
ゼロから作るDiffusionモデル:最先端の画像生成技術を探る

はじめに
はじめまして。ギリアのインターン生、上津原です。
この記事では、近年注目を集めているDiffusionモデルをゼロから実装、学習させた成果として、その過程で学んだ関連技術の概観と、それらを活用した生成テクニックについて紹介していきます。
Diffusionモデルは微分方程式を使った数式で説明されることが多いため、人によっては難しいと感じることがありますが、本記事では初めての人でも分かるように簡単な言葉を使った解説を心がけてみました。
この記事を通して画像生成AIに関する理解を深めていただければ幸いです。
Diffusionモデルとは
Diffusionモデル [1]はノイズ除去を通じて画像を生成します。分かりやすくするため、これ以降、画像生成プロセスと表記します。
まず、入力画像にノイズを加え、画像の特徴が完全になくなるまで劣化させます。その後、ノイズを徐々に除去しながら、画像の特徴を復元するように学習します。この復元プロセスでは、初めに画像全体の大まかな特徴が復元され、最後に細部が復元されます。

長所
・高精度
Diffusionモデルは、複数のステップを通じて画像を生成するため、細部まで正しく描写された指示通りの画像を生成できます。
・学習の安定性
従来使われていたGAN [2]では生成器と識別器が連携しながら学習していたため、2つのモデルの精度を同程度に保たなければ学習が失敗してしまい、学習が不安定でした。一方Diffusionでは1つのモデルで完結しているので学習が安定します。
短所
・遅い生成速度
Diffusionモデルは複数のステップを経て画像を生成するため、1ステップで生成するGANと比べて生成速度が遅くなります。
Diffusionモデルを支える技術
Diffusionモデルは、前述の通りノイズ除去を通じて画像を生成しており、そのために画像の特徴を抽出し再構築するUNet [3]というモデルが使用されています。ここで、入力画像の特徴などを表現する条件を画像生成プロセスの際に手がかりとして与えると、条件付き画像生成が可能になります。Classifier Free Guidance(CFG) [4]という手法の登場により、条件付けの強さも調整が可能になりました。
Stable Diffusion [5]は文章を使った自在な画像生成が特徴で、これは、文章と画像を関連付けるCLIP [6]という技術を条件付けに用いることにより可能になりました。
