
【論文紹介】複数トークン予測によるLLMの精度向上と高速化

Meta社の研究チーム(Fabian Gloeckle, Badr Youbi Idrissi, Baptiste Rozière, David Lopez-Paz, Gabriel Synnaeve)が発表した論文がXで話題になっていたので、ざっと眺めてみました。理解不足も多々あると思いますので、詳細は原文を参照願います。
複数トークン予測モデルの概要
トレーニング:従来のTransformerベースのLLMでは、次の1トークンを予測する単純なタスクで学習が行われますが、今回提案された複数トークン予測アーキテクチャでは、従来のTransformer型の基幹部(共有トランク:Shared transformer trunk)に複数(下図では4つ)の専用出力ヘッドを組み合わせることで、一度に未来の複数トークンを予測するタスクで効率的に学習を行う。

推論:推論時は、次トークン用の出力ヘッド(Head 1)のみを使用するか、オプションとして他のヘッドも活用することで、推論時間を大幅に短縮することが可能。4トークン予測のモデルでは3倍程度、推論速度の向上が確かめられた。
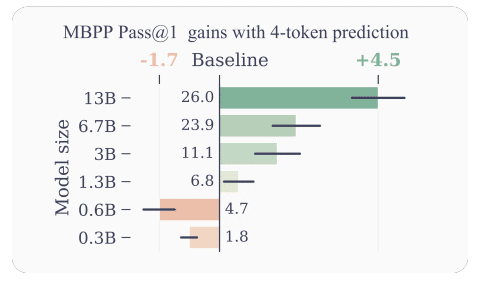
性能向上:複数トークン予測(下図では4トークン予測)を用いた場合、MBPPコードタスクにおいて、モデルサイズが大きくなるにつれて従来の次トークンモデルに比べて正解率が大幅に改善した。
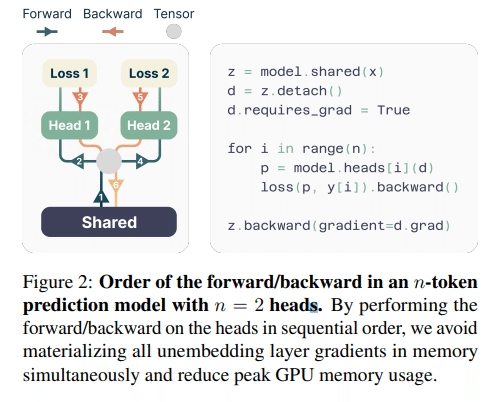
GPUメモリ使用量の効率化
学習時は複数の出力ヘッドを効率的に計算するために、出力ヘッドを順番に計算し、必要ない情報はすぐにメモリから解放することで、GPUメモリ使用量を効率化する工夫が提案された。
この方法を用いることで、通常のTransformerモデルに比べてHeadひとつ分のメモリ増加で学習できそうですし、計算資源やメモリが潤沢にある場合には学習も並列化して時間短縮もできそうです。
感想ほか
論文では以上の内容のほか、様々なタスクやモデルサイズなどの影響が検証されていて、性能向上の効果が顕著なタスク(コード生成、文章要約など)や、性能向上の効果が限定的なケースも報告されていて、おもしろかったです。
Transformerモデルの隠れ表現は、モデルが十分大きい場合は、広範な文脈の情報を捉えることができ、次の1トークンだけでなく、将来の複数のトークンの予測能力があることが確かめられたことで、LLMには、まだまだ大きなブレイクスルーの可能性がありそうです。
言われてしまえば、とても単純な発想にも思えるのですが、すごい発明って、得てしてこんなシンプルな発想なんですよね。とても興味深い内容なので、ぜひ原文もご参照ください。
この記事が気に入ったらサポートをしてみませんか?