
第2回: 大規模言語モデル(LLM)の基本

本章ではLLMの技術背景、代表的なモデル(例: GPT)の説明、テキスト生成の仕組み、ファインチューニングの実例について解説していきます。
LLMの技術背景
大規模言語モデル(Large Language Models、LLMs)は、自然言語処理(NLP)の分野で驚異的な進歩を遂げています。これらのモデルは、膨大なテキストデータを用いて学習し、人間のようにテキストを生成、理解、翻訳、要約する能力を持っています。LLMの開発は、ニューラルネットワーク、特にトランスフォーマーモデルの進化と密接に関連しています。
トランスフォーマーモデルの概要
トランスフォーマーモデルは、2017年にVaswaniらによって提案された「Attention is All You Need」という論文で紹介されました。トランスフォーマーの中心的なアイデアは、セルフアテンション機構に基づいており、これによりモデルは入力シーケンス全体を一度に見渡し、各要素間の関係を効率的に捉えることができます。
以下にトランスフォーマーモデルの基本的なアーキテクチャを示します。
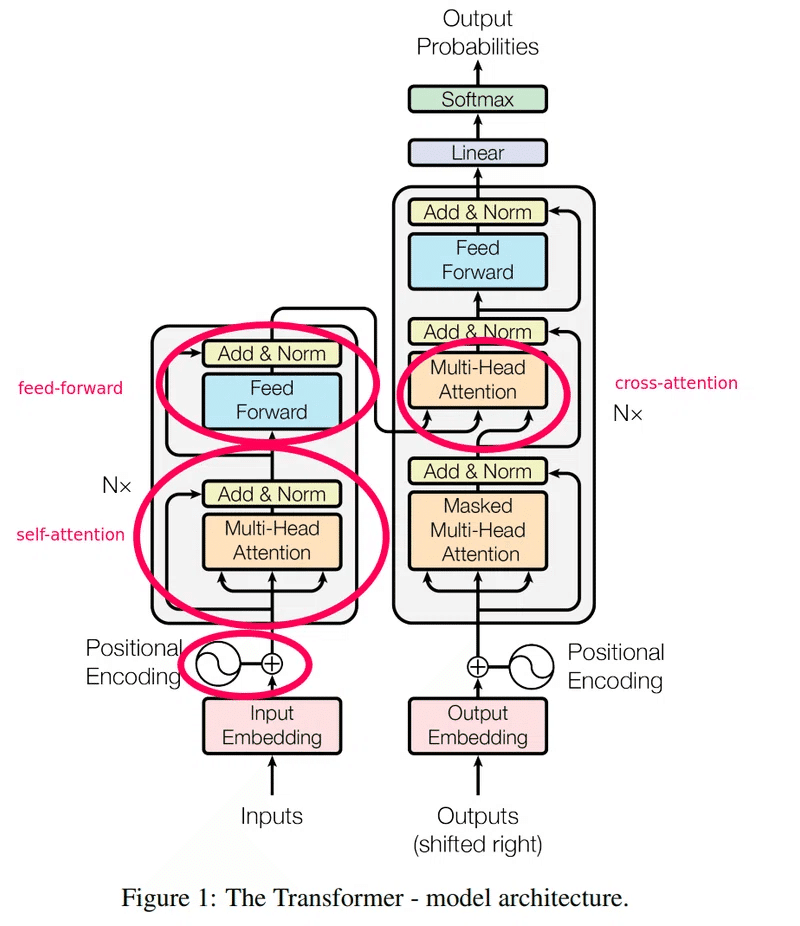
セルフアテンション機構
セルフアテンション機構の数式は以下の通りです。
$$
Attention(Q,K,V) = softmax(\frac {QK^T} {\sqrt {d_k}})V
$$
ここで、Q(Query)、K(Key)、V(Value)はそれぞれ異なる重み行列で変換された入力シーケンスです。セルフアテンションは、各単語がシーケンス内の他の単語に対してどれだけ注意を払うべきかを計算します。
代表的なモデル: GPT
Generative Pre-trained Transformer(GPT)は、OpenAIによって開発された代表的な大規模言語モデルです。GPTの基本的なアーキテクチャはトランスフォーマーに基づいており、大量のテキストデータで事前訓練され、様々なNLPタスクに適応可能です。
GPTモデルのアーキテクチャ図を以下に示します。
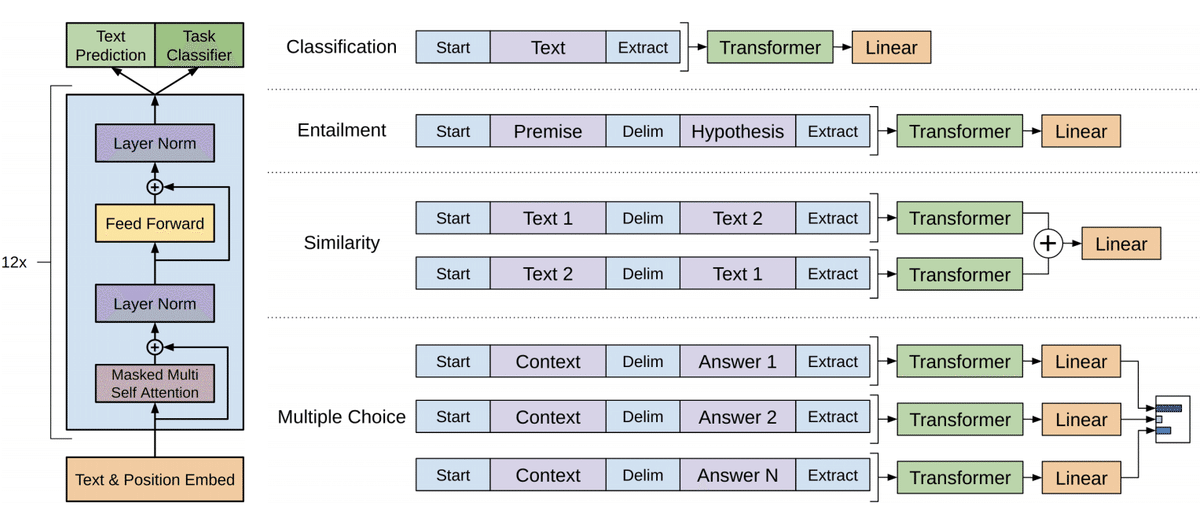
(左図)事前学習、(右図)ファインチューニング
テキスト生成の仕組み
GPTのテキスト生成プロセスは以下のステップで行われます。
トークナイゼーション: 入力テキストをトークンに分割します。
エンコーディング: 各トークンを埋め込みベクトルに変換します。
アテンション計算: セルフアテンション機構を用いて各トークンの重要度を計算します。
デコーディング: 次のトークンを生成し、再帰的にプロセスを繰り返します。
Pythonでの基本的なテキスト生成例
以下に、Pythonを用いたGPTモデルでのテキスト生成の基本的な例を示します。
import torch
from transformers import GPT2LMHeadModel, GPT2Tokenizer
# モデルとトークナイザーのロード
model_name = 'gpt2'
model = GPT2LMHeadModel.from_pretrained(model_name)
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
# テキストの入力
input_text = "Once upon a time"
input_ids = tokenizer.encode(input_text, return_tensors='pt')
# テキストの生成
output = model.generate(input_ids, max_length=50, num_return_sequences=1)
# 生成されたテキストのデコード
generated_text = tokenizer.decode(output[0], skip_special_tokens=True)
print(generated_text)Once upon a time, the world was a place of great beauty and great danger. The world was a place of great danger, and the world was a place of great danger.