Diffusionモデルの性能向上には、画像生成が複数ステップに分かれていることが寄与しているだけでなく、空間的に離れたピクセル間の関連を捉える技術であるVision Transformer(ViT)[7]も、精度の向上に大きく貢献しています。
Diffusionモデルは狙い通りの画像生成が可能という反面、初期のモデルには動作が重いという欠点がありました。しかし、圧縮された画像データを使って学習を行うLatent Diffusion [8]モデルなどの登場により、解像度の高い画像の生成速度が大きく改善しました。
画像生成プロセス : UNet
前述の画像生成プロセスでは、ノイズの多い画像を与えてノイズの少ない画像を段階的に生成していきますが、この処理で使われるのがUNetです。
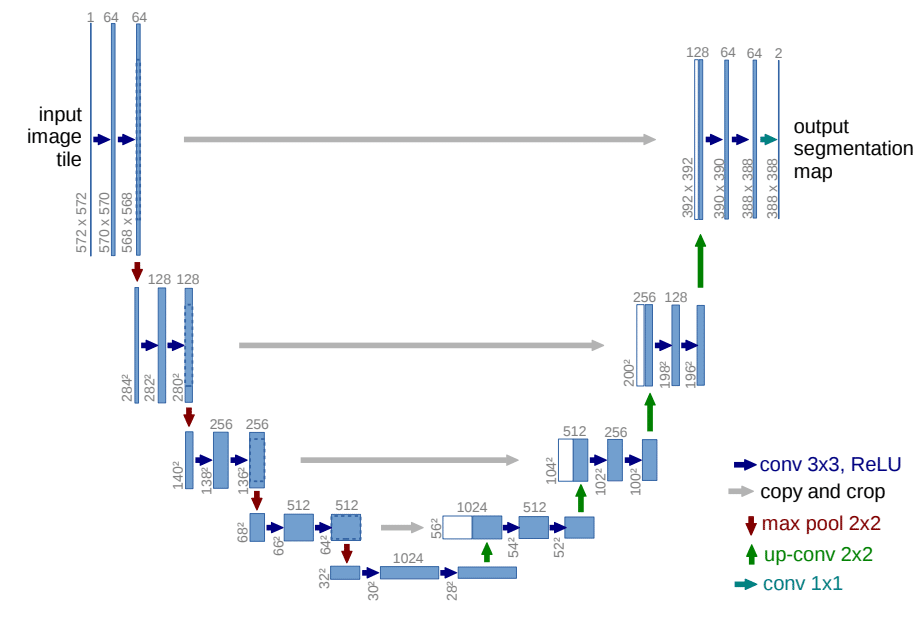
基本構造
・エンコーダー(下り経路)
画像を入力し、解像度を徐々に下げながら重要な特徴を抽出します。
・デコーダー(上り経路)
エンコーダーで抽出した特徴を基に、再び高解像度の画像を生成します。
・スキップ接続
エンコーダーとデコーダーの対応する層を直接結び、詳細な情報を保持します。
入力画像の解像度を下げることで冗長な情報が除去され、重要な特徴が抽出されます。デコーダーはスキップ接続を利用して、元の画像の細かい特徴を反映させつつ画像を再構築します。
Diffusionモデルの画像生成プロセスでは、生成する画像の種類や生成段階に応じて処理を変える必要があるため、UNetではなくConditional UNetを使用します。Conditional UNetは、与えた条件に応じて出力を変化させることができます。具体的には、生成したい画像やノイズ処理の段階といった情報を一つのベクトルに変換し、そのベクトルを元に特定の変換を適用します。この処理はThe Annotated Diffusion Model [9]においてコードと共に解説されています。
条件を強く出力に反映させる : Classifier Free Guidance (CFG)
CFGの値を大きくすると、指示した特徴が明確に現れますが、多様性が低くなり、同じ条件で生成された画像が類似することが多くなります。適切なCFGの値に設定することで、条件を無視した画像や、複数の被写体が混ざった画像の生成を防ぐことができます。

