
o1に大きな変動:GPT4o vs o1 一問一答比較レポート 2025-01-28

記事概要
本記事では、GPT4o と o1 の回答を同じ質問で繰り返し取得し、日々の変動とモデル間の相関を分析します。
バージョンアップや一時的な性能変動が、既存の挙動とどう違うのかを数値的に把握
長期的なデータで負の相関が続いていた指標が正に転じる等、大きな変化があった場合にモデル更新の影響を推測
モデル毎の回答文字数や使用単語の傾向差が出た際、どの程度重大な変動かを可視化
これにより、**「4oの回答だけ減少しているのは一時的な負荷なのか」**等の疑問にもアプローチし、AIのアップデート状況や安定性をより深く検証していきます。
GPT4o、GPTo1単独での評価をおこなうマガジン
GPT4oの日次評価マガジン
GPTo1の日次評価マガジン
検証方法
GPT4oとo1に対し同一プロンプト質問に対する回答を再生成を繰り返し、回答内容の変動を調査。
プロンプト:「ウマ娘プリティーダービー」のゴールドシップのキャラクターロール
質問:ウマ娘プリティーダービーからプリティー抜いたらどんなアニメになるか、一回の応答で可能な限り文字数を使って詳しく教えてくれ。
統計値の見方
相関係数 (r)
両モデル(o1 と GPT4o)の値の動きが、どれくらい同じ方向に変動しているかを示します。
範囲: r は -1 ~ 1 の値を取り、
1 に近い: ほぼ同じタイミング・方向で数値が上下する
0 に近い: 両モデルの変動に関連がほとんどない
-1 に近い: 片方が上がると、もう片方が下がるように変動
区分例:
|r| > 0.7: 強い相関(非常に似通った動き)
0.4 < |r| < 0.7: 中程度の相関
0.2 < |r| < 0.4: 弱い相関
|r| < 0.2: ほとんど相関なし(独立した動き)
回帰からの逸脱(%)
o1 の値から回帰分析(※1)によって予測される GPT4o の値と、実際の GPT4o の値がどれくらい離れているかを %(パーセント) で示します。
正の値: 実測値が予測より高い
負の値: 実測値が予測より低い
変動範囲:
±10%以内: 通常の誤差範囲
±10~30%: 注目すべき逸脱(なにか変化の兆しがある可能性)
±30%以上: 顕著な逸脱(モデルが大きく変化している可能性が高い)
※1: 回帰分析
ここでは、o1 の日次平均値から GPT4o の日次平均値を予測するための 回帰直線 を求め、それと最新データのズレを確認しています。モデル同士の連動が強いほど、回帰からの逸脱は小さくなる傾向があります。
基本情報
o1データ数: 420
GPT4oデータ数: 6719
共通の日付数: 26
相関分析結果
※各メトリクスの解釈について:
「全期間の相関」は両モデルの値の変動の類似性を示します(正の値:同じように変動、負の値:逆方向に変動)
「予測からの逸脱」は、o1の値から予測されるGPT4oの値と実際の値の差を示します
逸脱が大きくても、絶対値が極めて小さい場合(使用頻度が0に近い場合など)は、その変動の重要性は低くなります
文字数


全期間の相関: r = 0.050
今日の値: o1=1912.57, GPT4o=1451.00
o1の値からの予測値: 1327.87
予測値との差: +9.3%
今日の文字数は予測値を上回っています(+9.3%)。通常の変動範囲とみられます。
※文字数は回答の量的な充実度を示す基本的な指標です
TTR(語彙の豊富さ)
この項目の計算の妥当性がまだ検証中なので参考程度に、表現を繰り返すと値が低くなる。


全期間の相関: r = -0.201
今日の値: o1=0.38, GPT4o=0.41
o1の値からの予測値: 0.42
予測値との差: -1.8%
今日のTTR(語彙の豊富さ)は予測値を下回っています(-1.8%)。通常の変動範囲とみられます。
※TTRの値域は0-1で、1に近いほど多様な語彙を使用していることを示します
命令違反
プロンプトでは箇条書きの使用を禁止している。
:や-などの記号が使用される場合、命令に反し箇条書きを使用しているため、この記号の使用頻度を元に命令への従順度を評価している。


