
Stable Diffusionモデルを応用した超解像技術 DiffBIRを試す

テキストから画像への生成モデルであるStable Diffusionの事前学習モデルを活用して、劣化画像のブラインド画像復元タスク(超解像タスク)を行うDiffBIRというフレームワークが提案されています。サンプルコートも公開されているので早速試してみました。
DiffBIRはBSR(Blind Image Super-Resolution ブラインド画像復元)、およびBFR(Blind Face Restoration 顔画像の復元)の先行研究と比較して優れた結果を示しているとのこと。

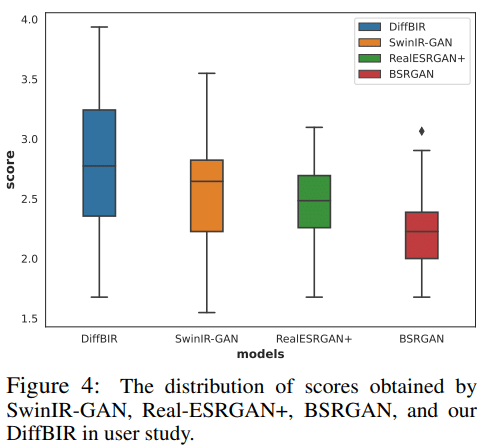

DiffBIRパイプライン概要
DiffBIRフレームワークは、テキストから画像への拡散モデルを事前学習(prし、画像復元タスクに応用しています。具体的には、以下の2段階のパイプラインを用いています。
ステージ1:劣化を取り除くため自己教師付き学習にて事前学習した「Restoration Module(RM)」を用いて、修復された画像 Ireg を得る。
ステージ2: 事前学習された拡散モデル「Stable Diffusion」を活用するLAControlNetを通じて、細かいテクスチャやディテールを復元する。

とにかく試してみます
モデルとともに公開されている、webuiのサンプルコードを試してみます。google colabのノートブックも公開(有料のGPUが必要かも)されていますが、私はローカルPCで実行してみました。
webuiの実行
適宜、お好みの仮想環境上などで実行してください。
$ git clone -b dev https://github.com/camenduru/DiffBIR
$ cd DiffBIR
$ pip install -q einops pytorch_lightning gradio omegaconf xformers==0.0.20 transformers lpips # opencv-python
$ pip install -q git+https://github.com/mlfoundations/open_clip@v2.20.0
$ aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lxq007/DiffBIR/resolve/main/general_full_v1.ckpt -d ./models -o general_full_v1.ckpt
$ aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lxq007/DiffBIR/resolve/main/general_swinir_v1.ckpt -d ./models -o general_swinir_v1.ckpt
$ python gradio_diffbir.py --ckpt ./models/general_full_v1.ckpt --config ./configs/model/cldm.yaml --reload_swinir --swinir_ckpt ./models/general_swinir_v1.ckptブラウザでhttp://localhost:7860/を開く。
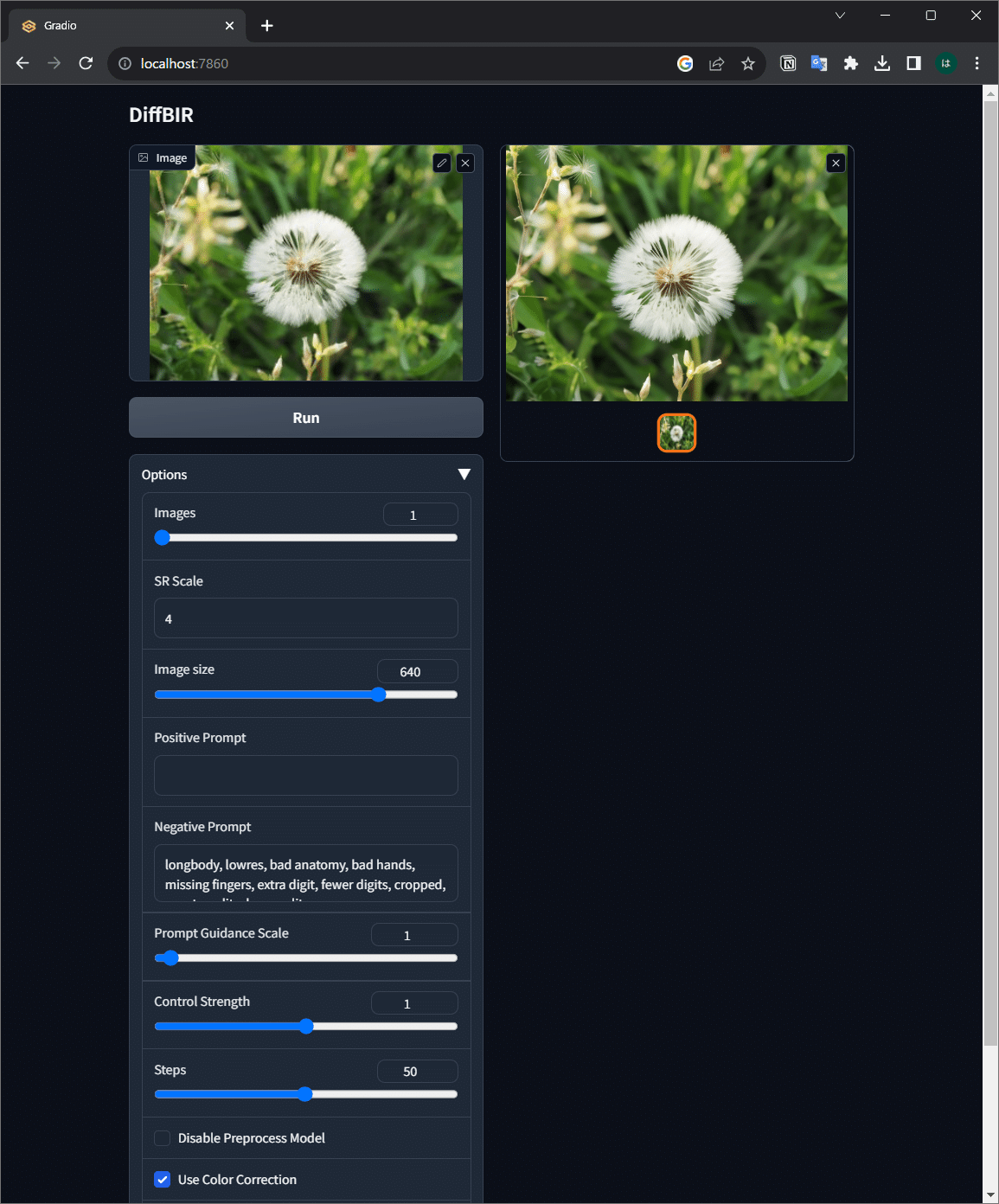
DiffBIR適用例






ギザギザ画像が、かなり自然な画像に変換されている印象です。本来情報がない部分を生成モデルで無理やり復元するため、利用には注意が必要だと思いますが、手軽に利用できるので日常でも活用機会がありそうです。
目的とは違うタスクの事前学習モデルを組み合わせて、高性能なモデルを作るアイデアは色々応用できそうですね。
最後までお読みいただきありがとうございました。
2023/09/13追記: huggingfaceでもgradio demoが公開されました