
COCOデータセットを可視化してみた

はじめに
初めまして。
ギリアでインターン生としてデータ開発を行っている鍛原と申します。普段から様々なデータの可視化や分析を行っています。
本稿では、画像認識で広く用いられているCOCOデータセットとはどんなものか、統計情報とともに紹介します。
また、COCOデータセットを正しく使えるように、使い方やデータ構造、画像の特徴などを出来るだけ詳細にまとめました。
ぜひ、最後までお付き合いください。
1. COCOデータセットとは
様々な画像認識の研究や開発で利用されており、とても人気のあるデータセットです。
このデータセットは主に、以下のようなタスクで利用されます。
画像分類 (Image Classification)
物体検出 (Object Detection)
セマンティックセグメンテーション (Semantic Segmentation)
インスタンスセグメンテーション (Instance Segmentation)
キャプション生成 (Caption Generation)
姿勢推定 (Pose Estimation)
このデータセットは、こちらのサイトからダウンロードできます。
https://cocodataset.org/#download
注意:データセットが直接ダウンロードできない場合、wgetやcurlでダウンロードしましょう。
データセットの構成(2017年度のデータ)
train2017: 学習用の画像(11万8287件)
val2017: バリデーション用の画像(5000件)
annotations_trainval2017: アノテーションデータ
*.json: アノテーション情報
アノテーション情報は、以下のようなjsonから構成されます。
captions_train2017.json: キャプション生成用のアノテーション情報 (学習用)
captions_val2017.json: キャプション生成用のアノテーション情報 (バリデーション用)
instances_train2017.json: 物体検出、セグメンテーション用のアノテーション情報 (学習用)
instances_val2017.json: 物体検出、セグメンテーション用のアノテーション情報 (バリデーション用)
person_keypoints_train2017.json: 姿勢推定用のアノテーション情報 (学習用)
person_keypoints_val2017.json: 姿勢推定用のアノテーション情報 (バリデーション用)
2. アノテーションデータの構造
全体構造
アノテーションデータは、COCOフォーマットに準拠して作成されています。
このフォーマットは次のような構造になっています。
# アノテーションデータ
{
"info": {...},
"licenses": [
{...},{...}
],
"images": [
{...},{...},{...},{...}
],
"annotations": [
{...},{...},{...},{...},{...},{...},{...},{...},{...}
],
"categories": [
{...},{...},{...}
]
}アノテーションデータの各要素を表にまとめました。

annotationsの構造
タスクごとのannotationsの構造を示します。
# キャプション生成用のアノテーション情報
{'caption': 'A laptop has been placed next to a computer monitor showing data.',
'id': 203564,
'image_id': 549759}
# 物体検出、セグメンテーション用のアノテーション情報
{'area': 7250.8301999999985,
'bbox': [537.3, 187.57, 57.29, 187.02],
'category_id': 1,
'id': 203564,
'image_id': 398285,
'iscrowd': 0,
'segmentation': [[...]]}
# 姿勢推定用のアノテーション情報
{'area': 7250.8302,
'bbox': [537.3, 187.57, 57.29, 187.02],
'category_id': 1,
'id': 203564,
'image_id': 398285,
'iscrowd': 0,
'keypoints': [...]}それぞれの要素を表にまとめました。

categoriesの構造
この2種類のタスクのみ情報があります。
物体検出、セグメンテーション用のアノテーション情報
91種類のカテゴリが定義されている。
姿勢推定用のアノテーション情報
カテゴリは"person"のみが定義されている。
# 物体検出、セグメンテーション用のアノテーション情報
[{'supercategory': 'person', 'id': 1, 'name': 'person'},
{'supercategory': 'vehicle', 'id': 2, 'name': 'bicycle'},
{'supercategory': 'vehicle', 'id': 3, 'name': 'car'},
...]
# 姿勢推定用のアノテーション情報
{
"supercategory": "person",
"id": 1,
"name": "person",
"keypoints": [
"nose","left_eye","right_eye","left_ear","right_ear", "left_shoulder","right_shoulder",
"left_elbow","right_elbow","left_wrist","right_wrist", "left_hip","right_hip",
"left_knee","right_knee","left_ankle","right_ankle"
],
"skeleton": [
[16,14],[14,12],[17,15],[15,13],[12,13],[6,12],[7,13],[6,7],
[6,8],[7,9],[8,10],[9,11],[2,3],[1,2],[1,3],[2,4],[3,5],[4,6],[5,7]
]
}
それぞれの要素を表にまとめました。

