
第3回: 画像生成AIの進化

本章では画像生成技術の歴史と進化、DALL-E、StableDiffusion、Midjourneyなどの代表的なモデルの紹介、ファインチューニング方法の事例を説明していきます。
画像生成技術の歴史と進化
画像生成技術は、初期のコンピュータグラフィックスから始まり、現在のディープラーニングに至るまで飛躍的な進化を遂げてきました。この進化の中でも特に注目されるのが、ジェネレーティブ・アドバーサリアル・ネットワーク(GAN)やラテントディフュージョンモデル(LDM)です。
初期の画像生成技術
初期の画像生成技術は、主にレンダリング技術に依存していました。例えば、Ray tracingやPhong shadingなどの技術は、光の反射や屈折を計算してリアルな画像を生成するものでした。
機械学習とディープラーニングの導入
2000年代以降、機械学習とディープラーニングが導入され、特にGANの登場は画期的でした。GANは、生成者(ジェネレーター)と識別者(ディスクリミネーター)の二つのネットワークを競わせることで、非常に高品質な画像を生成します。
# 簡単なGANの例
import tensorflow as tf
from tensorflow.keras import layers
# 生成者モデル
def make_generator_model():
model = tf.keras.Sequential()
model.add(layers.Dense(256, use_bias=False, input_shape=(100,)))
model.add(layers.LeakyReLU())
model.add(layers.Dense(512, use_bias=False))
model.add(layers.LeakyReLU())
model.add(layers.Dense(28 * 28 * 1, use_bias=False, activation='tanh'))
model.add(layers.Reshape((28, 28, 1)))
return model
# 識別者モデル
def make_discriminator_model():
model = tf.keras.Sequential()
model.add(layers.Flatten(input_shape=(28, 28, 1)))
model.add(layers.Dense(512))
model.add(layers.LeakyReLU())
model.add(layers.Dense(256))
model.add(layers.LeakyReLU())
model.add(layers.Dense(1, activation='sigmoid'))
return model
generator = make_generator_model()
discriminator = make_discriminator_model()LDM: Latent Diffusion Model(潜在拡散モデル)
Latent Diffusion Model(LDM)は、ディフュージョンプロセスを用いた生成モデルであり、特に画像生成の分野で注目されています。LDMは、画像データを低次元の潜在空間にマッピングし、その空間でノイズを追加・除去するプロセスを通じて新しい画像を生成します。
LDMの基本的なメカニズム
Encoding(エンコーディング): まず、入力画像を低次元の潜在空間にマッピングします。これにより、画像の高次元データが圧縮され、重要な特徴だけが抽出されます。
Diffusion Process(ノイズ付加): 潜在空間にノイズを加えます。これは、潜在空間でのデータの多様性を増やし、生成される画像のバリエーションを高めるためです。
Denoising Process(ノイズ除去): 潜在空間でのノイズを徐々に除去し、デノイズされた潜在表現を生成します。このプロセスは、潜在空間の中で繰り返し行われます。
Decoding(デコーディング): 最後に、デノイズされた潜在表現を高次元の画像空間にマッピングし、最終的な生成画像を得ます。
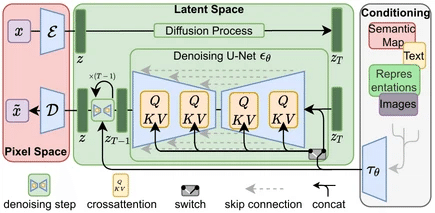
画像生成におけるLDMの重要性
画像生成において以下の理由で非常に重要です:
効率性: 潜在空間で操作を行うため、高次元の画像空間で直接操作するよりも計算効率が高いです。これにより、大規模なデータセットに対しても高速に処理できます。
高品質な画像生成: 潜在空間でのノイズ付加と除去のプロセスにより、生成される画像は高品質であり、詳細な部分までしっかりと再現されます。特に、複雑なパターンやテクスチャを持つ画像の生成において、その効果が顕著です。
多様性: ノイズ付加によるデータの多様性が、生成される画像のバリエーションを増やします。これにより、単一のプロンプトからでも多様な画像が生成可能です。
スケーラビリティ: LDMは、様々なスケールのデータセットに対応可能です。小規模なデータセットから大規模なデータセットまで、効率的に対応できる柔軟性があります。
具体的なLDMの実装例
以下は、PyTorchを使用したLDMの簡単な実装例です。実際のモデルはさらに複雑ですが、基本的な流れはこの通りです。
import torch
import torch.nn as nn
class LatentDiffusionModel(nn.Module):
def __init__(self):
super(LatentDiffusionModel, self).__init__()
self.encoder = Encoder()
self.decoder = Decoder()
def forward(self, x):
z = self.encoder(x)
z_noisy = z + torch.randn_like(z) # ノイズ付加
z_denoised = self.denoise(z_noisy)
x_reconstructed = self.decoder(z_denoised)
