オンデバイス GenAI

OpenAI 12Days期間中に、Gemini 2.0 Flashが登場
思考モデルが導入された
画像生成、音声生成機能が追加された
from google import genai
client = genai.Client(api_key='GEMINI_API_KEY', http_options={'api_version':'v1alpha'})
// 思考モデルは標準モデルよりも応答に時間がかかるため、モデルの思考をストリーミングする(generate_content_stream)
for chunk in client.models.generate_content_stream(
model='gemini-2.0-flash-thinking-exp', contents='What is your name?'
):
for part in chunk.candidates[0].content.parts:
// part.thoughtフィールドがTrueに設定されているかどうかを確認することで、パートが思考かどうかをプログラマティックに確認できる
if part.thought == True:
print(f"Model Thought Chunk:\n{part.text}\n")
else:
print(f"\nModel Response:\n{part.text}\n")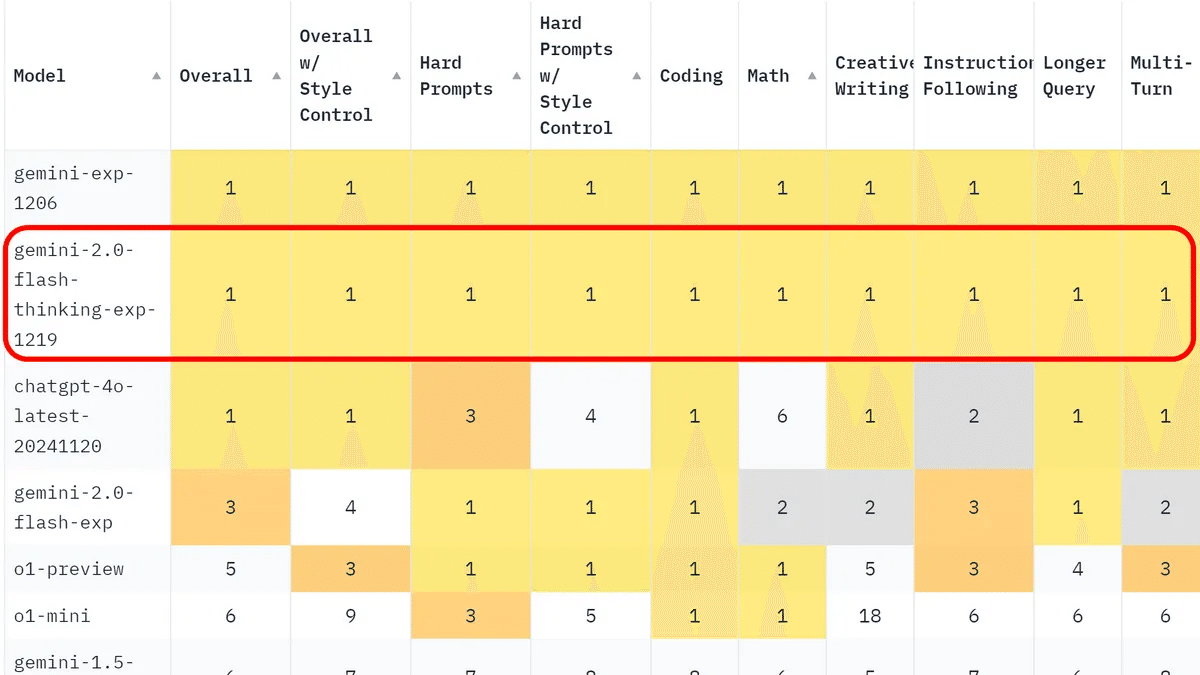
性能的に強い
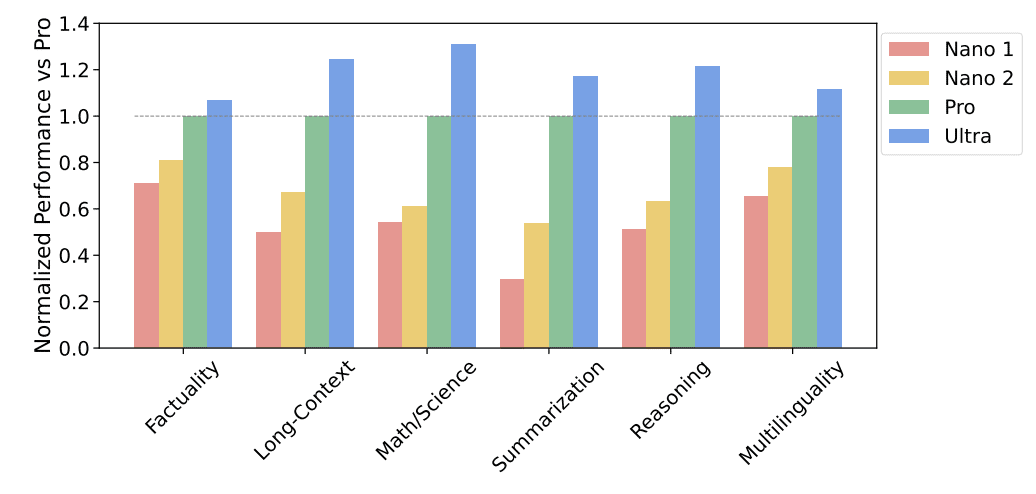
Gemini Nano 2も発表された
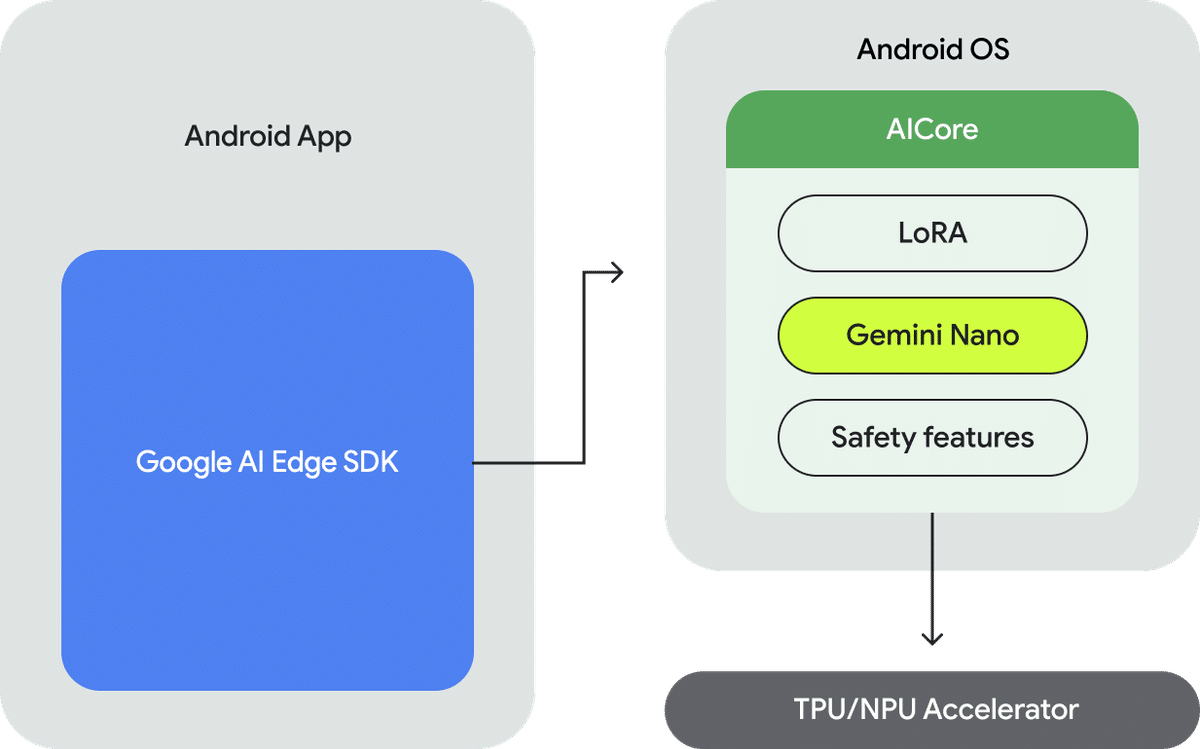
オンデバイスGenAIのメリット
ローカル処理
オフラインでも利用可能
レイテンシーなし
サーバーコストなし
使用例
// build.gradleにライブラリを追加
implementation ("com.google.ai.edge.aicore:aicore:x.x.x")
// Configを設定
val generationConfig = generationConfig {
context = ApplicationProvider.getApplicationContext()
workerExecutor = workerExecutor
callbackExecutor = callbackExecutor
temperature = 0.2f // 生成するテキストのランダム性を制御
topk = 16 // 生成に使用するトップランキングトークンを制御
candidateCount = 1 // ユニークレスポンス数
maxOutputTokens = 256 // レスポンスの長さ
}
// downloadCallbackを定義
val downloadCallback = object : DownloadCallback {