3. COCO APIの詳細
COCO APIは、JSON形式であるアノテーションデータをpythonで操作する際に便利なAPIです。
このAPIはこちらから入手できます。
https://github.com/cocodataset/cocoapi
APIの種類を表にまとめました。

実際にAPIを用いてアノテーションデータを可視化した例を示します。
3種類のアノテーション情報をそれぞれ次のように使用して画像上に描画してみました。
キャプション生成用のアノテーション情報
キャプションは画像の上に記載している。
物体検出用のアノテーション情報
それぞれの物体を線で囲んでいる。
姿勢推定用のアノテーション情報
人間の関節部分を点で結んでいる。

Kitchen Ⓒ Maggie Stephens 2011
License: https://creativecommons.org/licenses/by/2.0/
上記のアノテーションを行なったコードはこちらになります。
# COCOオブジェクトの作成
from pycocotools.coco import COCO
# キャプション生成用のアノテーション情報
anno_path = "data/annotations/captions_val2017.json"
coco_cap = COCO(anno_path)
# 物体検出用のアノテーション情報
anno_path = "data/annotations/instances_val2017.json"
coco_ins = COCO(anno_path)
# 姿勢推定用のアノテーション情報
anno_path = "data/annotations/person_keypoints_val2017.json"
coco_key = COCO(anno_path)
# アノテーション情報の可視化
import matplotlib.pyplot as plt
# 指定した画像 ID に対応する画像の情報を取得する。
img_id = coco_cap.getImgIds()[0]
img_info = coco_cap.loadImgs(img_id)
img_path = f"data/val2017/{img_info[0]['file_name']}"
# 指定した画像IDに対応するアノテーションIDを取得する。
anno_ids_cap = coco_cap.getAnnIds(img_id)
anno_ids_ins = coco_ins.getAnnIds(img_id)
anno_ids_key = coco_key.getAnnIds(img_id)