return x_reconstructed
def denoise(self, z):
# ディフュージョンプロセスによるデノイズ処理(簡略化)
for _ in range(10): # 反復回数は実際にはもっと多い
z = z - 0.1 * torch.randn_like(z) # ノイズ除去のステップ
return z
# モデルのインスタンス化
model = LatentDiffusionModel()
# ダミーの入力画像
dummy_input = torch.randn(1, 1, 28, 28)
# モデルの実行
output = model(dummy_input)
print(output.shape)代表的なモデルの紹介
DALL-E
OpenAIによって開発されたDALL-Eは、GPT-3の技術を基にしており、テキストプロンプトから画像を生成する能力を持っています。DALL-Eは、多種多様なスタイルと内容を持つ画像を生成することができ、その精度と創造性は驚異的です。
StableDiffusion
StableDiffusionは、ディープラーニングを用いた画像生成モデルで、生成画像の安定性と多様性に優れています。特に、画像の細部にわたる品質が高く、広く応用されています。
Midjourney
Midjourneyは、クリエイティブな画像生成に特化したモデルであり、アートやデザインの分野で注目されています。このモデルは、抽象的で美しい画像を生成する能力に優れており、多くのアーティストやデザイナーに利用されています。
画像生成モデルのファインチューニング
画像生成AIにおけるファインチューニングは、特定のデータセットに対してモデルを調整し、生成結果を改善するプロセスです。以下に、画像生成モデルのファインチューニング手法について詳しく説明します。
ファインチューニングは、一般的に以下の手順で行われます:
モデルの準備: 事前トレーニング済みのモデルをロードします。
データセットの準備: モデルをファインチューニングするための特定のデータセットを用意します。
ファインチューニングの設定: ハイパーパラメータ、オプティマイザ、学習率スケジューラなどを設定します。
トレーニング: データセットを使用してモデルをトレーニングし、パラメータを調整します。
モデルの保存: ファインチューニングされたモデルを保存します。
LoRAを活用したファインチューニング手法
Stable Diffusionのファインチューニング方法について詳しく説明します。LoRA (Low-Rank Adaptation)は、事前学習済みモデルのAttention層のクエリとバリューに対して、低ランク行列を適用することで、パラメータ数を大幅に削減しながらトレーニングやファインチューニングを効率的かつ効果的に行うアプローチです。特に、トランスフォーマーモデルなどの大規模モデルに適しています。以下に、LoRAを使ってモデルをファインチューニングする方法を具体的に説明します。


必要なライブラリのインストール
まず、必要なPythonライブラリをインストールします。
!pip install torch torchvision transformers diffusers accelerateモデルのロード
SatableDiffusionモデルをロードします。正しいモデル名を使用し、accelerateライブラリを用いてモデルを効率的にロードします。
import torch
from diffusers import StableDiffusionPipeline
from transformers import AutoTokenizer, CLIPTextModel
from accelerate import Accelerator
# モデルとトークナイザーのロード
model_name = "runwayml/stable-diffusion-v1-5"
accelerator = Accelerator()
device = accelerator.device
pipeline = StableDiffusionPipeline.from_pretrained(model_name, torch_dtype=torch.float16, revision="fp16")
pipeline.to(device)
# トークナイザーのロード
tokenizer = AutoTokenizer.from_pretrained("openai/clip-vit-large-patch14")データセットの準備
画像データセットを用意します。ここでは、ImageFolder形式のデータセットを使用します。
from torchvision.datasets import ImageFolder
from torchvision import transforms
from torch.utils.data import DataLoader
transform = transforms.Compose([
transforms.Resize((512, 512)),
transforms.ToTensor()
])
train_dataset = ImageFolder(root='path_to_your_dataset', transform=transform) # root_dir
train_loader = DataLoader(train_dataset, batch_size=4, shuffle=True)(補足)ImageFolderのフォルダ構造
ImageFolderを使用するためには、特定のフォルダ構造を守る必要があります。具体的には、以下のようなディレクトリ構造になります。
root_dirはデータセットのルートディレクトリです。
class_a, class_b, ... は各クラスごとのディレクトリで、それぞれのディレクトリに画像ファイルが含まれます。
root_dir/
class_a/
img1.jpg
img2.jpg
...
class_b/
img1.jpg
img2.jpg
...