override fun onDownloadDidNotStart(e: GenerativeAlException) {
// Log download start failure
}
override fun onDownloadPending() {
// Log download pending
}
override fun onDownloadStarted(totalBytesToDownload: Long) {
// Log download started
}
override fun onDownloadFailed failureStatus: String, e: GenerativeAlException) t
// Log download failed
}
override fun onDownloadProgress(totalBytesDownloaded: Long) {
// Log download progress
}
override fun onDownloadCompleted() {
// Download completed, start your first query
}
}
// モデル設定
val model = GenerativeModel(
generationConfig = generationConfig,
downloadConfig = DownloadConfig(downloadCallback) // オプショナル
)
// モデルを使用
val response = generativeModel generateContent (
content {
text("I want you to act as an English proofreader. I
will provide you texts and I would like you to review them for any spelling, grammar, or punctuation errors.")
text("Once you have finished reviewing the text, provide me with any necessary
corrections or suggestions for improving the text:")
text("These are not the droids you are looking for.")
})
print (response. text)
}// プロンプトに詳細な要求を記述する
Prompt:
Predict up to 5 emojis as a response to a text chat message. The output should only include emojis.
Woo! Launch time!
Output from Gemini nano:
🚀🚀🚀🚀🚀デバイスでのモデルチューニングも可能になりました
モデルはLiteRTを使用