# 指定したアノテーション ID に対応するアノテーションの情報を取得する。
annos_cap = coco_cap.loadAnns(anno_ids_cap)
annos_ins = coco_ins.loadAnns(anno_ids_ins)
annos_key = coco_key.loadAnns(anno_ids_key)
# 画像とアノテーション結果の描写
img = plt.imread(img_path)
plt.imshow(img)
coco_cap.showAnns(annos_cap)
coco_ins.showAnns(annos_ins)
coco_key.showAnns(annos_key)4. COCOデータセットの画像分析
ここでは、COCOデータセットのアノテーション情報を基に、画像内に含まれる物体の分析を行い、COCOデータセットの特徴を把握してみようと思います。
分析方法
物体検出、セグメンテーション用のアノテーション情報を用いて以下の分析を行います。
画像のカテゴリ割合の比較
カテゴリごとの画像数を可視化し、どのようなカテゴリの物体が写る画像の割合が多いのか比較します。
画像の物体サイズの比較
画像に写る物体のサイズをカテゴリごとに可視化し、どの物体が大きく写る傾向にあるのかを分析します。
画像のカテゴリ割合の比較
次の2種類の比較を行いました。
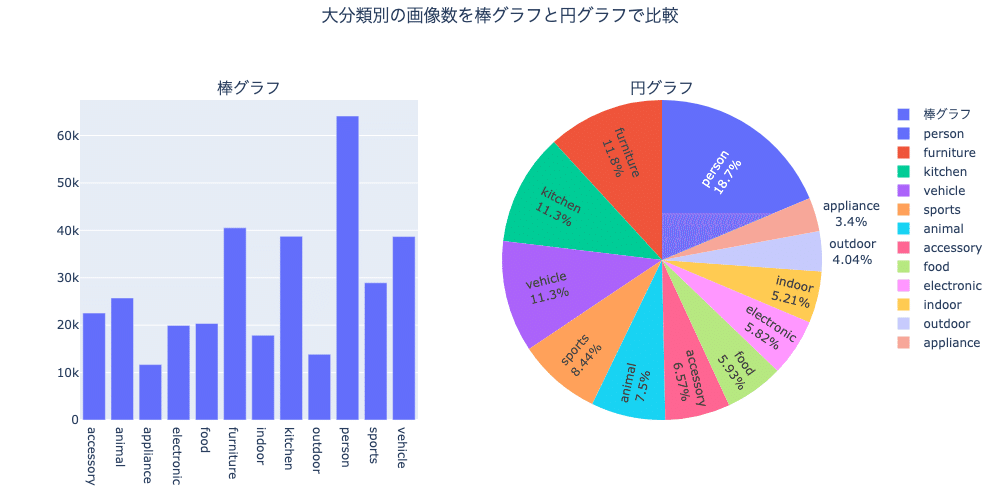
①大分類別の画像の枚数を算出し、棒グラフと円グラフを使って比較する。
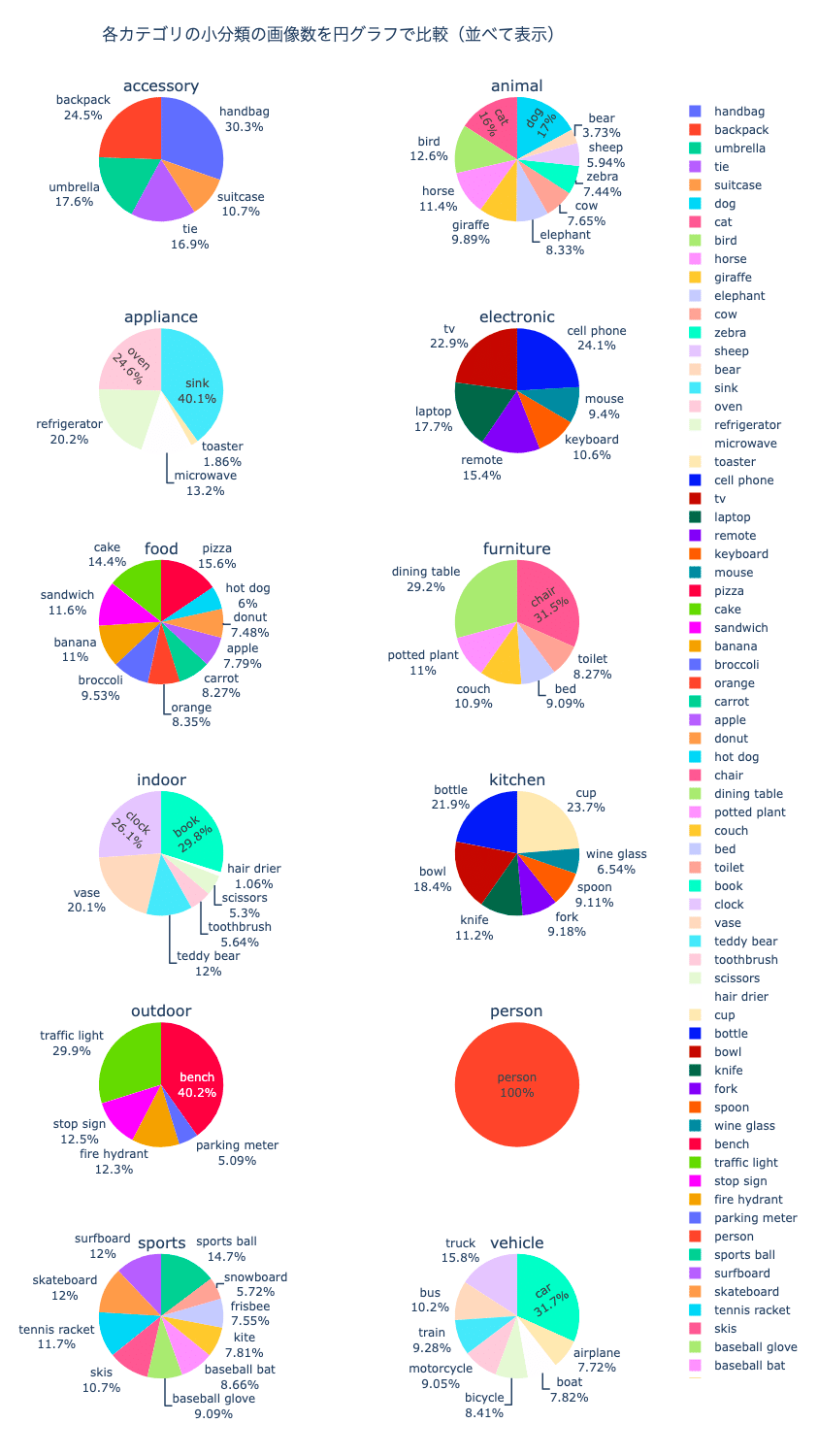
②小分類別の画像の枚数を算出し、円グラフを使って比較する。
①大分類別の画像の枚数を算出し、棒グラフと円グラフを使って比較する
結果:
データセット内には、このような比率で大分類の物体が含まれています。
このグラフから、特に人が多く含まれていることがわかります。
②小分類別の画像の枚数を算出し、円グラフを使って比較する
結果:
各カテゴリでどの小分類が特に多くの割合を占めているのかが見えてきました。
例えば、乗り物(vehicle)に分類される物体では、特に車(car)が多いことがグラフからわかります。
画像の物体サイズの比較
物体検出、セグメンテーション用のアノテーション情報に含まれる各物体のピクセル数を元に、各カテゴリにどの程度ピクセル数を使用しているのかを算出し、可視化することで、各物体の大小を比較してみます。
事前確認
ピクセル数の記述統計量を見てみると、外れ値が大きいことが分かりました。
特に、標準偏差が大きいため、分布の偏りが大きいと言えます。

