで優れた性能を示した。
NIAHタスク(干し草の山の中の針)において、コンテキスト長を2K, 4K, 8K, 16K…と伸ばしても、Titansは性能低下が比較的少なかった
BABILongベンチマーク、時系列予測・DNAモデリングのベンチマークにおいてもも最先端と競合する性能を達成
ニューラルメモリのMLP層数を増やすほど性能は向上(perplexityが改善)するが、トレーニングスループットは低下する。表現力 vs. 計算効率というトレードオフが存在する。
アブレーションスタディ:ニューラルメモリ内の各要素(非線形性、畳み込み、モメンタム、重み減衰、永続メモリなど)を削除すると、どの場合も性能が下がることから、各コンポーネントが相互に連携して性能を支えていることが確認された。



感想ほか
従来のRAGも用途によっては、まだまだ有効な手法だと思いますが、「モデルが学習済み重みだけでなく、運用中に新たな情報を学習し続け、必要に応じて記憶を更新できる」点で画期的だと思います。人間のように、“驚いた情報”を長期的に保持し、不要になれば忘れる。そんな記憶機能を深層学習モデルに取り込む動きは、今後の大規模言語モデルのさらなる発展にも大きく寄与しそうです。
なお、論文の実装はPyTorchとJAXで用意されており、公開が予定されているとのこと。今後の研究の進展にも注目です。最後までお読みいただきありがとうございました。