大規模言語モデル(LLM)のファインチューニング方法
大規模言語モデル(LLM)のファインチューニングは、特定のタスクやドメインに適応させるために、事前学習されたモデルを追加データで再訓練するプロセスです。これにより、モデルの性能を向上させ、特定の要求に応じた応答を生成する能力を高めます。以下に、技術的なアプローチを踏まえ、ファインチューニングの具体的な手法とPythonスクリプトを含めて解説します。
技術的アプローチ
ファインチューニングは以下の手順で行われます:
事前学習されたモデルのロード: 通常、事前学習された大規模言語モデル(例:GPT-3.5/4/4o)を使用します。これらのモデルは、巨大なコーパスでトレーニングされており、言語の一般的なパターンを学習しています。
タスク固有のデータセットの準備: ファインチューニングには、特定のタスクやドメインに関連するデータセットが必要です。このデータセットには、入力とターゲットのペアが含まれます。
モデルの調整: 事前学習されたモデルを基に、タスク固有のデータセットで再訓練を行います。これにより、モデルは特定のパターンや知識を学習します。
評価とテスト: ファインチューニング後のモデルを評価し、性能を確認します。必要に応じてハイパーパラメータの調整や再訓練を行います。
数式による説明
ファインチューニングは、事前学習されたモデルのパラメータ θ を初期値として、特定のタスクの損失関数 L を最小化するプロセスです。タスク固有のデータセット D が与えられたとき、パラメータは以下のように更新されます:
$$
θ^′ = θ - η∇_θL(D, θ)
$$
ここで、η は学習率を示します。
Pythonによるファインチューニングの実装
以下に、GPT-3.5モデルをファインチューニングする例を示します。
最近ではLangChainやRAG(Retrieval-Augmented Generation)を活用して、外部データを参照して回答を生成する手法がよく使われています。(これらの詳細は別章または番外編として紹介しようと思います。)
1. 必要なライブラリのインストール
まず、必要なライブラリをインストールします。
!pip install openai2. OpenAI API キーの取得
OpenAIのファインチューニング機能を使用するためには、APIキーが必要です。OpenAIのアカウントを作成し、APIキーを取得してください。
from openai import OpenAI
# OpenAI APIキーを設定
client = OpenAI(
# This is the default and can be omitted
api_key="OPENAI_API_KEY", #自身のAPIキーを設定
)3. データセットの準備
ファインチューニングには、特定の形式のデータセットが必要です。データセットは、jsonl形式で作成します。jsonlとはjsonオブジェクトを1行ごとに区切った形式です。
今回作成したデータセットの training_data.jsonl は以下のようになります。
{"messages": [{"role": "system", "content": "Penguin Labs sample."}, {"role": "user", "content": "ペンギンラボとは何ですか?"}, {"role": "assistant", "content": "データサイエンスの会社です。"}]}
{"messages": [{"role": "system", "content": "Penguin Labs sample."}, {"role": "user", "content": "ペンギンラボの名前の由来は何ですか?"}, {"role": "assistant", "content": "ファーストペンギンです。"}]}
{"messages": [{"role": "system", "content": "Penguin Labs sample."}, {"role": "user", "content": "ペンギンラボの所在地は?"}, {"role": "assistant", "content": "東京都中央区です。"}]}
{"messages": [{"role": "system", "content": "Penguin Labs sample."}, {"role": "user", "content": "ペンギンラボのメンバーは何人ですか?"}, {"role": "assistant", "content": "現在は3人です。"}]}
{"messages": [{"role": "system", "content": "Penguin Labs sample."}, {"role": "user", "content": "ペンギンラボの設立時期はいつですか?"}, {"role": "assistant", "content": "2024年3月です。"}]}
{"messages": [{"role": "system", "content": "Penguin Labs sample."}, {"role": "user", "content": "ペンギンラボのメンバーの出身地は?"}, {"role": "assistant", "content": "全メンバー関西出身です。"}]}
{"messages": [{"role": "system", "content": "Penguin Labs sample."}, {"role": "user", "content": "ペンギンラボの畑で栽培している野菜は?"}, {"role": "assistant", "content": "コールラビや、トマトや枝豆です。"}]}
{"messages": [{"role": "system", "content": "Penguin Labs sample."}, {"role": "user", "content": "ペンギンラボのミッションは?"}, {"role": "assistant", "content": "データを最大限活用して世界を変えることです。"}]}
{"messages": [{"role": "system", "content": "Penguin Labs sample."}, {"role": "user", "content": "ペンギンラボのお休みは?"}, {"role": "assistant", "content": "今のところ年中無休です。"}]}
{"messages": [{"role": "system", "content": "Penguin Labs sample."}, {"role": "user", "content": "ペンギンラボの特徴は?"}, {"role": "assistant", "content": "やりたいことをやり、働きたいときに働きます。"}]}4. データファイルのアップロード
以下のPythonスクリプトを使用して、データファイルをアップロードします。
# トレーニングデータのアップロード
training_file = client.files.create(
file=open("training_data.jsonl", "rb"),
purpose="fine-tune",
)
print(training_file)<output4>
FileObject(id='file-xxxxx', bytes=2244, created_at=1718158292, filename='training_data.jsonl', object='file', purpose='fine-tune', status='processed', status_details5. ファインチューニングのジョブを作成
