
LLMを活用したChatBot 開発に関する記録

10Xでコーポレートエンジニアをやっているハリールです。この記事は10X創業6周年のアドベントカレンダーの7日目の記事になります。
昨日は、持ち前のパッションで様々なポジティブ旋風を巻き起こしている BizDev doshoさんによる 「Amazonより安くて早い!?ネットスーパーの賢い使い方!!」でした、消費者としての無意識な行動心理などが言語化・散りばめられています、まだ読まれていない方はぜひ!
はじめに
この記事は、LLMを活用し独自ナレッジベースに基づいた回答が可能なチャットボットの開発に関して、現時点に至るまでの道のりをまとめたものです。
現在進行形で日々進化し続けるLLMに対する取り組みの一つの記録として、TIPSや落とし穴などを交えることでいつか誰かの役に立つことを祈りながら書いています。
背景
10Xでは様々な場面でドキュメントを書き残すことが文化として深く根付いています。
その一方で蓄積された情報量の多さから、目的の情報にたどり着きにくくなっている側面・課題もありました。
そんな中、社員の困りごとに対して少ない認知負荷で目的の情報を提示するための解決策としてLLMの圧倒的な進歩はまさに福音であり、LLMがまるで魔法のようにこれらの課題を解決できる、従業員体験を10xできるものだと、この当時は思っていました。
検討段階
Open AIからgpt-3.5-turboが従来よりも大幅に低いコストで利用できると発表された当時、私が所属しているチームでは、LLMを活用して社内の問い合わせ対応などは効率化していこうという方向性は合意できていました。
ただしHowの部分、つまりその仕組みを内製するのか、それとも既成のサービスを利用するのかは明確には決まっていませんでした。
また、社内で利用しているSlackやAtlassianなどの各サービスが Slack for GPTやAtlassian Intelligenceといった機能を次々と発表していく中で、
「このスピード感ならそう遠くないうちに各サービスでLLMが標準機能として提供されるだろうし、今リソースをかけて内製したとしても長期的に利用はしないだろう。であれば内製はせず、リソースは他に回したほうがよさそう。」
という判断をしました。
とはいえLLM活用という方向性は変えず、海外製でナレッジベース検索ができそうなサービスをしばらく調査つつ、各サービスベンダーの出方を待つことにしました。
方針転換
いくつかデモやトライアルをしつつもなかなか決め手にかける中、他社では内製ですでに構築しているという話を見聞きするようになりました。
「内製しないという判断で本当によかったのか?」という焦燥感が蓄積される日々の中、ついにその焦りが閾値を超え、方針転換を行うことになりました。
試行錯誤1. LLM ChatBot on Zapier
まず最初に試したのは、Zapierを活用しノーコードでOpenAIとインテグレーションするパターンです。

ZapierにはChatGPTのActionがすでに用意されています。
OpenAI API経由のため送信データはトレーニングに使われることもなく安心して利用できます。
また、パラメタもいくつか指定ができ、Memory Keyを指定することで文脈を記憶して会話することができます。

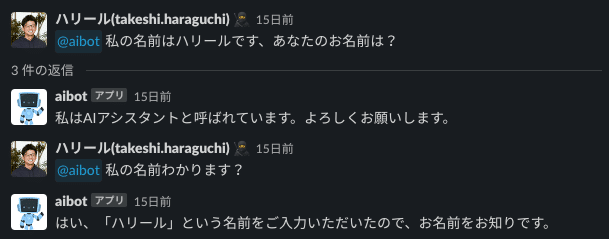
ノーコードらしくとても簡単にGPTとつながるChatBotが実現できますが、レスポンスの遅さに課題があります。
以下は日中時間帯にバラバラに約20回ほど呼び出した際の処理時間をまとめたものです。
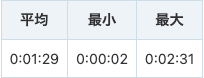
ばらつきが多いですが、最速2〜3秒のレスポンスは英語で話しかけた場合で、日本語での質問に対しては平均1分半〜2分ほどの待ち時間が発生していました(体感はもっと長く感じていました)。
UXを損なわないように、処理中である一時メッセージを投稿するなど入れてみましたが、パラメタ指定に限界があり、これ以上のチューニングは難しいと判断しました。
試行錯誤2. LLM ChatBot with Azure OpenAI on Zapier
続いて試したのは、ChatGPTのActionをAzureOpenAIを呼び出す処理に切り替えるパターンです。

