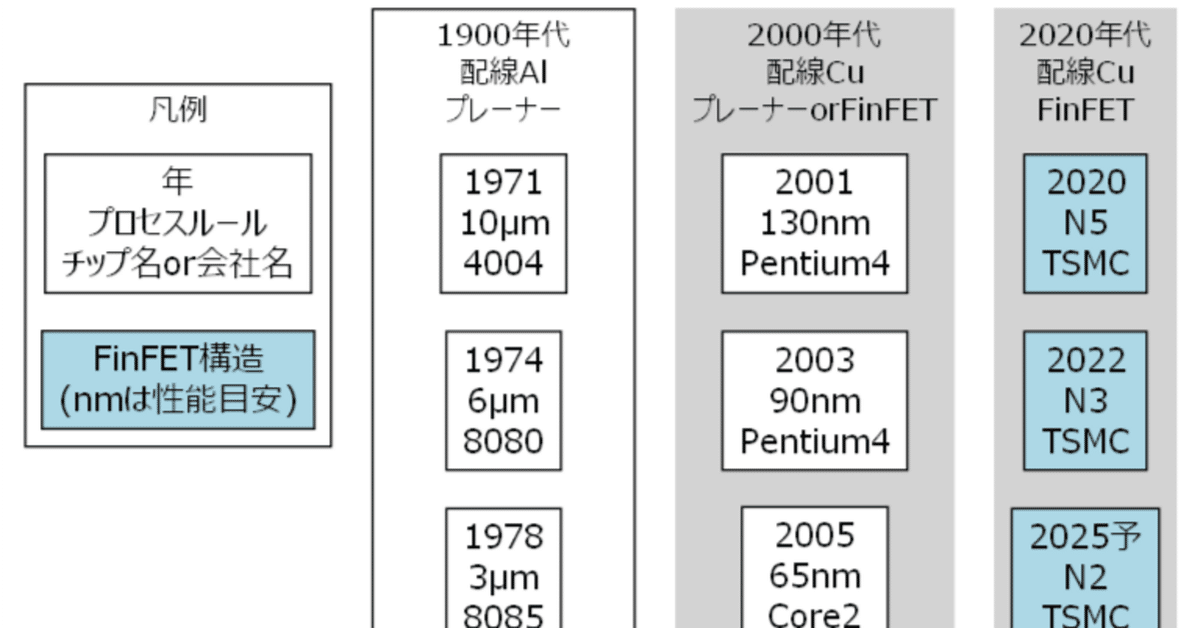
半導体のプロセスノードとかを簡単にまとめてみました(本当に簡単です・・・)

10年前に組み立てた自作PCがwindows11に非対応(CPUがSkyLake)なので、久しぶりにCPUの情報を調べてみたところ、かなりプロセスルールの状況が変わっていました(まあ、当たり前です。10年ひと昔ですから)
さらに、最近の半導体株ブームもあって、株投資の観点からも、半導体のプロセスルールを簡単にまとめてみようと思いました。(自分で図にしておくと、後で思い出しやすいので)
あと、どうも後工程のメーカの重要度も上がっているみたいです。
昔はチップの性能向上が主で、チップモジュールは従のイメージでしたが、今はチップモジュールでもチップレット(MCM:マルチチップモジュール)技術が重要の様です。そのあたりも、調べてみました。
半導体プロセスルールの変遷
色々なwebサイトを参考にしました。代表的なwebサイトを下記に上げます。
簡単な図です。
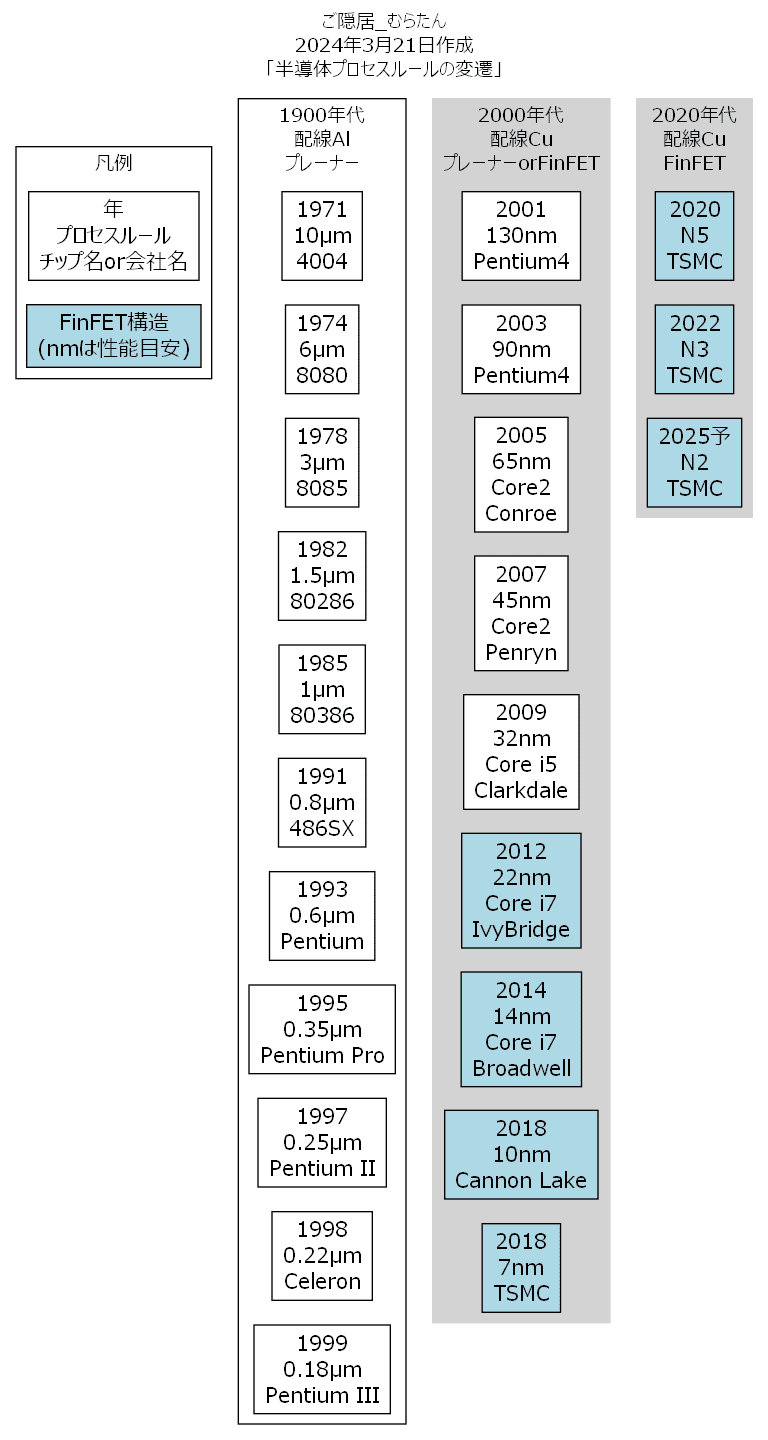
1970年~1990年代 Intelの全盛期
1970年から1990年はIntel全盛期です。ほぼ最先端のプロセスルールはIntelが開発して、それを他社が追随していたと記憶しています。
今から考えると、牧歌的にも感じる時代です。なにしろ、初期のころの配線はμm単位なので目視でも識別できるほどの配線幅でした。
ちなみにこの頃は平面的なプレーナー構造の半導体なので、配線幅が狭くなるほど、「速く」「安く」「省電力」になると言う夢のような時代でした。俗にいう「ムーアの法則」というやつです。
その代わり、「今日買ったPCが明日には陳腐化する」と言うエンドユーザーには辛い時代でもありました。それでも、性能がどんどん良くなっていくのは、とても楽しかったですし、夢がありました。
2000年~2010年代 プロセスの大きな変化
2000年代は二つの大きなプロセス変化がありました。
「Cu配線」と「FinFET」です。
個人的に驚いたのは、配線にCuを使ったことです。それまでの常識では、SiにCuが拡散しやすいので、半導体にCuを使うことは忌み嫌われていました。
ところが、それまで配線に使用されていたAlは「エレクトロマイグレーションで断線が起きる」と「導電性がCuより低い」という2つの欠点から、配線幅を狭くできない限界に達しました。
そのため、半導体配線にCuが使用されるようになりました。
私、半導体以外の分野の電気メッキ技術者だったので、これには心底びっくりしました。「CuをSi半導体に使うだと?拡散しないのか?」「電気メッキでCuを埋め込むだと?Cuイオンは大丈夫か?」「高真空では無い、湿式環境(普通のメッキ液は結構汚いです・・・)で半導体作れるの?」「後の研磨は大丈夫なの?」と課題ばかりが思い浮かびました。
しかし、「必要は発明の母」と言うように、課題はすぐに解決されて2000年代にはCu配線が当たり前になりました。