この手法では、条件付き画像生成モデルを学習させる際に、一定の確率で条件を外し、条件なしの画像生成も同時に学習させます。そして、条件付きの推論結果から条件なしの推論結果を引くことで、状態分布をはっきりと分離させます。この場合、生成される画像の多様性は減少しますが、曖昧な画像や条件を無視した画像は生成されにくくなります。
画像と文章の意味的な関連付け : CLIP
正しい画像の特徴ベクトルと文章の特徴ベクトルのペアの関連度を最大化するように学習し、画像と文章との意味的な関連性を把握することのできる機械学習モデルです。対応する画像と文章のペアの関連度を最大化する過程で、同じ意味を持つ画像と文章の特徴ベクトルが類似するようになります。

また、特徴ベクトルは、意味的に関連性が高いほど距離が近くなります。以下の画像からも似た色の画像が近くにあることが確認できます。

離れたピクセルの関連付け : Vision Transformer(ViT)
Vision Transformer(ViT)は、入力画像から最も重要な情報を選択し強調する Attention機構 [10]を利用した画像処理技術です。この手法を用いると、人間が文章を読むときに重要な単語に注目するのと同じように、画像の中から重要な情報を見つけ出し強調することができます。

従来のCNNは畳み込み層を重ねて局所的な特徴を把握し、画像全体の特徴を捉えていましたが、空間的に離れたピクセル間の関連を捉えることには制限がありました。一方、ViTは画像をより小さなパッチに分割し、これらのパッチ間の関係を全体的に学習することで、画像全体の文脈を捉えることができます。
仕組みは以下の通りです。
入力画像は、ニューラルネットワークを用いて、次の3つの情報に変換されます。
注目したい情報 (Query)
各部分の特徴 (Key)
画像情報 (Value)
まず、注目したい情報と各部分の特徴の関連度が計算されます。そして、関連度で画像情報を重み付けし、足し合わせたものが出力されます。
当初はパッチ数の2乗に比例して計算量が増えていましたが、計算量を線形増加に抑える手法としてLinear Attention [11]などが考案されています。
画像の圧縮 : Variational Autoencoder (VAE)
Variational Autoencoder (VAE) [12] は、UNetとほぼ同じ構造ですが、スキップ接続を持ちません。そのため、特徴ベクトルのみから画像を生成することができます。

UNetと比べ、VAEは特徴ベクトルのみの少ない情報で一般化された特徴を表現できるため、画像圧縮や復元タスクでよく使用されます。VAEは画像を潜在空間に圧縮し、その圧縮された情報を基に復元することで、画像全体の特徴を効果的に学習します。この特性により、VAEは入力にノイズが入っても出力が変化しにくいという特徴も持ちます。
圧縮データを使った学習 : Latent Diffusion
従来のDiffusionモデルがノイズ画像から出力画像を生成する一方で、この手法ではノイズ画像の特徴ベクトルから出力画像の特徴ベクトルを生成します。

生成手順は以下の通りです。
ノイズ画像の圧縮
画像にVAEを使用して圧縮した後に、潜在空間でノイズを加えます。Stable Diffusion V1.4の場合、画像はこのプロセスを通して元のデータ量の1/48(※)のサイズにまで圧縮され、処理しやすい特徴ベクトルに変換されます。これにより、データの扱いやすさが向上し、メモリの消費も抑えられます。
Diffusionモデルによる特徴の復元
圧縮された特徴ベクトルを基に、Diffusionモデルが複数のステップをかけて段階的に画像の特徴を復元します。このプロセスでは、各ステップで画像の詳細な特徴が徐々に明らかにされ、元の画像に近づいていきます。
圧縮された出力画像の復元
復元された特徴ベクトルは再びVAEを使用して元の画像サイズに拡大され、識別可能な出力画像に変換されます。この変換により、特徴ベクトルが実際の視覚的な画像データに復元され、元のノイズ画像とは異なる、明瞭な画像が生成されます。
※ Stable Diffusion V1.4の場合、画像サイズ : 512 x 512 x 3、特徴ベクトルサイズ : 64 x 64 x 4のため
実験
今回は、与えたベクトルを条件にして画像生成を行うDiffusionモデルを実装しました。そして、異なる条件付けを使った生成、条件を変化させた場合の生成画像の変化についてOxford102データセット [14]を用いて以下の手順で検証しました。
クラス条件付き生成 : クラスをPytorchのnn.Embedding [15]でベクトルに変換し、条件付き生成の精度を検証
文章条件付き生成 : CLIPを用いて文章と画像をベクトルに変換し、文章を基にした条件付き生成の精度を検証
条件付けの強度調整 : Classifier Free Guidance(CFG)を -10から10まで変化させ、生成画像の変化を視覚化
輪郭強調 : Rescaled phiを-10から10まで変化させ、生成画像の変化を視覚化
スタイル適応 : スタイルのかける強さを変更した場合の生成画像の変化を視覚化
クラス条件付き生成 : Class Conditioning
クラス条件付き生成では、曖昧な条件を取らず、クラスごとに明確に異なる条件を取るため、精度の高い画像を生成できます。

Stable Diffusionで使用されるテキスト条件付き生成は、大規模な事前学習モデルを用いないと正確な画像を生成することが困難です。しかし、クラス条件付き生成では、事前学習モデルを用いずにゼロから学習させても、図のような画像を生成することが可能です。RTX 3080相当のGPUなら、2時間程度の学習でこれを実現できます。
文章条件付き生成 : Clip Conditioning
この実験では、画像の特徴ベクトルを元にして学習を行いました。しかし、文章を一切学習させていないのにもかかわらず、文章の特徴ベクトルを指定しただけで狙い通りの画像が生成できています。