...LoRAの適用
LoRA (Low-Rank Adaptation)を使用して、モデルの特定のレイヤーを微調整します。
import torch.nn as nn
import loralib as lora
# LoRAを適用する関数
def apply_lora(model, rank=4):
for name, module in model.named_modules():
if isinstance(module, nn.Linear):
in_features, out_features = module.in_features, module.out_features
lora_module = lora.Linear(in_features, out_features, rank)
lora_module.weight.data = module.weight.data
lora_module.bias = module.bias
lora_module.to(device, dtype=torch.float16) # Cast LoRA parameters to float16
parent = model
for part in name.split('.')[:-1]:
parent = getattr(parent, part)
setattr(parent, name.split('.')[-1], lora_module)
# UNetモデルにLoRAを適用
apply_lora(pipeline.unet)トレーニングの設定
ファインチューニングの設定を行います。
from transformers import AdamW, get_scheduler
# ハイパーパラメータの設定
num_epochs = 3
learning_rate = 5e-5
optimizer = AdamW(pipeline.unet.parameters(), lr=learning_rate)
lr_scheduler = get_scheduler(
"linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_epochs * len(train_loader)
)
criterion = nn.MSELoss()トレーニング
トレーニングループを定義し、モデルのファインチューニングを実行します。
pipeline.unet.train()
for epoch in range(num_epochs):
for batch in train_loader:
inputs = batch[0].to(device, dtype=torch.float16) # 画像データを取得しGPUに転送
# テキストのエンコード
text_inputs = tokenizer(["Example prompt"] * inputs.size(0), return_tensors="pt", padding=True, truncation=True).input_ids.to(device)
text_embeddings = pipeline.text_encoder(text_inputs).last_hidden_state
# モデルの予測と損失計算
latents = pipeline.vae.encode(inputs).latent_dist.sample()
latents = latents * 0.18215
noise = torch.randn_like(latents)
timesteps = torch.randint(0, 1000, (latents.size(0),), device=latents.device).long()
noisy_latents = pipeline.unet(latents, timesteps, text_embeddings).sample
loss = criterion(noisy_latents, noise)
# 勾配の計算と最適化ステップ
optimizer.zero_grad()
loss.backward()
optimizer.step()
lr_scheduler.step()
print(f"Epoch {epoch+1}/{num_epochs}, Loss: {loss.item()}")
# モデルの保存
pipeline.save_pretrained("path_to_save_your_model")学習済みモデルのロード
保存したモデルをロードします。
import torch
from diffusers import StableDiffusionPipeline
# 保存したモデルのパス
model_path = "path_to_save_your_model"
# モデルのロード
pipeline = StableDiffusionPipeline.from_pretrained(model_path, torch_dtype=torch.float16)
pipeline = pipeline.to("cuda")画像生成
ロードしたモデルを使用して画像を生成します。ここでは、プロンプトを指定してテキストから画像を生成します。
# 画像生成のプロンプト
prompt = "A futuristic city skyline at sunset"
# 画像生成
with torch.autocast("cuda"):
image = pipeline(prompt).images[0]
# 生成された画像を保存
image.save("generated_image.png")まとめ
Latent Diffusion Model (LDM)は、効率的かつ高品質な画像生成を実現するための革新的な技術です。その潜在空間での操作とディフュージョンプロセスにより、生成される画像の多様性と品質を大幅に向上させることができます。LDMの導入により、画像生成AIの可能性はさらに広がり、さまざまな分野での応用が期待されています。
またDALL-E、StableDiffusion、Midjourneyなどの代表的なモデルは、それぞれ異なるアプローチで高品質な画像を生成し、さまざまな分野での応用が期待されています。これからも技術の進化により、さらに多様で高度な画像生成が可能になることでしょう。
画像生成AIのファインチューニングは、特定のデータセットに基づいてモデルを微調整し、生成品質を向上させるための重要なステップです。上記の手順に従って、特定のタスクやドメインに対するモデルのパフォーマンスを向上させることができます。特にStable Diffusionのようなモデルを使用することで、高品質な画像生成が可能となります。
次章では、最近進歩の著しい動画生成AIについて探っていきます。
この記事が気に入ったらサポートをしてみませんか?