たとえば、Cuが拡散しないようにバリア層を設けて使用しました。あらかじめ作っておいた溝にCuを電気メッキ等で埋め込む「ダマシン技術」が主流になりました。研磨は化学研磨と機械研磨を併用するCMP(Chemical Mechanical Polishing)が使われました。
もう一つのプロセス変化は、プレーナー(平面構造)からFinFET(フィン構造)に変化したことです。
これは、プロセスルールの寸法を見ればわかります。Cu原子の格子間距離は0.36nmですので、10nm幅だと27個前後の原子しかありません。この幅に前述のバリア層まで作らなければいけないので、数原子レベルの制御が必要になります。それでも、プレーナーのままでは原子数が足りなくなって、原理的に無理です。これが「ムーアの法則の終焉」と言われるものです。
ところが、ここでも「必要は発明の母」が現れました。このタイプの半導体は、ゲートに電位を掛けて制御します。プレーナーでは1面しか電極がありませんが、これをフィン構造にすれば3面に電極を作ることができ、より効率的に電位をかけることができます。さらに、面積当たりのトランジスタ数も増やすことができます。
これがFinFETと呼ばれるタイプになります。
この辺りから、プロセスルールの「〇〇nm」は実態と乖離してきました。7nmのプロセスルールでも配線幅が7nmの部分は無かったと思います。
なので、「プレーナーで換算すると〇〇nmに相当するので、〇〇nmと呼びますよー」と言う意味合いになっています。
2020年代 TSMC主流
2000年代はIntelが最新プロセスを開発していました。ところが、前述のような新たな技術を継続的に投入する必要があり、1900年代のようには簡単に開発できなくなりました。記憶ではIntelはFinFETを安定して作るのに苦労したと思います(私は14nmのCPUが出るまで結構待ったので・・・)。
さらに、配線幅が狭くなると露光用の紫外線波長を短くする必要が出てきました。今だとEUV(Extreme ultraviolet lithography)の13.5nmの波長が使われています。
EUVはほぼ、オランダのASMLが1社独占だったと思います。残念ながらNIKONやCanonは開発できませんでした。(その前世代のArF露光は強かったのに残念です・・・。でも、開発費が高すぎて日本の会社では無理だよなー)
この辺り半導体の最新プロセスを安定して作れるのは、TSMCが断トツだと思います。あとは、SamsungとIntelあたりです。
米国がIntelに補助金を出そうとしているのは、この辺りの開発費を国が補助する意味合いが強いと思います。
2020年代になると、プロセスルールを「〇〇nm」と表記するのはさすがにまずいと思ったのか、最近は「N5」とか「N3」と表記しています。さらにはオングストロームでAを使うようです。
チップレット・マルチチップモジュール
チップが高すぎる!
半導体は、プロセスが複雑化したため、昔のように「速く」「安く」「省電力」にはならなくなりました。特に「安く」は無理です。