以下のスクリプトでファインチューニングジョブを作成します。
# ファインチューニングのジョブを作成
fine_tune_response = client.fine_tuning.jobs.create(
training_file=training_file.id,
model="gpt-3.5-turbo" # ここで使用するベースモデルを指定
)
print(fine_tune_response)<output5>
FineTuningJob(id='ftjob-yyyyy', created_at=1718158296, error=Error(code=None, message=None, param=None), fine_tuned_model=None, finished_at=None, hyperparameters=Hyperparameters(n_epochs='auto', batch_size='auto', learning_rate_multiplier='auto'), model='gpt-3.5-turbo-0125', object='fine_tuning.job', organization_id='org-zzzzz', result_files=[], seed=679407095, status='validating_files', trained_tokens=None, training_file='file-xxxxx', validation_file=None, estimated_finish=None, integrations=[], user_provided_suffix=None)6. ファインチューニングのステータスを確認
ファインチューニングのステータスを確認するには、以下のスクリプトを使用します。
# ファインチューニングのステータスを確認
status = client.fine_tuning.jobs.retrieve(fine_tune_response.id)
print(status)<output6-1>
FineTuningJob(id='ftjob-yyyyy', created_at=1718158296, error=Error(code=None, message=None, param=None), fine_tuned_model=None, finished_at=None, hyperparameters=Hyperparameters(n_epochs=10, batch_size=1, learning_rate_multiplier=2), model='gpt-3.5-turbo-0125', object='fine_tuning.job', organization_id='org-zzzzz', result_files=[], seed=679407095, status='running', trained_tokens=None, training_file='file-xxxxx', validation_file=None, estimated_finish=1718158694, integrations=[], user_provided_suffix=None)response = client.fine_tuning.jobs.list_events(fine_tune_response.id)
events = response.data
events.reverse()
for event in events:
print(event.message)<output6-2>
(前略)
Step 95/100: training loss=0.00
Step 96/100: training loss=0.00
Step 97/100: training loss=0.00
Step 98/100: training loss=0.00
Step 99/100: training loss=0.00
Step 100/100: training loss=0.00
Checkpoint created at step 80 with Snapshot ID: ft:gpt-3.5-turbo-0125:personal::abcdefgh:ckpt-step-80
Checkpoint created at step 90 with Snapshot ID: ft:gpt-3.5-turbo-0125:personal::abcdefgh:ckpt-step-90
New fine-tuned model created: ft:gpt-3.5-turbo-0125:personal::abcdefgh
The job has successfully completed7. ファインチューニングモデルの使用
ファインチューニングが完了したら、新しいモデルを使用してテキスト生成を行います。
# ファインチューニングされたモデルを使用してテキストを生成
response = client.chat.completions.create(
model="ft:gpt-3.5-turbo-0125:personal::abcdefgh", #fine-tuned model
messages=[
{"role": "system", "content": "Penguin Labs sample."},
{"role": "user", "content": "ペンギンラボの畑で栽培している野菜は?"}
]
)
print(response.choices[0].message)ChatCompletionMessage(content='コールラビや、トマトや枝豆です。', role='assistant', function_call=None, tool_calls=None)
# ファインチューニングされたモデルを使用してテキストを生成
response = client.chat.completions.create(
model="ft:gpt-3.5-turbo-0125:personal::abcdefgh", #fine-tuned model
messages=[
{"role": "system", "content": "Penguin Labs sample."},
{"role": "user", "content": "ペンギンラボの売上高は?"}
]
)
print(response.choices[0].message)ChatCompletionMessage(content='非公開です。', role='assistant', function_call=None, tool_calls=None)
まとめ
大規模言語モデルは、自然言語処理の分野で革命をもたらしています。トランスフォーマーモデルとそのセルフアテンション機構に基づくLLMは、テキスト生成、翻訳、要約など多岐にわたる応用が可能です。GPTのようなモデルは、その膨大なパラメータとトレーニングデータにより、人間のように自然な文章を生成する能力を持っています。今後もLLMの進化とともに、さらなる技術革新が期待されます。またファインチューニングは、事前学習された大規模言語モデルを特定のタスクやドメインに適応させるための強力な手法です。適切なデータセットとモデルを用いることで、精度の高い特定用途向けの言語モデルを構築できます。
次章では、画像生成AIの技術背景や応用例について詳しく探っていきます。