4のCustom Request in Webhooks by Zapier では Azure OpenAI APIを呼び出しています。
APIに指定するパラメタは自由に設定ができるため、より細かいチューニングも可能となります。AzureOpenAIに切り替えてのレスポンスの計測結果は以下です。

現在まだクローズドβということもありますが、非常に安定しており実運用でも十分に使えそうです。
ChatGPTを少ない工数でかつ安全に社内で使ってもらいたいという場合、このパターンは十分にFitしそうです。
試行錯誤3. LLM ChatBot with Azure OpenAI on Slack Platform
先程までのChatBotはOpenAIをラップして呼び出しているだけであり、当初の目的である"独自ナレッジベースによる回答"を実現するには至っていません。
独自ナレッジベースによる回答には、Embeddingsを利用する想定ですが、そのためにはプログラムを動かす環境が必要になってきます。
Embeddingsについてまだまだ勉強中ですが以下を参照ください。
Embeddingsを利用する場合、3rdPartyのライブラリ(LangChainなど)含めて、Pythonでの利用を想定されているケースが多い印象ですが、JavaScriptでも一部機能制限はあるものの提供・サポートされています。
理想はPythonでしたが、JavaScriptの実行環境であればすぐに試せることから、まずはSlack Platformで試すことにしました。
先程のZapierの流れをSlack Plafrormに移植し、同じ体験が提供できる状態としました。
なお、Azure OpenAI APIを呼び出すためには、manifest.ts のoutogoingDomainsに以下のように追加する必要があります。
※ INSTANCE_NAMEはAzure OpenAI Studioで確認できます。
export default Manifest({
・・・省略・・・,
outgoingDomains: ["[INSTANCE_NAME].openai.azure.com"],
・・・省略・・・
});試行錯誤3-1. ベクトルDBの準備
ナレッジが豊富にあり無料で試せるということもあり、ベクトルDBにはPineconeを利用しました。
サンプルとして簡単なQ&AデータをNotionに用意したら、それをExportしてPineconeにInsertしておきます。
試行錯誤3-2. PineconeClientによるベクトルDB検索
まずはローカル環境でベクトルDBへの検索をPineconeClientを使って試してみます。
import { PineconeClient } from "npm:@pinecone-database/pinecone";
const request = new Request("https://api.openai.com/v1/embeddings", {
method: "POST",
body: JSON.stringify({
input: "経費精算の方法は?",
model: "text-embedding-ada-002"
}),
headers: {
"content-type": "application/json",
"Authorization": "Bearer [OpenAI API Token]",
},
});
const response = await fetch(request);
const json = await response.json();
const pinecone = new PineconeClient();
await pinecone.init({
environment: "[Pinecone Environment]",
apiKey: "[Pinecone API Key]",
});
const index = pinecone.Index("[index名]");
const queryRequest = {
vector: json.data[0].embedding,
topK: 1,
includeValues: true,
includeMetadata: true
};
const queryResponse = await index.query({ queryRequest });
console.log(queryResponse);上記呼び出しによってscoreやmetadataを取得できます。これらを独自に制御することもできなくはないですが、より効率的に扱うためにLangChainを試してみます。
試行錯誤3-3. LangChainによる検索
LangChainはLLM関連の各種サービスに対する処理をラップして制御してくれるライブラリです。
LangChainを使って先程の処理を書き換えて試してみます。
import { PineconeClient } from "npm:@pinecone-database/pinecone";
import { VectorDBQAChain } from "npm:langchain/chains";
import { OpenAIEmbeddings } from "npm:langchain/embeddings/openai";
import { OpenAI } from "npm:langchain/llms/openai";
import { PineconeStore } from "npm:langchain/vectorstores/pinecone";
