ローランドDGの特許情報で共起ネットワークを作ってみました

ローランドDGのMBOが決まったそうです。
以前、ローランドDGのMBOとTOBについての記事を書きましたが、その中で、「特許情報を共起ネットワークにすれば、概要がわかるんじゃないかなー」と書いてしまったので、簡単に作ってみました。
共起ネットワークとは
共起ネットワークについて
テキスト中の語句同士がどんなペアで使われているかをネットワーク図にしたものです。
詳しくは、Nonさんのnote記事で紹介されていますので、こちらを読んでいただくのが良いと思います。さらにNonさんは、Pythonでの作り方まで書かれていて、とても参考になります。
私はKH Coderを使いました
私は手抜きをして、KH Coderを使いました。
KH Coderは立命館大学の樋口教授が作られた、テキストマイニングのアプリケーションです。最近、有料になったようですが、無料の機能でも充分にテキストマイニングが体験できます。
今回ご紹介する共起ネットワーク図は無料バージョンで作成しています。
ローランドDGの特許情報
特許情報はj-platpatからいただきました
特許情報は特許庁のj-platpatからダウンロードしました。
特許の全体像
ローランドDGが出願人に入っている特許は1720件です。
発明の名称はインクジェットプリンタやプリンタが上位にあります。
ただ、名称だけではどんな技術を対象としているかがわかりにくいです。

要旨をテキストマイニングしました
j-platpatでは、特許明細まで見ることが可能ですが、残念ながら1件ずつダウンロードする必要があります。市販のデータベースなら一括処理が可能だと思いますが、個人で使用するには高価すぎます。と、言ってもj-platpatで一件ずつダウンロードするのも面倒ですので、手抜きしました。
幸いj-platpatでも、要旨までは件数制限はありますが、一括ダウンロードが可能です(明細書本文は無理)。この機能を使って、2016年以降の特許の要旨をダウンロードしました。約1000件の特許となりました。
要旨をひとつのテキストファイルにまとめて共起ネットワークを作成しました
KH Coderの無料版では機能が限定されていて、複数のテキストは上限が設けられています。そこで、今回は要旨を一つのテキストにまとめて解析しました。(本来は別テキストにしておいた方が、解析の幅が広がります)
作成した共起ネットワークを下記に示します。
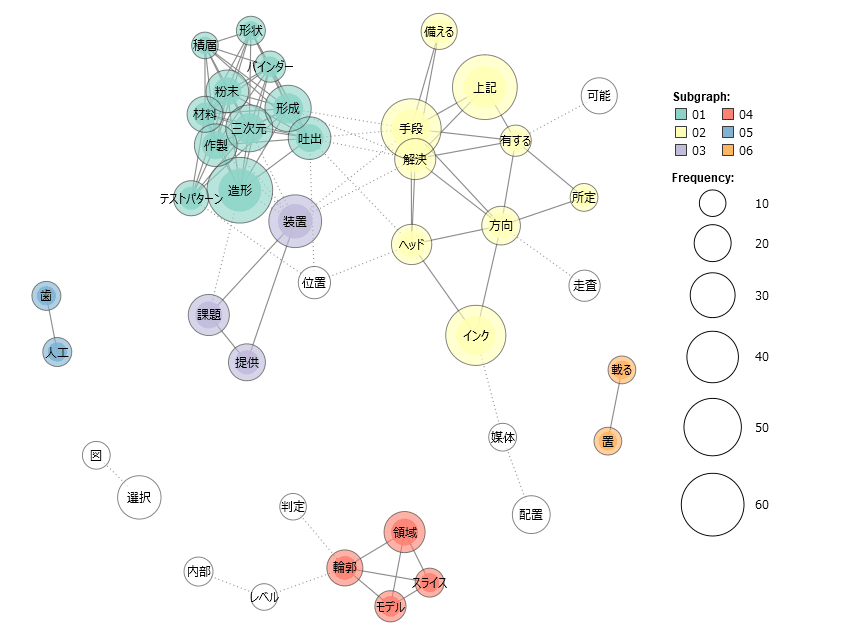
それぞれの語句がどのような繋がりになっているかを図示しています。
円の大きさは語句の出現頻度です。
これを見ると以下のことが解ります。
・ヘッド、インク、方向、走査と言う語句を使っているので、
インクジェットプリンタの細かい使い方の特許
・三次元、造形、粉末、バインダーと言う語句を使っているので、
3Dプリンタ関係の特許
・輪郭、領域、モデル、スライスという語句を使っているので、
3Dモデルの検出or3Dプリンタ関係の特許
・人工、歯という語句を使っているので、
人工歯の特許
これ以外にも図、選択、解決、手段、備える、有する、といった特許明細書に特有の語句が使われています。
KH Coderは共起ネットワーク中の語句をクリックすると、その語句が使われている文を抽出してくれます。
例えば、「方向」は以下のような文の中で使われていました。

これらを総合すると、特許においてはインクジェットプリンタの応用特許(周辺特許)と3Dプリンタの特許が多そうな印象を受けます。
応用特許とは基本特許と相対する言葉です。基本特許とは根幹の特許となるものを指します。
有名な例では「切り餅にスリットを入れて、餅の膨らみかたを制御する」みたいな特許です。
これに対し、応用特許とは「切り餅のスリットを、餅の短辺側のみに入れる」とか「切り餅のスリットを、餅の長辺側のみに入れる」とかになります。餅に入れるスリットのバリエーションで多量の特許が作れます。(実際には効果が明確に異なる必要がありますが・・・)
一般的には応用特許だけでは、基本特許をもっている企業に勝てないです。まあ、基本特許はそうそう簡単に作成できませんので応用特許が主体になることが多いです。その応用特許でどれだけ有効な特許網を作るかが勝負だったりします・・・。
基本特許を持っていない場合、応用特許で細かい周辺部分を押さえてクロスライセンスに持ち込めればOKだったりします。それでも、応用特許だけでは中々有効な特許網を構築することは難しいです。
ローランドDGの場合、MBOとTOBのやりとりの際に、「インクジェットヘッドはベンダー依存」ということを明らかにしていますので、「インクジェットヘッドをどのように使うか」というような応用特許が多いと感じます。
これ以上の特許解析をしようと思うと、明細書を手に入れて詳細解析をする必要があります。
ただ、こんな簡易な調査でも、概要は分かったと思います。
しかも、1000件以上の要旨を読むのも結構手間ですので、あらかじめテキストデータをテキストマイニングしておいて概要を把握した後に、個別の特許を詳細に確認するのは、効率的であると感じます。
まとめと感想
ローランドDGの特許の要旨をテキストマイニングして共起ネットワークを作成しました。
1000件を超える特許の概要が比較的簡単につかめたと思います。
ただし、この結果は「出現頻度の多い語句」を対象としている欠点があります。もし、この特許群の中で1件だけ物凄い基本特許があったとしても、漏れてしまう可能性があります。
なので、共起ネットワーク等で概要を見て、細かい部分は別の方法で確認するのが必要だと思います。
生成AIで箇条書きにしたり要約文を作ったりする場合にも、出現頻度に引っ張られる傾向はありますので、あくまでも参考データとして使うのが良いと思っています。
(そもそも、私は生成AIの出力を信じていませんので・・・。)