2024/09/24から、GoogleがTensorFlow Lite(TFLite)をLiteRTに改名した
PyTorch・JAX・Kerasモデル → LiteRT(.tfliteに変換) → 手元のiOS・Android・Linux端末などで利用できるモデル
例:YOLO11n
YOLOは有名な物体検出モデル
インスタンスセグメンテーションや姿勢推定など複数のタスクに対応している
v10からリアルタイムの物体検出に新しいアプローチを導入し、v9以前のバージョンで見られた後処理とモデルアーキテクチャの両方の欠陥に対処している
11からバージョンのvがなくなった(YOLOv10 → YOLO11)
精度:11 ≈ v10 ≈ v9
速度:11 ≈ v10 > v9
リポジトリ:LiteRT
オンデバイスチューニングはMediapipeを使用
クロスプラットフォームのモデルトレーニングソリューション
MediaPipe Tasks:ソリューションをデプロイするためのクロス プラットフォームの API とライブラリ
MediaPipe Model:各ソリューションで使用できる、事前トレーニング済みですぐに使用できるモデル
これらのツールを使用すると、ソリューションをカスタマイズして評価できます。MediaPipe Model Maker:独自のデータを使用して、ソリューションのモデルをカスタマイズできるツール
MediaPipe Studio: ブラウザでソリューションの可視化、評価、ベンチマークを行うツール
お試し:MediaPipe Studio
リポジトリ:MediaPipe Tasks
事前トレーニング例(LiteRT)
オンデバイストレーニング例(MediaPipe Tasks)
// build.gradleにライブラリを追加
implementation ("com.google.mediapipe:tasks-genai:x.x.x")
// Configを設定
val options = LlmInference.LlmInferenceOptions.builder()
.setTopK(5) // 生成に使用するトップランキングトークンを制御
.setTemperature (0.9f) // 生成するテキストのランダム性を制御
.setMaxTokens (1028) // レスポンスの長さ
.setModelPath(MODEL_PATH) // デバイスでのモデルパス
.setLoraPath(LORA_PATH). // デバイスでのLORAパス
.setResultListener { partialResult, done ->
_partialResults.tryEmit(partialResult to done)
}
.build()
llmInference = LimInference.createFromOptions(context, options)
// モデルを使用
val prompt = "仮内容"
llmInference.generateResponse(prompt)参考リポジトリ