const client = new PineconeClient();
await client.init({
apiKey: "[Pinecone API Key]",
environment: "[Pinecone Environment]",
});
const pineconeIndex = client.Index("[index名]");
const vectorStore = await PineconeStore.fromExistingIndex(
new OpenAIEmbeddings(),
{ pineconeIndex }
);
const model = new OpenAI();
const chain = VectorDBQAChain.fromLLM(model, vectorStore, {
k: 1,
returnSourceDocuments: true,
});
const response = await chain.call({ query: "経費精算の方法は?" });
console.log(response);queryには予めPineconeに投入している質問を入れているため、以下のような意図したレスポンスが返ってきました。
{
text: " 以下から申請をお願いします。[申請URL]",
sourceDocuments: [
省略
]
}これで荒くはあるものの、当初の目的である独自ナレッジに基づいた回答が可能な状態が検証できたので、これらの処理を Slack Platformアプリに組み込んでいきます。
なお、Slack Platformで呼び出す場合、manifest.tsには呼び出し先をすべて追加しておく必要があります。以下のようにPineconeのドメインも追記しておきます。
outgoingDomains: [
"api.openai.com",
"[INSTANCE_NAME].openai.azure.com",
"controller.[ENVIRONMENT].pinecone.io",
]試行錯誤3-4. 立ちはだかる壁
結論としては、現時点で上記の処理をSlack Platformで動作させるには至っていません。
ローカル環境では正常に動作した上記処理をSlack Platformに移植して実行すると
Uncaught PineconeError: PineconeClient: Error calling query: PineconeError: PineconeClient: Error calling queryRaw: FetchError: The request failed and the interceptors did not return an alternative response
といったエラーメッセージが表示されます。
調査が難航する中、別の方式を試すことにしました。
試行錯誤4. LLM ChatBot with Azure OpenAI boosted by Bolt for Python
切り分けの意味でも、ここで一旦Slack Platform以外を試してみることにしました。
Slack Platform以外を選択できる時点でJavaScriptの制約はなくなることから、Bolt for Pythonを使って構築します。
以下のチュートリアル通りに進めれば簡単にひな形ができます。
実際に組み込んだコードが以下です。
pinecone.init(
apiKey: "[Pinecone API Key]",
environment: "[Pinecone Environment]",
)
index_name = "[index名]"
embeddings = OpenAIEmbeddings()
docsearch = Pinecone.from_existing_index(index_name, OpenAIEmbeddings())
llm = OpenAI(temperature=0)
qa = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=docsearch.as_retriever())
result = qa.run("[ユーザーから受けた質問]")
say(result)これでようやく 独自ナレッジに基づいた回答が可能なチャットボットの原型ができあがりました。
まとめ
プラットフォームについて紆余曲折ありましたが、なんとか一通りの技術的な検証ができました。ただこれでようやくスタート地点に立てただけなんですよね。
日々環境が変化していくなかで、必要となる情報を常に高い鮮度で継続的にナレッジベースに取り込んでいく方法の確立や、それらを高い精度でユーザーに返すためのチューニングなど、まだまだ学ぶべきこと・やるべきことは山積しています。
なお、当初内製しない方針を途中で変更したことについては結果的によかったと考えています。
ほとんど聞いたこともない用語で溢れていたLLM関連の技術スタックについて、度々発生するトラブルシューティングの過程からも、その仕組みを多少なりとも理解できましたし、何よりも今現在の技術の渦は間違いなくLLMがその中心にあり、様々なサービスがそこから産み出されています。
その目まぐるしい変化をある意味楽しみながらも、自分たちの組織・事業の成長に少しでも貢献できるよう、そして最高の従業員体験が実現できるように、これからも精進していきたいと思います。
そんな10Xでは絶賛メンバーを募集しています!ご興味をお持ちの方はぜひ採用ページをご覧ください!
明日はBizDev nyubaさんが記事を公開する予定なので、お楽しみに!