このことから、単純にピクセル数の平均で比較するのは良くないと考え、外れ値を考慮した比較が可能になるよう箱ひげ図を用いて比較してみます。
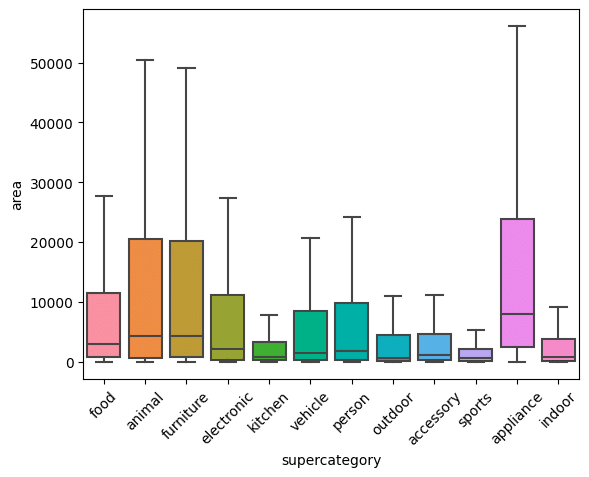
大分類ごとの比較
各大分類に属する物体の大きさを比較することができるようになりました。
このグラフからは、特に大きく写ったのは、animal(動物)、furniture(家具)、appliance(家電)であると言えます。
確かに、動物は単体の写真がズームで撮られることが多いので、値が大きくなる傾向にあると言えるかもしれません。
また、家具はそもそも大きいサイズの物(寝具や机)が多いので、ピクセル数が多くなりやすいと言えます。
家電も大きいサイズの物(冷蔵庫やシンク)が多いものの、トースターなどの小さいサイズの物もあるため、対象となる物体の種類が多く振れ幅が大きくなっているのだと推測できます。
小分類ごとの比較
大分類内で、各小分類の物体の大きさを比較することができるようになりました。
グラフから、vehicle(乗り物)では、train(電車)やbus(バス)が大きく写る一方で、car(車)やbicycle(自転車)、boat(ボート)は小さく写っていることが分かります。
電車やバスが大きく写る傾向にあるのは、それ単体で撮られることが多いからと考えられます。
車や自転車が小さく写る傾向にあるのは、街中を走っている光景の中に小さく写り込んでいることが多いためであると考えられます。
また、ボートも同様に水面に浮かぶ光景を遠くから撮影するためであると考えられます。

終わりに
今回は、画像認識の分野で広く用いられているCOCOデータセットについて紹介しました。
前半では、データセットの概要や、構造、使い方などについてお伝えしました。
後半では、データセット内の画像に写る物体の分布や特徴を、アノテーションデータを用いて可視化し分析してみました。
COCOデータセットを扱う際に、本稿が参考になれば幸いです。
この記事が気に入ったらサポートをしてみませんか?