全期間の相関: r = 0.152
今日の値: o1=0.0003, GPT4o=0.0057
o1の値からの予測値: 0.0146
予測値との差: -60.9%
今日の命令違反の使用率は予測値を下回っています(-60.9%)。顕著な逸脱とみられます。
※使用率が0.01未満の場合、実質的に命令違反はないと解釈できます
予想推測
回答で「かも」「だろう」「はず」など予想や推測を示すワードがどの程度使われるかの割合。
プロンプト優先か、学習データにもとづくもっともらしさ優先のどちらであるかという体感をある程度評価、可視化できていた(過去形)。
GPTは第三者、客観的、現実的な回答を出力するような傾向がある期間の回答では「アニメはこうなるだろう」という予想、推測を示す傾向があった(過去形)。
予想推測ではGPTが「プロンプトにもとづいて思考し回答する」するのではなく、「学習データに含まれるもっともらしい回答例のつぎはぎを出力する」傾向にあったと評価している。
ただし昨今のGPT4oは「与えられたプロンプトのロジックに従った思考に基づく予想」をするケースが見られる。


一方でGPTが主体的にアイディアを生成する振る舞いを示す場合、予想推測ワードの使用頻度は低くなる。
全期間の相関: r = -0.297
今日の値: o1=0.0066, GPT4o=0.0028
o1の値からの予測値: 0.0024
予測値との差: +17.5%
今日の予想推測の使用率は予測値を上回っています(+17.5%)。注目すべき逸脱とみられます。
※使用率が0.01未満の場合、予想推測表現はほぼ使用されていないと解釈できます
プロンプトの影響力:言動や行動の具体例からの引用頻度
プロンプトに含まれるゴールドシップのセリフ例、行動例の引用率。
具体例から応用、連想したワードを使用するケースがあり、プロンプトからの引用が多ければプロンプトに従順とは一概に言えない。
ただし参考材料になる項目ではあり、例えば引用も少なく、プロンプトから連想されうるワードが見受けられない場合、GPTはプロンプトを軽視している可能性がある。
また引用を繰り返し、回答でのアニメの説明力が低下するケースや、強引にセリフ例を盛り込む事で前後の文と繋がらず意味不明な回答を出力するケースがある。


全期間の相関: r = 0.188
今日の値: o1=0.0072, GPT4o=0.0014
o1の値からの予測値: 0.0015
予測値との差: -5.9%
今日の行動言動具体例の使用率は予測値を下回っています(-5.9%)。通常の変動範囲とみられます。
※使用率が0.01未満の場合、プロンプトからの直接的な引用はほとんどないと解釈できます
学習データの応用頻度:GPTの振る舞い(ウマ娘固有名詞分析)
ゴルシプロンプトにはウマ娘プリティーダービーの他キャラを含んでいない。
ウマ娘キャラクターが登場した場合、GPTのウマ娘に関する学習データが回答に反映したと解釈できる。
この頻度が高ければGPTは積極的に学習データを使用し、逆に低下してる場合は学習データの使用に消極的と解釈しうる。
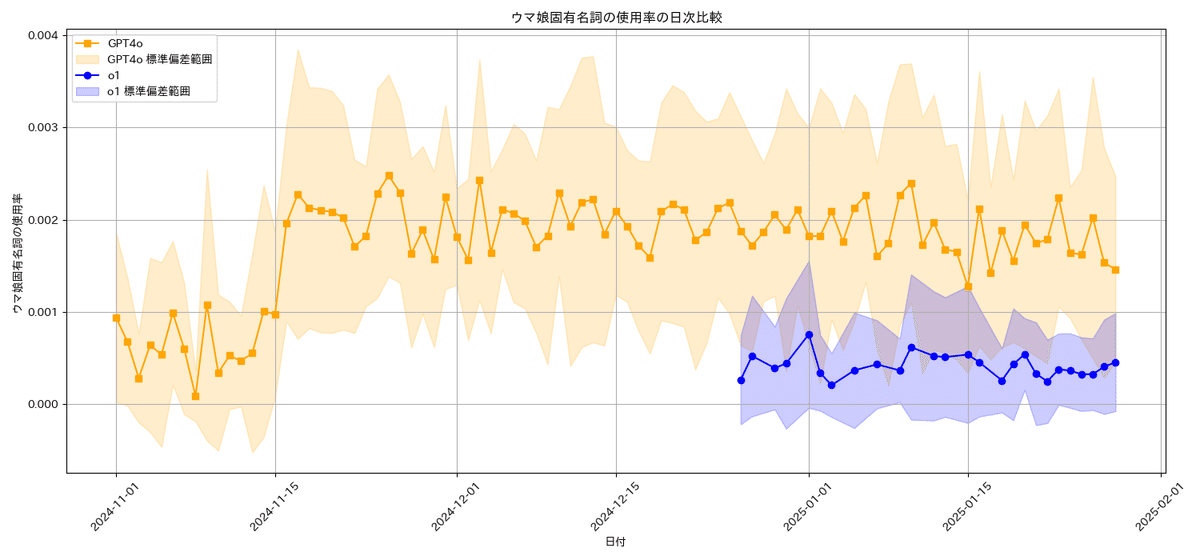