CLIPでは同じ意味を持つ画像と文章が、近い特徴ベクトルを持っています。そのため、例えば赤い花を示す文章を入力すると、赤い花の画像を入力した時と近い条件で画像を生成することができます。しかし、青い花、青紫の花を示す文章などでは、その文章を示す特徴ベクトルが黄色い花にも似ていたためか、黄色い花が誤って生成されています。
条件付けの強度調整 : Classifier Free Guidance(CFG)
生成させる画像が、ユーザーの指示にどれだけ忠実であるかを調整することができるパラメーターです。
数値が大きいほど、指示した特徴を正確に再現した画像が生成できますが、多様性が低くなります。

映像解説
映像前半 : CFG = -10
本来想定される0以上という条件を無視しているため、不自然に色つぶれした画像が出力されています。画像の種類も指定した条件と関係ないものが出力されています。
映像中間 : CFG = 0
条件を無視してはいるものの、自然な画像が生成されています。
映像後半 : CFG = 10
与えた条件に忠実に従っているものの、彩度が高く油彩画のような質感の画像が生成されています。この映像からは分かりませんが、CFGを高くすると多様性が減少し、何回実行しても同じ画像が出力されるようになります。
輪郭強調 : Rescaled Phi
Stable Diffusionでよく使われるCFGほどは頻繁に見かけることはありませんが、こちらも見た目を大きく制御することのできる変数です。本来、ノイズを除去する速度を調整し、生成を安定させるために使われる変数ですが、数値が大きいほど輪郭が強調されるという特徴を持っています。Denoising Diffusion Pytorch [16]にて具体的な実装が紹介されています。

映像解説
映像前半 : Rescaled Phi = -10
輪郭がボヤけ、色数が減少した水彩画のような仕上がりになっています。
映像後半 : Rescaled Phi = 10
輪郭が強調されすぎてノイズが発生し、花の形も崩れています。
スタイル適用 : DDIM Inversion
任意の画像に対して、条件通りのスタイルを適用できる手法です。
Diffusionモデルは、序盤の生成で画像全体の特徴を生成し、後半で画像の細部を生成するという特徴があり、本手法はこれをもとに独自に考案したものです。実装後に調べたところDDIM Inversionという手法がこれに近く、Diffusion Model Class [17]でも紹介されていました。
スタイルが適応される入力画像はノイズの入った画像である必要があり、これはDiffusionモデルの生成を途中で中断するか、任意の画像にノイズを加えることで作成することができます。
そして、入力画像をDiffusionモデルを使って完全にノイズがなくなるまで生成を進めると、ノイズで失われた細部を与えた条件をもとに推測した画像ができ上がります。
入力画像のノイズが少なければ、画像の細部の特徴のみが条件に沿ったものになります。一方で、ノイズが多ければ、画像全体の特徴も推測するため条件で指定した特徴が強く現れ、純粋なノイズを与えると入力画像の特徴を持たない、完全に条件で指定した通りの画像になります。
ノイズの量を0から1に変化させることで、入力画像と条件に基づいた生成画像の2つの画像の間をスムーズに補完することもできます。
この補完手法の場合、条件ベクトルを補完する手法と比べて、曖昧な条件ベクトルを持たないクラス条件付けと相性がよく、補完中に意図しない画像が生成されてしまうことも防ぐことができます。