さらに、今話題のGPUとかは回路を沢山詰め込む必要があるので、チップ面積が大きくなりがちです。これが、直接コストに効いてしまいます。
なので、GPUは値段が馬鹿みたいに高いです。さらにAI用のGPUだと、回路数が命なので、素人には手が出ない値段になっています。(まあ、素人はそんなGPUは不要ですが)
面積が小さいほうが歩留まりが良いです
半導体は小さなゴミがひとつあるだけで、欠陥になります。
大きい半導体チップだと、そこに一つでも欠陥があると、全部使えません(その回路だけを使わない救済方法はありますが、限度があります)。
なので、小さいチップ面積にした方が、全体の歩留まりが良くなります。大きいチップだと、1チップ不良だと歩留まり低下が大きいですが、小さいチップだと1チップ不良でも相対的な歩留まり低下は小さくなります。
小さいチップを重ねたり、平面に配置したりします
ただ、小さくすると、性能が頭打ちになります。特にGPUは回路数が命のようなところがありますので、できれば大きくしたいところです。
そこで、小さいチップを複数使用する方法が開発されました。
これが、「チップレット」「マルチチップモジュール」とか呼ばれるものです。
ただ、高速にチップ同士の情報をやりとりする必要があるので、チップと同じSi基盤に垂直に回路を作ったTSV(through-silicon via)が使われることが多いです。最近だと、Si基盤を使わずに樹脂基盤を検討したり、チップをそのまま重ねたりとか、色々な手法が検討されています。
このあたりは、日本でも技術開発がさかんです。東京工業大学さんがコンソーシアムを立ち上げています。
企業では、TOWA(6315)、ソシオネクスト(6526)、イビデン(4062)、SCREENホールディングス(7735)、あたりが有名です。
さらに、GPUではモジュールを複数つなげたりします
この「チップレット」で大きくしたGPUですが、それをさらに複数つなげて大きなシステムにします。
こうなると、GPUとCPUの通信(NVLink)やブレードサーバー同士の通信も結構な技術が必要だと思います。(残念ながら、そのあたりの関係企業は調べ切れていません・・・)
TSMCも後工程の工場を作るとか作らないとか
TSMCは熊本に22nm/28nm、12/16nmの工場を立ち上げました。これはプロセスルールで言うと、2010年前後の枯れたプロセスになります。
しかし、計画中の第二工場は6nm程度と2020年前後の結構新しいプロセスです。
さらに、後工程の工場も作るとの噂もあります。(一応、TSMCは公式に回答していませんが・・・)
日本も、この辺りの先端半導体の工場が広がっていくと良いなーと期待しています。
まとめと感想
半導体のプロセスルールの変遷とチップレット技術について、簡単に調べてみました。
2000年代でさえ、「かなり限界で、ムーアはもう無理だなー」と思っていましたが、さらに限界に近づいた感があります。それでも、後工程も駆使して、なんとか「ムーアの法則」の延長を図っているのだなと感じました。