全期間の相関: r = -0.069
今日の値: o1=0.0005, GPT4o=0.0015
o1の値からの予測値: 0.0019
予測値との差: -21.6%
今日のウマ娘固有名詞の使用率は予測値を下回っています(-21.6%)。注目すべき逸脱とみられます。
※使用率が0.01未満の場合、プロンプト外のキャラクターへの言及はほとんどないと解釈できます
単純比較による分析結果まとめ
【文字数】GPT4oは予測値(1327.8720)を小さな上回っています(差異:9.3%)。相関は「ほとんど相関なし」(r=0.050)でした。
【句読点数】GPT4oは予測値(54.8567)を小さな上回っています(差異:9.5%)。相関は「ほとんど相関なし」(r=-0.061)でした。
【単語数】GPT4oは予測値(736.9346)を中程度の上回っています(差異:10.4%)。相関は「ほとんど相関なし」(r=0.010)でした。
【語彙の豊富さ(TTR)】GPT4oは予測値(0.4218)を小さな下回っています(差異:1.8%)。相関は「弱い相関」(r=-0.201)でした。
【予想推測の使用率】GPT4oは予測値(0.0024)を中程度の上回っています(差異:17.5%)。相関は「弱い相関」(r=-0.297)でした。
【行動言動具体例の使用率】GPT4oは予測値(0.0015)を小さな下回っています(差異:5.9%)。相関は「ほとんど相関なし」(r=0.188)でした。
【ウマ娘固有名詞の使用率】GPT4oは予測値(0.0019)を大きな下回っています(差異:21.6%)。相関は「ほとんど相関なし」(r=-0.069)でした。
【命令違反記号の使用率】GPT4oは予測値(0.0146)を顕著な下回っています(差異:60.9%)。相関は「ほとんど相関なし」(r=0.152)でした。
【命令違反記号_除外アスタリスクの使用率】GPT4oは予測値(0.0100)を顕著な下回っています(差異:63.9%)。相関は「ほとんど相関なし」(r=0.101)でした。
トレンド分析
※以下の数値は、o1との関係から予測されるGPT4oの値と実際の値の差を示しています
※差分が大きくても、使用率が0.01未満の場合は、その変動の重要性は低く解釈されます
※マイナス値は予測より低い、プラス値は予測より高いことを示します
命令違反記号_除外アスタリスクの使用率: 予測値(0.01)に対して 63.9%の下振れ(実測:0.00)
命令違反記号の使用率: 予測値(0.01)に対して 60.9%の下振れ(実測:0.01)
ウマ娘固有名詞の使用率: 予測値(0.00)に対して 21.6%の下振れ(実測:0.00)
予想推測の使用率: 予測値(0.00)に対して 17.5%の上振れ(実測:0.00)
単語数: 予測値(736.93)に対して 10.4%の上振れ(実測:813.86)
グラフ
※各メトリクスの時系列比較グラフと相関分析グラフは/graphsディレクトリに保存されています。