映像解説
与えた条件
条件1 : Oxford102のクラス定義の順番。丸い花が先頭。
条件2 : 条件1を左にスライド。トゲトゲの花が先頭。
映像前半 : DDIM Inversion Step = 10
条件1で生成後すぐ、条件2に切り替えて生成をしたもので、条件1の特徴はほとんど現れておらず、条件2の特徴に強く従っています。
条件1が、画像全体の特徴を強く指定しないので、条件2が画像全体の特徴を推定する必要があり、生成が安定していません。
映像中間 : DDIM Inversion Step = 128
条件1で128 stepまで生成し、条件2に切り替えて残りの128 stepを生成したものです。画像全体の特徴として条件1に従っていますが、画像の色味や細部の特徴は条件2に従っていることが分かります。
映像後半: DDIM Inversion Step = 240
条件1で240 stepまで生成し、条件2に切り替えて残りの10 stepを生成したものです。条件2の特徴はほとんどなく、条件1に強く従っています。
条件1でほぼ全体の特徴が復元されているので、条件2では解釈の余地が少なく、生成は安定しています。
最後に
今回は、Diffusionモデルを支える技術とその応用について紹介しました。
Diffusionモデルは、生成精度と生成速度ともに発表当時と比べて大きな進歩を遂げてきました。全ての技術を完全に理解するのは困難ですが、以下のリソースや記事の最後に記載された、動作確認済みの実装をまとめた補足資料を頼りに、理解を深めることができます。
書籍 : ゼロから始めるDeep Learning 5 [18] (生成モデル編)
ライブラリ : Hugging Face Diffuser [19]
実装 :
minDiffusion [20] (200行以下で記述)
Denosing Diffusion Pytorch [14] (条件付き生成可能)
Stable Diffusionのソースコードは公開されており、世界中でより良い生成技術が絶えず研究開発されています。Diffusionモデルの仕組みを理解することで、これから登場する最先端の生成手法をいち早く習得できるようになるのではないでしょうか。
参考文献
Diffusionモデル | https://arxiv.org/pdf/2006.11239
Classifier Free Guidance (CFG) | https://arxiv.org/pdf/2207.12598
Stable Diffusion | https://github.com/Stability-AI/stablediffusion
Vision Transformer (ViT) | https://arxiv.org/pdf/2010.11929
Latent Diffusion | https://arxiv.org/pdf/2112.10752
The Annotated Diffusion Model | https://huggingface.co/blog/annotated-diffusion
Attention機構 | https://arxiv.org/pdf/1706.03762
Linear Attention | https://arxiv.org/pdf/1812.01243
VAE図解 | https://towardsdatascience.com/understanding-variational-autoencoders-vaes-f70510919f73
Oxford102データセット | https://www.robots.ox.ac.uk/~vgg/data/flowers/102/
nn.Embedding | https://pytorch.org/docs/stable/generated/torch.nn.Embedding.html
Denoising Diffusion Pytorch | https://github.com/lucidrains/denoising-diffusion-pytorch
Diffusion Model Class | https://github.com/huggingface/diffusion-models-class/blob/main/unit4/01_ddim_inversion.ipynb
ゼロから始めるDeep Learning 5 | https://www.oreilly.co.jp//books/9784814400591/
Hugging Face Diffuser | https://huggingface.co/docs/diffusers/en/index
minDiffusion | https://github.com/cloneofsimo/minDiffusion
補足資料
本モデルの開発時に参考にした、動作確認済みの実装です。
Harvard, Diffusionモデルを”解体”しながら、ゼロから学ぶ | Understanding Stable Diffusion from “Scratch”
GAN、 Diffusionモデルをベースにした複数生成モデルの簡潔な実装。Logを比較して各モデルの特徴が分かる | Lightning Generative Models
PyTorchをより簡潔に記述できるLightningを使った生成モデルの実装 | PyTorch Lightning Basic GAN Tutorial
コードを通したViTの解説記事 | Vision Transformers explained through Code
Diffuserを使った、Stable Diffusionの学習 | diffusers/examples
高速な生成が特徴のGANの中でも高精度なモデル | Stylegan 2 Ada Pytorch
Flaxを使ってより簡潔に記述されたDenoising Diffusion Pytorch | Denoising Diffusion Flax
2024/09/26:記載の一部に誤りがあったため訂正
この記事が気に入ったらサポートをしてみませんか?